day25 内置常用模块(四): 模块和包
阅读目录:
模块
import
from xxx import xxx
包
import
from xxx import xxx
- from xxx import *
__init__.py文件
绝对导入和相对导入
单独导入包
模块
什么是模块?
常见的场景:一个模块就是一个包含了python定义和声明的文件,文件名就是模块名字加上.py的后缀。
但其实import加载的模块分为四个通用类别:
1 使用python编写的代码(.py文件)
2 已被编译为共享库或DLL的C或C++扩展
3 包好一组模块的包
4 使用C编写并链接到python解释器的内置模块
为什么要使用模块?
为了我们写的代码可以重⽤,不至于把所有的代码都写在一个文件内. 当项目规模比较小的时候,完全可以使用一个py文件搞定整个项⽬的开发,但是如果是一个⾮常庞⼤的项目,此时就必须要把相关的功能进⾏分离,方便我们的日常维护以及新项目的开发.
如何使用模块?
导入模块有两种⽅式
1. import 模块名
2. from xxx import xxxx
import 模块名
main_person_man = "张无忌"
main_person_woman = "赵敏" bad_person_one = "成昆"
bad_person_two = "周芷若" def fight_on_light_top():
print(f"{main_person_man} 粉碎了 {bad_person_one} 的阴谋诡计") def fight_on_shaolin():
print(f"{main_person_man} 击败了 {bad_person_two}" ) def end():
print(f"{main_person_man}和{main_person_woman}过上了没羞没臊的幸福生活") def gai():
global main_person_man # global 当前模块的全局(只能 在当前模块中引入并修改当前模块中的变量的值)
main_person_man = "舒克和贝塔" # print(__name__)
# __main__ 当前文件是启动文件的时候显示的名字,-->主程序
# yitian 当前文件是作为引入模块的时候,在其他文件中显示的名字
"""
在Python中,每个模块都有⾃己的__name__ ,但是这个__name__的值是不定的. 当我们把一个模块作为程序运⾏的入口时,此时该模块的__name__是"__main__" , ⽽如果我们把模块导入时,此时模块内部的__name__就是该模块⾃身的名字.
""" if __name__ == '__main__': # 只有当前文件是启动文件的时候才会执行
print('我是片头曲:啊啊啊啊啊啊...')
fight_on_shaolin()
fight_on_top()
end()
print('我是片尾曲:哦哦哦哦哦哦哦...')
创建yitian.py文件
import yitian # # pycharm报错(#因为pycharm的搜索路径是没有sys.path的第一个),但是并不影响程序的执行(执行是没有报错的),解决办法是将当前文件所在目录变成文件的搜索路径(将当前文件所在文件夹在新窗口中打开即可.) 导入模块的时候,我们看到的直观效果是:把模块中的代码执行了一遍.
import yitian as yt # # 给模块重命名,类似于变量赋值,需要特别强调的一点是:python中的变量赋值不是一种存储操作,而只是一种绑定(指向)关系. # 模块的搜索路径. sys.path
import sys
print(sys.path) # 前两个分别是当前文件所在文件夹和项目所在文件夹
import yitian # 如果已经导入过该模块. 此时不会再执行模块中的代码了(根据sys.modules, sys.modules是一个字典,内部包含模块名与模块对象的映射,该字典决定了导入模块时是否需要重新导入。(#sys.modules.keys()会以列表的形式显示导入过的模块名,包括自动加载的内置模块)) # 没有使用as对引入模块改名的时候,直接使用引入的模块名调用属性
print(yitian.main_person_man)
print(yitian.main_person_woman) # 使用as对引入模块改名之后,只能使用改过之后的名字,使用原来的模块名字会报错
print(yt.main_person_man)
print(yt.main_person_woman)
