MapReduce的初识
MapReduce是什么
HDFS:分布式存储系统
MapReduce:分布式计算系统
YARN:hadoop 的资源调度系统
Common:以上三大组件的底层支撑组件,主要提供基础工具包和 RPC 框架等
MapReduce 是一个分布式运算程序的编程框架,是用户开发“基于 Hadoop 的数据分析应用” 的核心框架
MapReduce 核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布 式运算程序,并发运行在一个 Hadoop 集群上
为什么需要 MapReduce
1、海量数据在单机上处理因为硬件资源限制,无法胜任
2、而一旦将单机版程序扩展到集群来分布式运行,将极大增加程序的复杂度和开发难度
3、引入 MapReduce 框架后,开发人员可以将绝大部分工作集中在业务逻辑的开发上,而将 分布式计算中的复杂性交由框架来处理
设想一个海量数据场景下的数据计算需求:
| 单机版:磁盘受限,内存受限,计算能力受限 |
|
分布式版: 1、 数据存储的问题,hadoop 提供了 hdfs 解决了数据存储这个问题 2、 运算逻辑至少要分为两个阶段,先并发计算(map),然后汇总(reduce)结果 3、 这两个阶段的计算如何启动?如何协调? 4、 运算程序到底怎么执行?数据找程序还是程序找数据? 5、 如何分配两个阶段的多个运算任务? 6、 如何管理任务的执行过程中间状态,如何容错? 7、 如何监控? 8、 出错如何处理?抛异常?重试? |
可见在程序由单机版扩成分布式版时,会引入大量的复杂工作。为了提高开发效率,可以将 分布式程序中的公共功能封装成框架,让开发人员可以将精力集中于业务逻辑。
Hadoop 当中的 MapReduce 就是这样的一个分布式程序运算框架,它把大量分布式程序都会 涉及的到的内容都封装进了,让用户只用专注自己的业务逻辑代码的开发。它对应以上问题 的整体结构如下:
MRAppMaster:MapReduce Application Master,分配任务,协调任务的运行
MapTask:阶段并发任,负责 mapper 阶段的任务处理 YARNChild
ReduceTask:阶段汇总任务,负责 reducer 阶段的任务处理 YARNChild
MapReduce做什么
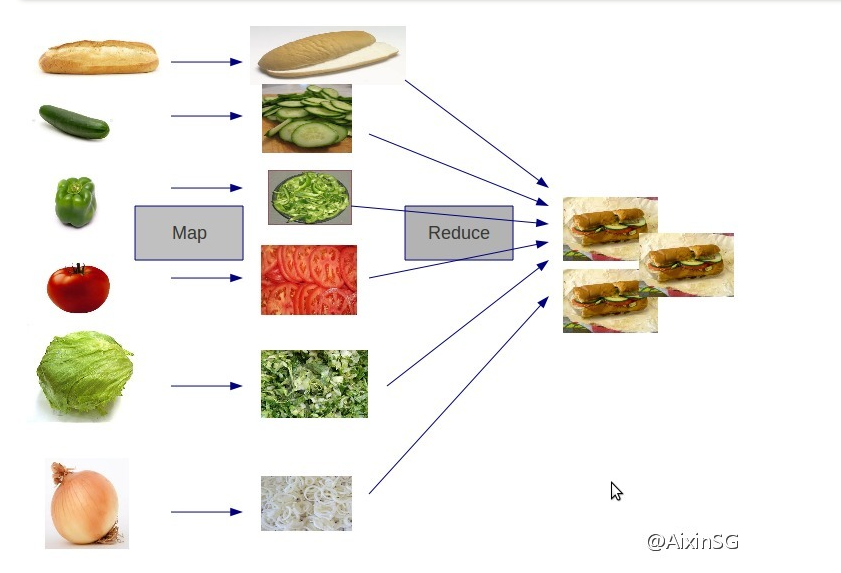
简单地讲,MapReduce可以做大数据处理。所谓大数据处理,即以价值为导向,对大数据加工、挖掘和优化等各种处理。
MapReduce擅长处理大数据,它为什么具有这种能力呢?这可由MapReduce的设计思想发觉。MapReduce的思想就是“分而治之”。
(1)Mapper负责“分”,即把复杂的任务分解为若干个“简单的任务”来处理。“简单的任务”包含三层含义:一是数据或计算的规模相对原任务要大大缩小;二是就近计算原则,即任务会分配到存放着所需数据的节点上进行计算;三是这些小任务可以并行计算,彼此间几乎没有依赖关系。
(2)Reducer负责对map阶段的结果进行汇总。至于需要多少个Reducer,用户可以根据具体问题,通过在mapred-site.xml配置文件里设置参数mapred.reduce.tasks的值,缺省值为1。
MapReduce 程序编写规范
1、用户编写的程序分成三个部分:Mapper,Reducer,Driver(提交运行 MR 程序的客户端)
2、Mapper 的输入数据是 KV 对的形式(KV 的类型可自定义)
3、Mapper 的输出数据是 KV 对的形式(KV 的类型可自定义)
4、Mapper 中的业务逻辑写在 map()方法中
