网络协议 17 - HTTPDNS
全球统一的 DNS 是很权威,但是我们都知道“适合自己的,才是最好的”。很多时候,标准统一化的 DNS 并不能满足我们定制的需求,这个时候就需要 HTTPDNS 了。
上一节我们知道了 DNS 可以根据名称查地址,也可以针对多个地址做负载均衡。然而,我们信任的地址簿也会存在指错路的情况。明明离你 500 米就有个吃饭的地方,非要把你推荐到 5 公里外。为什么会出现这样的情况呢?
还记得吗?由我们发出请求解析 DNS 的时候,首先会连接到运营商本地的 DNS 服务器,由这个服务器帮我们去整棵 “DNS 树” 上进行解析,然后将解析的结果返回给客户端。但是本地的 DNS 服务器,作为一个本地导游,往往会有自己的“小心思”。
传统 DNS 存在的问题
1)域名缓存问题
它可以在本地做一个缓存。也就是说,不是每一个请求,它都会去访问权威 DNS 服务器,而是把访问过一次的结果缓存到本地,当其他人来问的时候,直接返回缓存的内容。
这就相当于导游去过一个饭店,自己记住了地址,当有一个游客问的时候,他就凭记忆回答了,不用再去查地址簿。这样会存在一个问题,游客问的那个饭店如果已经搬走了,然而因为导游没有刷新“记忆缓存”,导致游客白跑一趟。
另外,有的运营商会把一些静态页面,缓存到本运营商的服务器内,这样用户请求的时候,就不用跨运营商进行访问,既加快了速度,也减少了运营商直接流量计算的成本。也就是说,在域名解析的时候,不会将用户导向真正的网站,而是指向这个缓存的服务器。
缓存的问题,很多情况下是看不出问题的,但是当页面更新,用户访问到老的页面,问题就出来了。
再就是本地的缓存,往往使得全局负载均衡失败。上次进行缓存的时候,缓存中的地址不一定是客户此次访问离客户最近的地方,如果把这个地址返回给客户,就会让客户绕远路了。
2)域名转发问题
还记得我们域名解析的过程吗?捂脸是本地域名解析,还是去权威 DNS 服务器中查找,都可以认为是一种外包形式。有了请求,直接转发给其他服务去解析。如果转发的是权威 DNS 服务器还好说,但是如果因为“偷懒”转发给了邻居服务器去解析,就容易产生跨运营商访问的问题。
这就好像,如果 A 运营商的客户,访问自己运营商的 DNS 服务器,A 运营商去权威 DNS 服务器查询的话,会查到客户的 A 运营商的,返回一个部署在 A 运营商的网站地址,这样针对相同运营商的访问,速度就会快很多。
但是如果 A 运营商偷懒,没有转发给权威 DNS ,而是转发给了 B 运营商,让 B 运营商再去权威 DNS 服务器查询,这样就会让权威服务器误认为客户是 B 运营商的,返回一个 B 运营商的服务器地址,导致客户每次都要跨运营商访问,访问速度就会慢下来。
3)出口 NAT 问题
前面了解网关的时候,我们知道,出口的时候,很多机房都会配置 NAT,也就是网络地址转换,使得从这个网关出去的包,都换成新的 IP 地址。