yt.fight_on_top()
yt.fight_on_shaolin() # 要改变引入模块中的变量名的唯一方法
yt.main_person_man = '宝宝' # 当前模块改变引入模块变量的唯一方法
print(yt.main_person_man) # 输出结果是 '宝宝'
yt.fight_on_top()
yt.fight_on_shaolin() def gai():
global main_person_man # global的作用范围是当前模块的全局
main_person_man = '宝宝' # 在自己的名称空间创建了 同名变量 main_person_man = '宝宝'
yt.fight_on_top()
yt.fight_on_shaolin() gai() # 通过当前模块中使用global并不能改变引入模块的变量
print(yt.main_person_man) # 输出结果是 '张无忌'
yt.fight_on_shaolin() # 同时引入多个模块的顺序:1.内置 2.第三方 3.自定义
import yitian as yt, shediao as sd, time, os, sys,json, re # 错误的顺序
sd.huashanlunjian()
yt.fight_on_shaolin() # 使用from...import..导入同名的属性,后面的会将前面的覆盖掉
from yitian import fight_on_shaolin
from shediao import fight_on_shaolin main_person_man = "火工头陀"
fight_on_shaolin()
# 自己模块中新定义的属性(变量或方法)与引入模块的属性重名,也会将引入的覆盖掉
def fight_on_shaolin():
print("我要干少林") fight_on_shaolin() # 调用的是自己模块中的方法,输出 '我要干少林' from shediao import * # 也可以导入一大堆名字. 不推荐
创建jinyong.py文件
导入模块的时候都做了什么?
导入模块时候系统的执行流程:
1. 去判断当前正在导入的模块是否已经导入过(根据sys.modules)
2. 如果已经导入过,不会重新导入该模块
4. 把该模块中的代码放在新开辟的空间中. 运行该模块中的代码(#和你写一个类的加载过程差不多)
5. 把该文件的名字作为当前名称空间的名字(前提是没有as)
模块可以包含可执行的语句和函数的定义,这些语句的目的是初始化模块,它们只在模块名第一次遇到导入语句import时才执行(import语句是可以在程序中的任意位置使用的,且针对同一个模块import很多次,为了防止你重复导入,python的优化手段是:第一次导入后就将模块名加载到内存了,后续的import语句仅是对已经加载到内存中的模块对象增加了一次引用,不会重新执行模块内的语句).
改变引入模块中变量的唯一方法
注意:这里只是改变了 在当前模块中的引入模块(引入模块在当前模块所开辟名称空间)的值,并不会改变引入模块在自己原始名称空间中的值.(我认为:引入模块相当于复制了一份名称空间,而不是指向!)
yt.main_person_man = "宝宝"
从当前模块中(即引入模块的外部)改变引入模块中变量的值的唯一方法是 引入模块名.变量名 = 新值(使用赋值的方式),而global指向的是当前模块的内部,并不会改变外部模块的内容(只会在当前模块的名称空间中创建一个同名的属性).
特别特别要注意. 如果我们在不同的模块中引入了同一个模块,并且在某一个模块中改变了被引入模块中的全局变量,则其他模块看到的值也跟着变. 原因是python的模块只会引入一次,大家共享同一个名称空间.
实例:
在不同的模块中引入了同一个模块(比如以下代码中的jinyong.py和jinyong2.py模块中引入了同一个模块yitian.py),
并且在某一个模块中改变了被引入模块中的全局变量(比如在jinyong.py模块中将yitian.py模块中的全局变量main_person_man改变成了'宝宝'),
则其他模块看到的值也跟着变(比如jinyong2.py模块中看到的name的值也跟着变成了'宝宝'),原因是Python的模块只会引入一次,大家共享同一个名称空间.
(跟着变的前提是jinyong2.py也引入了改变yitian.py中变量的jinyong.py模块,
而jinyong3.py只引入了yitian.py模块,没有引入改变yitian.py中变量的jinyong.py模块,则输出的还是'张无忌').