5、map()方法(maptask 进程)对每一个<k,v>调用一次
6、Reducer 的输入数据类型对应 Mapper 的输出数据类型,也是 KV 对的形式
7、Reducer 的业务逻辑写在 reduce()方法中
8、Reducetask 进程对每一组相同 k 的<k,v>组调用一次 reduce()方法
9、用户自定义的 Mapper 和 Reducer 都要继承各自的父类
10、整个程序需要一个 Drvier 来进行提交,提交的是一个描述了各种必要信息的 job 对象
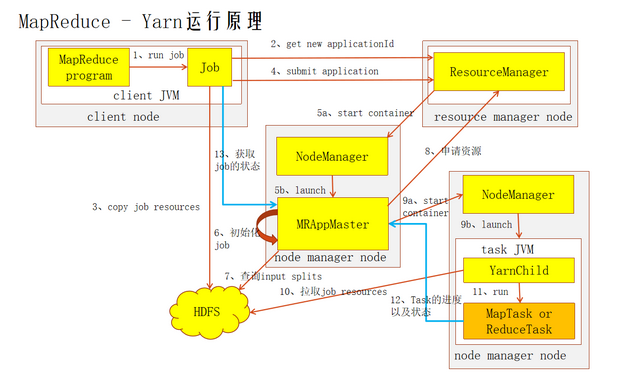
1:job的提交
inputSplit
1. Block
块是以 block size 进行划分数据。 因此,如果群集中的 block size 为 128 MB,则数据集的每个块将为128 MB,除非最后一个块小于block size(文件大小不能被 block size 完全整除)。例如下图中文件大小为513MB,513%128=1,最后一个块(e)小于block size,大小为1MB。 因此,块是以 block size的硬切割,并且块甚至可以在逻辑记录结束之前结束(blocks can end even before a logical recordends)。假设我们的集群中block size 是128 MB,每个逻辑记录大约100 MB(假设为巨大的记录)。所以第一个记录将完全在一个块中,因为记录大小为100 MB小于块大小128 MB。但是,第二个记录不能完全在一个块中,因此第二条记录将出现在两个块中,从块1开始,在块2中结束。
2. InputSplit
如果分配一个Mapper给块1,在这种情况下,Mapper不能处理第二条记录,因为块1中没有完整第二条记录。因为HDFS不知道文件块中的内容,它不知道记录会什么时候可能溢出到另一个块(becauseHDFS has no conception of what’s inside the fifile blocks, it can’t gauge when a record mightspill over into another block)。InputSplit这是解决这种跨越块边界的那些记录问题,Hadoop使用逻辑表示存储在文件块中的数据,称为输入拆分(InputSplit)。当MapReduce作业客户端计算InputSplit时,它会计算出块中第一个完整记录的开始位置和最后一个记录的结束位置。在最后一个记录不完整的情况下,InputSplit 包括下一个块的位置信息和完成该记录所需的数据的字节偏移(In cases where the last record in a block is incomplete, the input splitincludes location information for the next block and the byte offffset of the data needed tocomplete the record)。下图显示了数据块和InputSplit之间的关系:块是磁盘中的数据存储的物理块,其中InputSplit不是物理数据块。 它是一个Java类,指向块中的开始和结束位置。 因此,当Mapper尝试读取数据时,它清楚地知道从何处开始读取以及在哪里停止读取。InputSplit的开始位置可以在块中开始,在另一个块中结束。InputSplit代表了逻辑记录边界,在MapReduce执行期间,Hadoop扫描块并创建InputSplits,并且每个InputSplit将被分配给一个Mapper进行处理。
什么是combiner
