Mysql中 查询慢的 Sql语句的记录查找
Mysql中 查询慢的 Sql语句的记录查找
慢查询日志 slow_query_log,是用来记录查询比较慢的sql语句,通过查询日志来查找哪条sql语句比较慢,这样可以对比较慢的sql可以进行优化。
1. 登陆我们的mysql数据库:
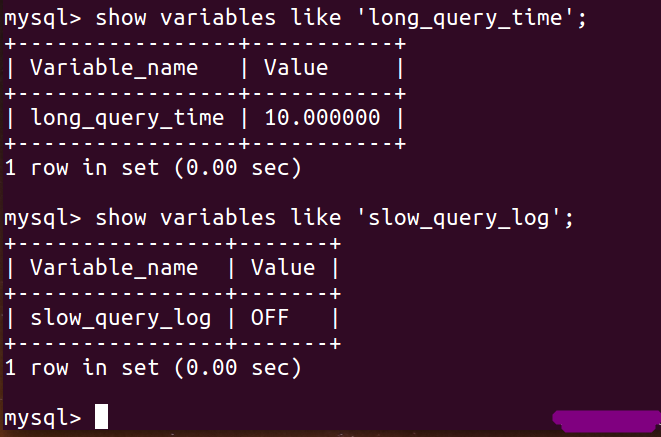
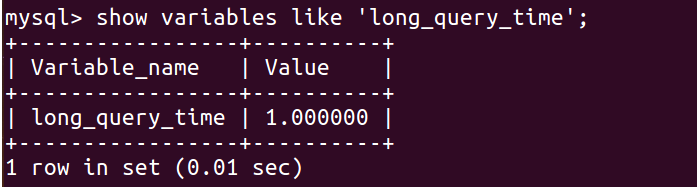
2. 查看一下当前的慢查询是否开启,以及慢查询所规定的时间:
show variables like 'slow_query_log'; show variables like 'long_query_time';
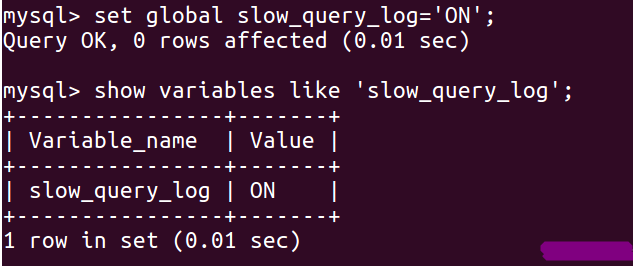
3. 如果你的查询后的结果是OFF 状态的话,就需要通过相关设置将其修改为ON状态:
set global slow_query_log='ON';
4. 将慢查询追踪的时间设置为1s:
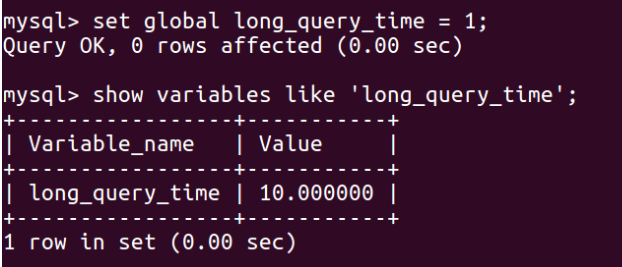
这里你在设置之后,这个世界是不会立即变成1s的,需要在数据库重启后才生效:
5. 设置慢查询日志文件保存的位置:
set global slow_query_log_file='/var/lib/mysql/test_1116.log';
6. 查看以下配置后的文件:
sudo subl /var/lib/mysql/test_1116.log
=============================================================================================================================
=============================================================================================================================
MySQL数据库慢查询问题排查方法
最近碰到了几次数据库响应变慢的问题,整理了一下处理的流程和分析思路,执行脚本。希望对其他人有帮助。
MySQL慢查询表现
明显感觉到大部分的应用功能都变慢,但也不是完全不能工作,等待比较长的时间还是有响应的。但是整个系统看起来就非常的卡。
查询慢查询数量
一般来说一个正常运行的MySQL服务器,每分钟的慢查询在个位数是正常的,偶尔飙升到两位数也不是不能接受,接近100系统可能就有问题了,但是还能勉强用。这几次出问题慢查询的数量已经到了1000多。
慢查询的数量保存在mysql库里面的slow_log表。
SELECT * FROM `slow_log` where start_time > '2019/05/19 00:00:00';
这样就能查出一天以来的慢查询了。
查看当前进行的查询状态
大家应该都比较常用show processlist来查看当前系统中正在执行的查询,其实这些数据也保存在information_schema库里面的processlist表,因此如果要做条件查询,直接查询这张表更方便。
比如查看当前所有的process
select * from information_schema.processlist
查看当前正在进行的查询并按照已经执行时间倒排
select * from information_schema.processlist where info is not null order by time desc
正常运行的数据库,因为一条查询的执行速度很快,被我们的select抓到的info不是null的查询数量会很少。我们这样负荷很大的库一般也就只能查到几条。如果一次能查到info非空的查询有几十条,那么也可以认为系统出问题了。
系统问题和定位
当我们察觉到系统变慢之后,马上用慢查询和查看processlist的方式做了检查,结果发现每分钟慢查询数量飙升到1000多,同时淤积了大量的查询在执行中。