# yitian.py 以下是文件yitian.py中的代码
main_person_man = '张无忌' ----------------------------------------------------- # jinyong.py 以下是文件jinyong.py 中的代码
import yitian
yitian.main_person_man = '宝宝' ------------------------------------------------------- # jinyong2.py 下面是jinyong2.py文件中的内容
import yitian
import jinyong
print(yitian.main_person_man) # 输出结果是 '宝宝' ----------------------------------------------------------
# jinyong3.py 下面是jinyong3.py文件中的内容
import yitian
print(yitian.main_person_man) # 输出的是 '张无忌'
# jinyong2.py 下面是jinyong2.py文件中的内容
# import jinyong # 改变其他模块变量的模块在前面导入也是一样的会输出改变后的变量,原因就是在一个模块中(同一个名称空间中)相同的模块只会导入一次(同一个名称空间中只会产生一个同名的名称空间:在jinyong2.py的名称空间中只会产生一个yitian.py的名称空间,之后再次import什么都不做)
import yitian # 在该py文件中第一次引入yitian模块,-->创建yitian的名称空间,-->执行yitian.py中的代码-->产生变量 main_person_man = '张无忌' import jinyong # 在该py文件中第一次引入jinyong模块,-->创建jinyong的名称空间,-->执行jinyong.py中的代码-->执行到import yitian时候,在该py文件jinyong2.py中已经导入过yitian模块,不会重复导入(即不会重复创建yitian名称空间),共享同一个yitian名称空间,;所以执行到 yitian.main_person_man = '宝宝'时候,就修改了该 yitian名称空间 中的main_person_man为 '宝宝'. print(yitian.main_person_man) # 调用的时候去自己加载的 yitian名称空间 去找main_person_man,就是修改过的 '宝宝'
jinyong2.py执行过程解析
上述问题出现的原因:
1. ⼤家共享同一个模块的名称空间.
2. 在⾦庸.py ⾥改变了主角的名字
如何解决呢?
(需求:金庸2.py 想要引入倚天.py 和 金庸.py(当金庸中有其他的属性时候),但是又不想 金庸.py 改变 倚天.py 中的值,
即改变 倚天.py 中变量的值的代码,只想要在金庸.py被执行(作为启动文件)的时候执行,而金庸.py作为引入模块被别的模块导入的时候不执行.)
⾸先,我们不能去改python,因为python的规则不是我们定的,只能想办法不要改变主角的名字. 但是,在金庸⾥我就有这样的需求. 那此时就出现了 在金庸被执⾏的时候要执⾏的代码,在⾦庸被别⼈导入的时候我们不想执⾏这些代码. 此时, 我们就要利用一下__name__
这个内置变量了. 在Python中,每个模块都有⾃己的__name__ ,但是这个__name__的值是不
定的,当我们把一个模块作为程序运行的入口时,此时该模块的__name__是"__main__" , 而如果我们把模块导入时,此时模块内部的__name__就是该模块⾃身的名字.基于此,我们可以用一下方式去修改金庸.py的代码.
# jinyong.py 以下是文件jinyong.py中的代码 import yitian if __name__ == '__main__': # 只有当前文件是启动文件的时候才会执行
yitian.main_person_man = '宝宝'
一次引入多个模块的导入顺序
正确的导入模块的顺序:
1. 所有的模块导入都要写在最上⾯. 这是最基本的
2. 先引入内置模块(比如os,time,re等)
3. 再引入扩展模块(第三方的模块,比如Django等)
4. 最后引入你⾃己定义的模块
from xxx import xxx
对比import my_module,会将源文件的名称空间'my_module'带(复制)到当前名称空间中,使用时必须是 my_module.属性名 的方式;而from 语句相当于import,也会在第一次导入时候创建新的名称空间,但是会将my_module中的属性直接导入到当前的名称空间中(说⽩了就 是部分导入. 当一个模块中的内容过多的时候,我们可以选择性的导入要使用的内容),在当前名称空间中直接使用属性名字就可以调用了.
# 测试-->导入的函数fight_in_shaolin,执行时仍然回到yitian.py中寻找全局变量main_person_man
from yitian import fight_in_shaolin
main_person_man = '宝宝' fight_in_shaolin() # 张无忌 击败了 周芷若
如果当前有重名fight_in_shaolin,那么会有覆盖效果。
from yitian import fight_in_shaolin
def fight_on_shaolin():
print("我要干少林") fight_on_shaolin() # 我要干少林
所以. 不要重名. 切记. 不要重名! 不仅仅是变量名不要重复.