这种情况下,权威 DNS 服务器就没办法通过请求 IP 来判断客户到底是哪个运营商的,很有可能误判运营商,导致跨运营商访问。
4)域名更新问题
本地 DNS 服务器是由不同地区、不同运营商独立部署的。对域名解析缓存的处理上,实现策略也有区别。有的会偷懒,忽略域名解析结构的 TTL 时间限制,在权威 DNS 服务器解析变更的时候,解析结果在全网生效的周期非常漫长。但是有的场景,在 DNS 的切换中,对生效时间要求比较高。
例如双机房部署的是,跨机房的负载均衡和容灾多使用 DNS 来做。当一个机房出问题之后,需要修改权威 DNS,将域名指向新的 IP 地址。但是如果更新太慢,很多用户都会访问一次。
5)解析延迟问题
从 DNS 的查询过程来看,DNS 的查询过程需要递归遍历多个 DNS 服务器,才能获得最终的解析结果,这带来一定的延时,甚至会解析超时。
上面总结了 DNS 的五个问题。问题有了,总得有解决办法,就像因为 HTTP 的安全问题,才火了 HTTPS 协议一样,对应的,也有 HTTPDNS 来解决上述 DNS 出现的问题。
HTTPDNS
什么是 HTTPDNS ?其实很简单:
HTTPDNS 是基于 HTTP 协议和域名解析的流量调度解决方案。它不走传统的 DNS 解析,而是自己搭建基于 HTTP 协议的 DNS 服务器集群,分布在多个地点和多个运营商。当客户端需要 DNS 解析的时候,直接通过 HTTP 请求这个服务器集群,得到就近的地址。
这就相当于每家基于 HTTP 协议,自己实现自己的域名解析,做一个自己的地址簿,而不使用统一的地址簿。但是我们知道,域名解析默认都是走 DNS 的,因而使用 HTTPDNS 需要绕过默认的 DNS 路径,也就不能使用默认的客户端。**使用 HTTPDNS 的,往往是手机应用,需要在手机端嵌入支持 HTTPDNS 的客户端 SDK。
HTTPDNS 的工作流程
接下来,我们一起来认识下 HTTPDNS 的工作流程。
HTTPDNS 会在客户端的 SDK 里动态请求服务端,获取 HTTPDNS 服务器的 IP 列表,缓存在本地。随着不断地解析域名,SDK 也会在本地缓存 DNS 域名解析的结果。
当手机应用要访问一个地址的时候,首先看是否有本地的缓存,如果有直接返回。这个缓存和本地 DNS 的缓存不一样的是,这个是手机应用自己做的,而非整个运营商统一做。如何更新以及何时更新缓存,手机应用的客户端可以和服务器协调来做这件事情。
如果本地没有,就需要请求 HTTPDNS 的服务器,在本地 HTTPDNS 服务器的 IP 列表中,选择一个发出 HTTP 请求,获取一个要访问的网站的 IP 列表。
请求的方式是这样的:
手机客户端之道手机在哪个运营商、哪个地址。由于是直接的 HTTP 通信,HTTPDNS 服务器能够准确知道这些信息,因而可以做精准的全局负载均衡。
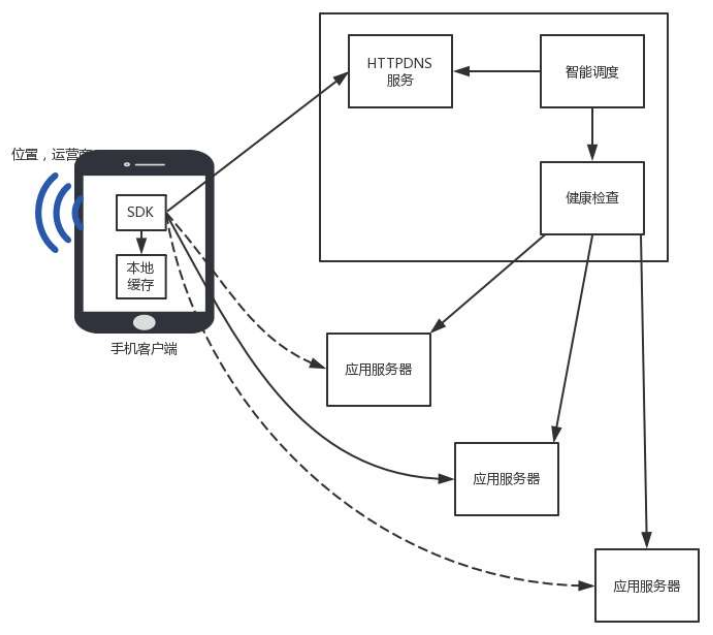