在Hadoop中,有一种处理过程叫Combiner,与Mapper和Reducer在处于同等地位,但其执行的时间介于Mapper和Reducer之间,其实就是Mapper和Reducer的中间处理过程,Mapper的输出是Combiner的输入,Combiner的输出是Reducer的输入。例如获取历年的最高温度例子,以书中所说的1950年为例,在两个不同分区上的Mapper计算获得的结
果分别如下:
第一个Mapper结果:(1950, [0, 10, 20])
第二个Mapper结果:(1950, [25, 15])
如果不考虑Combiner,按照正常思路,这两个Mapper的结果将直接输入到Reducer中处理,如下所示:MaxTemperature:(1950, [0, 10, 20, 25, 15])最终获取的结果是25。
如果考虑Combiner,按照正常思路,这两个Mapper的结果将分别输入到两个不同的Combiner中处理,获得的结果分别如下所示:第一个Combiner结果:(1950, [20])第二个Combiner结果:(1950, [25])然后这两个Combiner的结果会输出到Reducer中处理,如下所示MaxTemperature:(1950, [20, 25])最终获取的结果是25。
由上可知:这两种方法的结果是一致的,使用Combiner最大的好处是节省网络传输的数据,这对于提高整体的效率是非常有帮助的。
但是,并非任何时候都可以使用Combiner处理机制,例如不是求历年的最高温度,而是求平均温度,则会有另一种结果。同样,过程如下,
如果不考虑Combiner,按照正常思路,这两个Mapper的结果将直接输入到Reducer中处理,如下所示:
AvgTemperature:(1950, [0, 10, 20, 25, 15])
最终获取的结果是14。
如果考虑Combiner,按照正常思路,这两个Mapper的结果将分别输入到两个不同的Combiner中处理,获得的结果分别如下所示:
第一个Combiner结果:(1950, [10])
第二个Combiner结果:(1950, [20])
然后这两个Combiner的结果会输出到Reducer中处理,如下所示
AvgTemperature:(1950, [10, 20])
最终获取的结果是15。
由上可知:这两种方法的结果是不一致的,所以在使用Combiner时,一定三思而后行,仔细思量其是否适合,否则可能造成不必要的麻烦。
MapReduce的初识的更多相关文章
- Hadoop学习之路(十三)MapReduce的初识
MapReduce是什么 首先让我们来重温一下 hadoop 的四大组件: HDFS:分布式存储系统 MapReduce:分布式计算系统 YARN:hadoop 的资源调度系统 Common:以上三大 ...
- Hadoop学习笔记—4.初识MapReduce
一.神马是高大上的MapReduce MapReduce是Google的一项重要技术,它首先是一个编程模型,用以进行大数据量的计算.对于大数据量的计算,通常采用的处理手法就是并行计算.但对许多开发者来 ...
- Hadoop和MapReduce初识
我们生活在大数据时代!!!微博.微信.云存储等大数据的需求,Hadoop由此诞生. 以下面部分数据为例: 1)Facebook存储着约100亿张照片,约1PB存储容量: 2)纽约证券交易所每天产生1T ...
- 初识分布式计算:从MapReduce到Yarn&Fuxi
这些年,云计算.大数据的发展如火如荼,从早期的以MapReduce为代表的基于文件系统的离线数据计算,到以Spark为代表的内存计算,以及以Storm为代表的实时计算,还有图计算等等.只要数据规模 ...