我们⾃己创建的py文件的名字也不要和系统内置的模块重名.
否则引入的模块都是Python内置的模块.
也⽀持一⾏语句导入多个内容
from yitian import fight_in_shaolin, fight_on_light_top, main_person_man
fight_in_shaolin()
fight_on_light_top()
print(main_person_man)
也支持as
from yitian import fight_in_shaolin, main_person_man as big_lao
fight_in_shaolin()
print(big_lao)
from my_module import *
from my_module import * 把my_module中所有的不是以下划线(_)开头的名字都导入到当前位置,大部分情况下我们的python程序不应该使用这种导入方式,因为*你不知道你导入的是什么名字,很有可能会覆盖掉你之前已经定义的名字。而且可读性极其的差,在交互式环境中导入时没有问题。
注意, 如果模块中 没有写出__all__ 则默认所有内容都导入. 如果写了__all__ 此时导入的内容就是在__all__列表 中列出来的所有名字.(记住:__all__只对*有用)
# haha.py
__all__ = ["money", "chi"] # 注意:带引号,因为是列表的元素
money = 100
def chi():
print("我是吃") def he():
print("我是呵呵") # test.py
from haha import *
chi() print(money) # he() # 报错
包
什么是包?
包是一种通过使用‘.模块名’来组织python模块名称空间的方式。
1. 无论是import形式还是from...import形式,凡是在导入语句中(而不是在使用时)遇到带点的,都要第一时间提高警觉:这是关于包才有的导入语法
2. 包是目录级的(文件夹级),文件夹是用来组织py文件的(包的本质就是一个包含__init__.py文件的目录)
3. import导入文件时,产生名称空间中的名字来源于文件,import 导入包时,产生的名称空间的名字同样来源于文件,即包下的__init__.py,导入包本质就是在导入该文件
强调:
1. 在python3中,即使包下没有__init__.py文件,import 包仍然不会报错,而在python2中,包下一定要有该文件,否则import 包报错
2. 创建包的目的不是为了运行,而是被导入使用,记住,包只是模块的一种形式而已,包即模块
为何要使用包?
包的本质就是一个文件夹, 那么文件夹唯一的功能就是将文件组织起来, 随着功能越写越多, 我们无法将所有功能都放在一个文件中, 于是我们使⽤模块去组织功能,
随着模块越来越多, 我们就需要用文件夹将模块文件组织起来, 以此来提高程序的结构性和可维护性.
如何使用包?
1.关于包相关的导入语句也分为import xxx和from xxx import xxx两种,但是无论哪种,无论在什么位置,在导入时都必须遵循一个原则:凡是在导入时带点的,点的左边都必须是一个包,否则非法。可以带有一连串的点,如item.subitem.subsubitem,但都必须遵循这个原则。(直接使用 import 模块名 ,后面的模块名是可以带点的,而使用from xxx import xxx,这里的import后面是不能带点的,只有from后面可以带点)
(要注意. from xxx import xxx这种形式, import后面必须是明确的不可以出现"点" ,否则会有语法错误,也就是说from a.b import c是ok的,但是 from a import b.c 是错误的.)
2.对于导入后,在使用时就没有这种限制了,点的左边可以是包,模块,函数,类(它们都可以用点的方式调用自己的属性)。
3.对比import item 和from item import name的应用场景:如果我们想直接使用name那必须使用后者。
首先, 我们先创建一些包. 用来作为接下来的学习. 包很好创建. 只要是一个文件夹, 有 __init__.py就可以.