上面五个问题,归结起来就两大问题。一是解析速度和更新速度的平衡问题,二是智能调度的问题。HTTPDNS 对应的解决方案是 HTTPDNS 的缓存设计和调度设计。
HTTPDNS 的缓存设计
解析 DNS 过程复杂,通信此时多,对解析速度造成很大影响。为了加快解析,因而有了缓存,但是这又会产生缓存更新速度不及时的问题。最要命的是,这两个方面都掌握在别人手中,也就是本地 DNS 服务器手中,它不会为你定制,作为客户端干着急也没办法。
而 HTTPDNS 就是将解析速度和更新速度全部掌控在自己手中。
一方面,解析的过程,不需要本地 DNS 服务递归的调用一大圈,一个 HTTP 的请求直接搞定。要实时更新的时候,马上就能起作用。
另一方面,为了提高解析速度,本地也有缓存,缓存是在客户端 SDK 维护的,过期时间、更新时间,都可以自己控制。
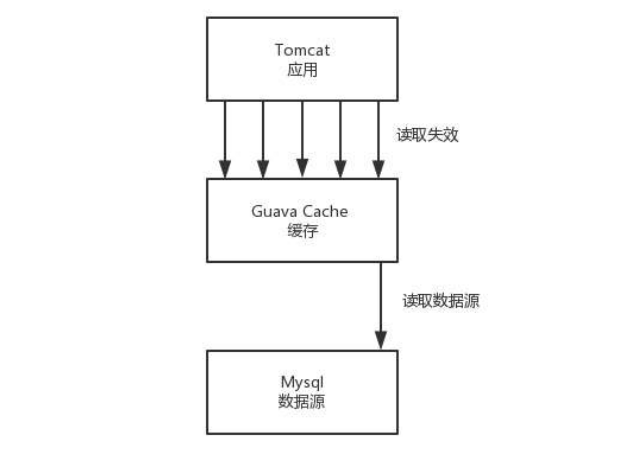
HTTPDNS 的缓存设计策略也是咱们做应用架构中常用的缓存设计模式,也即分为客户端、缓存、数据源三层。
- 对于应用架构来讲,就是应用、缓存、数据库。常见的是 Tomcat、Redis、Mysql;
- 对于 HTTPDNS 来讲,就是手机客户端、DNS 缓存、HTTPDNS 服务器。

只要是缓存模式,就存在缓存的过期、更新、不一致的问题,解决思路也是相似的。
例如,DNS 缓存在内存中,也可以持久化到存储上,从而 APP 重启之后,能够尽快从存储中加载上次累积的经常访问的网站的解析结果,就不需要每次都全部解析一遍,再变成缓存。这有点像 Redis 是基于内存的缓存,但是同样提供持久化的能力,使得重启或者主备切换的时候,数据不会完全丢失。
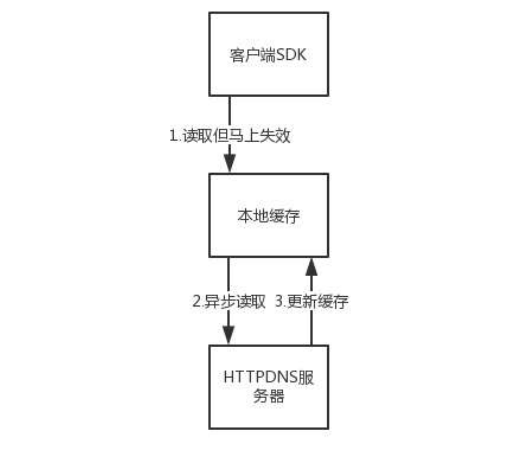
SDK 中的缓存会严格按照缓存过期时间,如果缓存没有命中,或者已经过期,而且客户端不允许使用过期的几率,则会发起一次解析,保证缓存记录是更新的。
解析可以同步进行,也就是直接调用 HTTPDNS 的接口,返回最新的记录,更新缓存。也可以异步进行,添加一个解析任务到后台,由后台任务调用 HTTPDNS 的接口。
同步更新的优点是实时性好,缺点是如果有多个请求都发现过期的时候,会同时请求 HTTPDNS 多次,造成资源浪费。
同步更新的方式对应到应用架构缓存的 Cache-Aside 机制,也就是先读缓存,不命中读数据库,同时将结果写入缓存。

异步更新的优点是,可以将多个请求都发现过期的情况,合并为一个对于 HTTPDNS 的请求任务,只执行一次,减少 HTTPDNS 的压力。同时,可以在即将过期的时候,就创建一个任务进行预加载,防止过期之后再刷新,称为预加载。
它的缺点是,当前请求拿到过期数据的时候,如果客户端允许使用过期时间,需要冒一次风险。这次风险是指,如果过期的请求还能请求,就没问题,如果不能请求,就会失败一次,等下次缓存更新后,才能请求成功。