- 初识MapReduce
MapReduce是Google的一项重要技术,它首先是一个编程模型,用以进行大数据量的计算.对于大数据量的计算,通常采用的处理手法就是并行计算.但对许多开发者来说,自己完完全全实现一个并行计算程序难 ...
- Hadoop点滴-初识MapReduce(2)
术语: job(作业):客户端需要执行的一个工作单元,包括输入数据.MP程序.配置信息 Hadoop将job分成若干task(任务)来执行,其中包括两类任务:map任务.reduce任务.这些任务在集 ...
- Hadoop点滴-初识MapReduce(1)
分析气候数据,计算出每年全球最高气温(P25页) Map阶段:输入碎片数据,输出一系列“单键单值”键值对 内部处理,将一系列“单键单值”键值对转化成一系列“单键多值”键值对 Reduce阶段,输入“单 ...
- 初识Hadoop
第一部分: 初识Hadoop 一. 谁说大象不能跳舞 业务数据越来越多,用关系型数据库来存储和处理数据越来越感觉吃力,一个查询或者一个导出,要执行很长 ...
- MongoDB【第一篇】MongodDB初识
NoSQL介绍 一.NoSQL简介 NoSQL,全称是”Not Only Sql”,指的是非关系型的数据库. 非关系型数据库主要有这些特点:非关系型的.分布式的.开源的.水平可扩展的. 原始的目的是为 ...
随机推荐
- 升级最新版Rancher 2.2.6
前言:之前采用离线方式部署好了 Rancher 2.2.4(https://www.cnblogs.com/weavepub/p/11053099.html),这次升级到最新版本 Rancher 2. ...
- CentOS 6.x安装php 5.6和redis扩展的全过程
安装PHP 5.6 #yum clean all #yum update 整体升级一下yum包 #yum install -y epel-release #yum list installed | g ...
- .Net Core2.2 在IIS发布
.Net Core应用发布到IIS主要是如下的三个步骤: (1)在Windows Server上安装 .Net Core Hosting Bundle (2)在IIS管理器中创建IIS站点 (3)部署 ...
- Django--母版
目录 母版 语法 案例 在之前的两个小程序中,可以发现在写html页面的时候有很多重复的代码 而在python中,为了避免写重复代码,我们通过函数.模块或者类来进行实现,所以在Django里面也有这样 ...
- C#将异常信息添加到日志
C#将程序抛出的异常信息添加到错误日志 错误日志是软件用来记录运行时出错信息的文本文件.编程人员和维护人员等可以利用错误日志对系统进行调试和维护. 为程序添加错误日志的好处是当程序有运行错误时,根据错 ...
- Linux命令:scp
1.find命令: scp [参数] [原路径] [目标路径] 2.用法: scp是 secure copy的缩写, scp是linux系统下基于ssh登陆进行安全的远程文件拷贝命令.linux的sc ...
- Servlet HttpServletResponse对象、HttpServletRequest对象
HttpServletResponse对象(response)的常用方法 setCharacterEncoding("utf-8") //设置响应的编码字符集 setCont ...
- 推荐一些github上的免费好书
本文转载自公众号:跟着小一写bug. 熬夜等于慢性自杀,那熬夜和喜欢的人说话,算不算是慢性殉情? 晚上好 小一来啦 有木有想哀家 其实今晚小一有个拳击课 可是 由于项目明天要演示 调一 ...
- MyBatis面试题整理
MyBatis面试题整理 1.什么是MyBatis? 答:MyBatis是一个可以自定义SQL.存储过程和高级映射的持久层框架. 2.讲下MyBatis的缓存 答:MyBatis的缓存分为一级缓存和二 ...
- linux服务器问题排查:w命令卡住
基本情况 系统: ubuntu16.04 症状: who命令可以用,w命令用不了 sudo iotop命令会卡住,黑屏 nvidia-smi命令和nvl命令都用不了,卡住 排查步骤 strace ps ...