import os
os.makedirs('glance/api') os.makedirs('glance/cmd') os.makedirs('glance/db')
l = [] l.append(open('glance/__init__.py','w')) l.append(open('glance/api/__init__.py','w')) l.append(open('glance/api/policy.py','w')) l.append(open('glance/api/versions.py','w')) l.append(open('glance/cmd/__init__.py','w')) l.append(open('glance/cmd/manage.py','w')) l.append(open('glance/db/__init__.py','w')) l.append(open('glance/db/models.py','w')) map(lambda f:f.close() ,l)
创建文件目录代码
#文件内容 #policy.py
def get():
print('from policy.py') #versions.py
def create_resource(conf):
print('from version.py: ',conf) #manage.py
def main():
print('from manage.py') #models.py
def register_models(engine):
print('from models.py: ',engine)
文件内容
创建好的目录结构 如下:
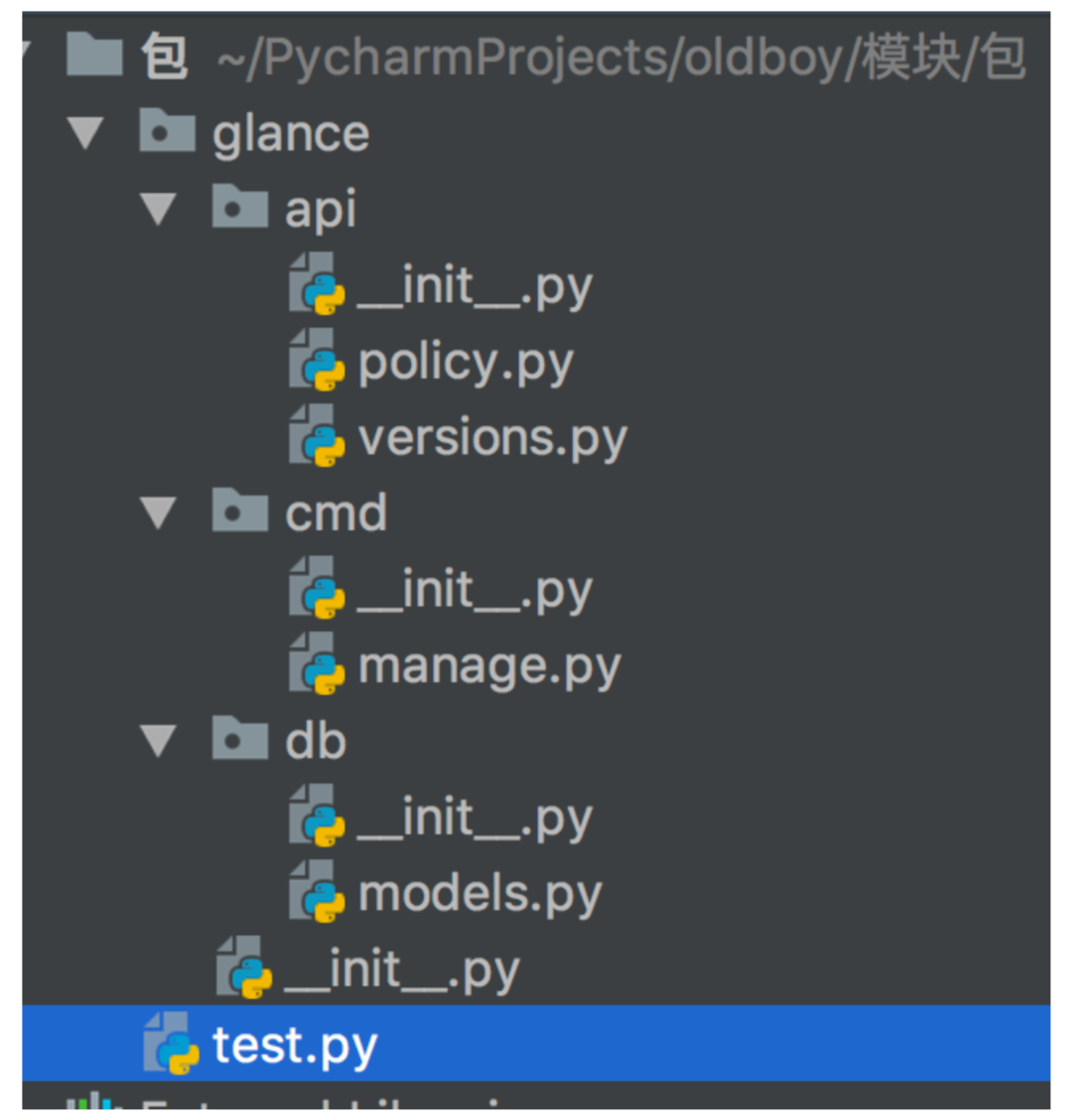
import 包名
我们在与包glance同级别的文件中测试
import glance.db.models
glance.db.models.register_models('mysql')
from xxx import xxx
我们在与包glance同级别的文件中测试
from glance.api.policy import get
get()
__init__.py文件
不管是哪种方式,只要是第一次导入包或者是包的任何其他部分,都会依次执行包下的__init__.py文件,这个文件可以为空,但是也可以存放一些初始化包的代码。
from xxx import *
我们要在__init__.py文件中给出 __all__来确定* 导入的内容.