异步更新的机制,对应到应用架构缓存的 Refresh-Ahead 机制,即业务仅仅访问缓存,当过期的时候定期刷新。在著名的应用缓存 Guava Cache 中,有个 RefreshAfterWrite 机制,对于并发情况下,多个缓存访问不命中从而引发并发回源的请求,可以采取只有一个请求回源的模式。在应用架构的缓存中,也常常用数据预热或者预加载的机制。
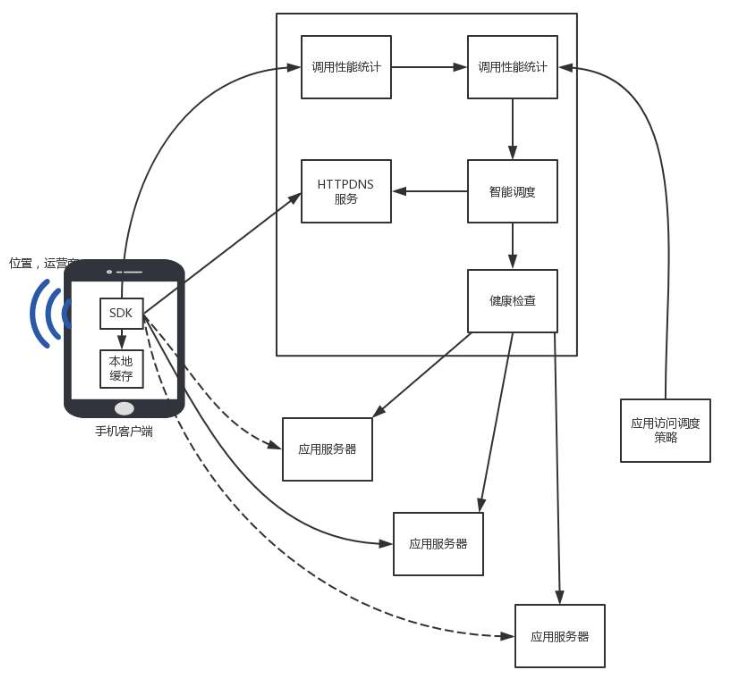
HTTPDNS 的调度设计
由于客户端嵌入了 SDK,因而就不会因为本地 DNS 的各种缓存、转发、NAT,让权威 DNS 服务器误会客户端所在的位置和运营商,从而可以拿到第一手资料。
在客户端,可以知道手机是哪个国家、哪个运营商、哪个省、甚至是哪个市,HTTPDNS 服务端可以根据这些信息,选择最佳的服务节点返回。
如果有多个节点,还会考虑错误率、请求时间、服务器压力、网络状态等,进行综合选择,而非仅仅考虑地理位置。当有一个节点宕机或者性能下降的时候,可以尽快进行切换。
要做到这一点,需要客户端使用 HTTPDNS 返回的 IP 访问业务应用。客户端的 SDK 会收集网络请求数据,如错误率、请求时间等网络请求质量数据,并发送到统计后台,进行分析、聚合,以此查看不同 IP 的服务质量。
在服务端,应用可以通过调用 HTTPDNS 的管理接口,配置不同服务质量的优先级、权重。HTTPDNS 会根据这些策略综合地理位置和线路状况算出一个排序,优先访问当前那些优质的、时延低的 IP 地址。
HTTPDNS 通过智能调度之后返回的结果,也会缓存在客户端。为了不让缓存使得调度失真,客户端可以根据不同的移动网络运营商的 SSID 来分维度缓存。不同的运营商解析出来的结果会不同。
小结
- 传统 DNS 会因为缓存、转发、NAT 等问题导致客户端误会自己所在的位置和运营商,从而影响流量的调度;
- HTTPDNS 通过客户端 SDK 和服务端,通过 HTTP 直接调用解析 DNS 的方式,绕过了传统 DNS 的缺点,实现了智能的调度。
欢迎添加个人微信号:Like若所思。
欢迎关注我的公众号,不仅为你推荐最新的博文,还有更多惊喜和资源在等着你!一起学习共同进步!

网络协议 17 - HTTPDNS的更多相关文章
- 网络协议 17 - HTTPDNS:私人定制的 DNS 服务
[前五篇]系列文章传送门: 网络协议 12 - HTTP 协议:常用而不简单 网络协议 13 - HTTPS 协议:加密路上无尽头 网络协议 14 - 流媒体协议:要说爱你不容易 网络协议 15 - ...
- 网络协议 20 - RPC 协议(上)- 基于XML的SOAP协议
[前五篇]系列文章传送门: 网络协议 15 - P2P 协议:小种子大学问 网络协议 16 - DNS 协议:网络世界的地址簿 网络协议 17 - HTTPDNS:私人定制的 DNS 服务 网络协议 ...