print("我是glance的__init__.py⽂文件. ") x = 10
def hehe():
print("我是呵呵") def haha():
print("我是哈哈") __all__ = ['x', "hehe"]
# test.py
from glance import *
print(x) # OK
hehe() # OK
haha() # 报错. __all__里没有这个⻤东西
绝对导入和相对导入
glance/ ├── __init__.py from glance import api
from glance import cmd
from glance import db ├── api │ ├── __init__.py from glance.api import policy
from glance.api import versions │ ├── policy.py │ └── versions.py ├── cmd from glance.cmd import manage │ ├── __init__.py │ └── manage.py └── db from glance.db import models ├── __init__.py └── models.py
绝对导入
glance/ ├── __init__.py from . import api #.表示当前目录
from . import cmd
from . import db ├── api │ ├── __init__.py from . import policy
from . import versions │ ├── policy.py │ └── versions.py ├── cmd from . import manage │ ├── __init__.py │ └── manage.py from ..api import policy
#..表示上一级目录,想再manage中使用policy中的方法就需要回到上一级glance目录往下找api包,从api导入policy └── db from . import models ├── __init__.py └── models.py
相对导入
我们的最顶级包glance是写给别人用的,然后在glance包内部也会有彼此之间互相导入的需求,这时候就有绝对导入和相对导入两种方式:
绝对导入:以glance作为起始
相对导入:用.或者..的方式作为起始(.是当前目录, ..是上一级目录)
测试的时候要注意:python包路径跟运行脚本所在的目录有关系,说⽩了就是你运⾏的 py文件所在的目录(sys.path).
在python中不允许你运⾏的程序导包的时候超过当前包的范围(相对导 入). 如果使⽤绝对导入,没有这个问题.
换个说法. 如果你在包内使⽤了相对导入. 那在使⽤该 包内信息的时候. 只能在包外面导入 ???没明白
注意:一定要在与glance同级的文件中测试(启动文件一定要在最外层,即跟文件目录中).
单独导入包
单独导入包名称时不会导入包中所有包含的所有子模块,解决方法是在包内的__init__.py文件中导入包内的子模块.
#在与glance同级的test.py中
import glance
glance.cmd.manage.main() '''
执行结果:
AttributeError: module 'glance' has no attribute 'cmd' ''' # 解决方法:
#glance/__init__.py
from . import cmd #glance/cmd/__init__.py
from . import manage # 执行:
#在于glance同级的test.py中
import glance
glance.cmd.manage.main()
day25 内置常用模块(四): 模块和包的更多相关文章
- day05 模块以及内置常用模块用法
内置常用模块详解: 1 time 2 datetime 3 random 4 os 5 sys 6 shutil 7 shelve 8 xml 9 configparser 10 hashlib ...
- python协程函数、递归、匿名函数与内置函数使用、模块与包
目录: 协程函数(yield生成器用法二) 面向过程编程 递归 匿名函数与内置函数的使用 模块 包 常用标准模块之re(正则表达式) 一.协程函数(yield生成器用法二) 1.生成器的语句形式 a. ...
- python内置常用高阶函数(列出了5个常用的)
原文使用的是python2,现修改为python3,全部都实际输出过,可以运行. 引用自:http://www.cnblogs.com/duyaya/p/8562898.html https://bl ...
- Harp – 内置常用预处理器的静态 Web 服务器
Harp 是一个基于 Node.js 平台的静态 Web 服务器,内置流行的预处理器,支持把 Jade, Markdown, EJS, Less, Stylus, Sass, and CoffeeSc ...
- python3 内置常用函数系列一
python3 内置了一系列的常用函数, python英文官方文档详细说明:点击查看, 为了方便查看,将内置常用的函数的记录一下来. Python3版本所有的内置函数: 1.abs() print(a ...
- Day5 函数递归,匿名、内置行数,模块和包,开发规范
一.递归与二分法 一.递归 1.递归调用的定义 递归调用:在调用一个函数的过程中,直接或间接地调用了函数本身 2.递归分为两类:直接与间接 #直接 def func(): print('from fu ...
- python学习笔记(七)- 递归、python内置函数、random模块
1.函数的不固定参数: #参数不是必填的.没有限制参数的个数.返回参数组的元组 def syz(*args): #参数组,不限制参数个数 #‘args’参数的名字可以随便命名 print(args) ...
- Orchard内置特性(以模块来说的)
本文链接:http://www.cnblogs.com/souther/p/4539169.html 主目录 Orchard中有很多可以直接和多次使用的特性,这些东西在官方的Gallery中可以找到. ...
- python 内置标准库socketserver模块的思考
socketserver模块简化了编写网络服务器的任务, 在很大程度上封装了一些操作, 你可以看成是事件驱动型的设计, 这很不错.它定义了两个最基本的类--服务器类 BaseServer, 请求处理类 ...
随机推荐
- 在 WPF 程序中应用 Windows 10 真?亚克力效果
原文:在 WPF 程序中应用 Windows 10 真?亚克力效果 从 Windows 10 (1803) 开始,Win32 应用也可以有 API 来实现原生的亚克力效果了.不过相比于 UWP 来说, ...
- 2.7_Database Interface OLE-DB诞生
ODBC仅支持关系数据库,以及传统的数据库类型,并且只以C/C++语言API(API就是一些C语言的代码,是最底层的程序,在windows中就是一些.dll的文件)形式提供服务,因而无法符合日渐复杂的 ...
- 服务端php之文件上传
知识点 echo $_SERVER['PHP_SELF']; 自动获取当前文件的路劲(即提交地址为当前页面) 当一个表单有文件域(即文件上传)的时候,method(提交方式)要设置post,这样更加安 ...
- 点击其它位置,div下拉菜单消失
接下拉菜单那一篇: 加上点击其它位置,下拉菜单消失. 纯js写法: window.document.addEventListener('click', function(e) { var e = e ...
- Oracle 创建与管理用户
标识用户是 Oracle 数据库管理的基本要求之一,每一个能够连接到数据库的用户都必须是系统的合法用户.用户想要使用 Oracle 的系统资源,就必须拥有相应的权限. 一.身份验证 Oracle 为用 ...
- linux设置网卡速率
ethtool # ethtool ethX //查询ethX网口基本设置 # ethtool –h //显示ethtool的命令帮助(help) # ethtool –i ethX //查询ethX ...
- 小程序 wx.getSystemInfoSync 获取 windowHeight 不准确的问题
如果本文对你有用,请爱心点个赞,提高排名,帮助更多的人.谢谢大家!❤ 如果解决不了,可以在文末进群交流. wx.getSystemInfo(OBJECT) 获取系统信息. OBJECT参数说明: 参数 ...
- mac中git使用
配置用户名及邮箱在使用Git提交前,必须配置用户名和邮箱,这些信息会永久保存到历史记录中.git config --global user.name "xxxxxx"git con ...
- java对象json序列化时忽略值为null的属性
环境: jdk: openjdk11 操作系统: windows 10教育版1903 目的: 如题,当一个对象里有些属性值为null 的不想参与json序列化时,可以添加如下注解 import com ...
- mysql 优化修复表
OPTIMIZE TABLE `table_name` 优化表 MyISAM 引擎清理碎片 OPTIMIZE语法: OPTIMIZE [LOCAL | NO_WRITE_TO_BINLOG] TABL ...