- 网络协议 19 - RPC协议综述:远在天边近在眼前
[前五篇]系列文章传送门: 网络协议 14 - 流媒体协议:要说爱你不容易 网络协议 15 - P2P 协议:小种子大学问 网络协议 16 - DNS 协议:网络世界的地址簿 网络协议 17 - HT ...
- 网络协议 18 - CDN:家门口的小卖铺
[前五篇]系列文章传送门: 网络协议 13 - HTTPS 协议:加密路上无尽头 网络协议 14 - 流媒体协议:要说爱你不容易 网络协议 15 - P2P 协议:小种子大学问 网络协议 16 - D ...
- PYTHON黑帽编程1.5 使用WIRESHARK练习网络协议分析
Python黑帽编程1.5 使用Wireshark练习网络协议分析 1.5.0.1 本系列教程说明 本系列教程,采用的大纲母本为<Understanding Network Hacks At ...
- C# RFID windows 服务 网络协议方式
上篇话说是串口方式操作RFID设备. 下面介绍网络协议方式. 设备支持断线重连. 那我们的服务也不能差了不是. 所以这个服务类也是支持的哦. 不解释上代码: namespace Rfid { /// ...
- linux网络协议
网络协议 本章节主要介绍linxu网络模型.以及常用的网络协议分析以太网协议.IP协议.TCP协议.UDP协议 一.网络模型 TCP/IP分层模型的四个协议层分别完成以下的功能: 第一层 网络接口层 ...
- linux 网络协议分析---3
本章节主要介绍linxu网络模型.以及常用的网络协议分析以太网协议.IP协议.TCP协议.UDP协议 一.网络模型 TCP/IP分层模型的四个协议层分别完成以下的功能: 第一层 网络接口层 网络接口层 ...
- TFTP网络协议分析---15
TFTP网络协议分析 周学伟 文档说明:所有函数都依托与两个出口,发送和接收. 1:作为发送时,要完成基于TFTP协议下的文件传输,但前提是知道木的PC机的MAC地址,因为当发送TFTP请求包时必须提 ...
随机推荐
- PHP接口并发测试的方法
PHP接口并发测试的方法 <pre> header('Content-type:text/html; Charset=utf-8'); $uri = "输入你的url" ...
- centos6.5 安装openresty
[1]centos6.5 安装openresty步骤 (1)基础依赖库安装 1.1 yum install pcre-devel openssl-devel gcc curl (2)openResty ...
- 前端图片canvas,file,blob,DataURL等格式转换
将file转化成base64 方法一:利用URL.createObjectURL() <!DOCTYPE html> <html> <head> <title ...
- FastDFS与hadoop的HDFS区别
主要是定位和应用场合不一样 HDFS: 要解决并行计算中分布式存储数据的问题.其单个数据文件通常很大,采用了分块(切分)存储的方式. FastDFS: 主要用于大中网站,为文件上传和下载提供在线服务. ...
- 干货满满!如何优雅简洁地实现时钟翻牌器(支持JS/Vue/React)
双十一剁手节过去了,大家应该在很多网页中看到了数字翻牌的效果吧,比如倒计时. 数字增长等.相信很多人都已经自己独立实现过了,我也在网上看了一些demo,发现HTML结构大多比较复杂,用了4个并列的标签 ...
- 关于多个版本的jquery冲突的问题
关于多个版本的jquery冲突的问题 先加载新的版本jquery 然后使用no confi代码,直接上代码看效果 <script src="https://libs.baidu.com ...
- 'while' statement cannot complete without throwing an exception
You are probably using Android Studio or IntelliJ. If so, you can add this above your method contain ...
- jq处理动画累加
问题:日程提醒(跟日历一样的切换效果),只用一个div来展示当天日程数据,每次清空div里的数据再加载数据,导致切换日期时,数据展示div有闪动,于是采用动画来进行过渡,这样就巧妙地避免了闪动: $( ...
- 在 VSCode 调试过程中,使用 Watcher,免手动重新编译
1.安装Microsoft.DotNet.Watcher.Tools包 dotnet add package Microsoft.DotNet.Watcher.Tools --version 2.0. ...
- linux常用命令--开发调试篇
前言 Linux常用命令中有一些命令可以在开发或调试过程中起到很好的帮助作用,有些可以帮助了解或优化我们的程序,有些可以帮我们定位疑难问题.本文将简单介绍一下这些命令. 示例程序 我们用一个小程序,来 ...