因为当务之急是尽快恢复系统的正常运行,因此影响最直接的做法是在processlist的查询结果中,查看有多少哪些查询处于lock状态,或者已经执行了很长时间,把这些process用kill指令干掉。通过不停的杀死这些可能会引发系统阻塞的process,最终能够暂时让系统逐步恢复到正常状态,当然这只是权宜之计。
此外,最重要的当然是分析到底是哪些查询为什么会引发系统阻塞,我们还是使用慢查询来做分析。
慢查询表查询结果里面有几个比较重要的指标:
start_time 开始时间,要通过这个参数,配合系统出问题的时间,定位哪些查询是罪魁祸首。
query_time 查询时间
rows_sent 和 rows_examined发送的结果数以及查询扫过的行数,这两个值特别重要,特别是 rows_examined。基本上就能告诉我们,哪个查询是需要注意的“大”查询。
实际操作中,我们也是把有大量rows_examined的查询一个个拿出来分析,添加索引,修改查询语句的编写,来彻底的解决问题。
处理结果和反思
经过对所有慢查询的检查和整改,目前MySQL每分钟慢查询数徘徊在1~2之间,CPU的负荷也非常低。问题算是基本得到了解决。
反思一下问题出现的原因,有几个地方需要注意:
1,数据库出问题往往不是上线即引发问题,而是有一个累积的过程,不断累加的糟糕的查询语句会逐步增加系统负载,最后压倒骆驼的最后一根稻草往往看上去莫名其妙
2,最后的一根稻草甚至有可能根本不存在,不是一次发版或者是功能上线,而是随着用户使用量上升,数据量的累积而爆发
3,既然问题的出现是累积的过程,就需要在每次代码发版之前做好review
4,索引的添加很重要
5,慢查询的监控也需要纳入到Zabbix的监控范围
原文地址https://blog.csdn.net/gymaisyl/article/details/84137478
原文地址https://blog.csdn.net/s_swordman/article/details/90341861
Mysql中 查询慢的 Sql语句的记录查找的更多相关文章
- 如何查找MySQL中查询慢的SQL语句
如何查找MySQL中查询慢的SQL语句 更多 如何在mysql查找效率慢的SQL语句呢?这可能是困然很多人的一个问题,MySQL通过慢查询日志定位那些执行效率较低的SQL 语句,用--log-slow ...
- 如何查找MySQL中查询慢的SQL语句(转载)
转载自https://www.cnblogs.com/qmfsun/p/4844472.html 如何在mysql查找效率慢的SQL语句呢?这可能是困然很多人的一个问题,MySQL通过慢查询日志定位那 ...
- MySQL中查询时间最大的一条记录
在项目中要查询用户最近登录的一条记录的 ip 直接写如下 SQL: SELECT ip,MAX(act_time) FROM users_login GROUP BY login_id; 但是这样是取 ...
- 关于mysql中实现replace的sql语句
update 表名 set 字段名=replace(字段名, '旧字符串', '新字符串')
- MySQL的EXPLAIN命令用于SQL语句的查询执行计划
MySQL的EXPLAIN命令用于SQL语句的查询执行计划(QEP).这条命令的输出结果能够让我们了解MySQL 优化器是如何执行SQL 语句的.这条命令并没有提供任何调整建议,但它能够提供重要的信息 ...
- [django/mysql] 使用distinct在mysql中查询多条不重复记录值的解决办法
前言:不废话.,直接进入正文 正文: 如何使用distinct在mysql中查询多条不重复记录值? 首先,我们必须知道在django中模型执行查询有两种方法: 第一种,使用django给出的api,例 ...
- 如何在MySQL中查询每个分组的前几名【转】
问题 在工作中常会遇到将数据分组排序的问题,如在考试成绩中,找出每个班级的前五名等. 在orcale等数据库中可以使用partition语句来解决,但在mysql中就比较麻烦了.这次翻译的文章就是专门 ...
- MySQL优化(五) SQL 语句的优化 索引、explain
一.索引 1.分类 (1)主键索引:当一张表的某个字段设置为主键时,该字段就是主键索引: (2)唯一索引:索引列中的值必须是唯一的,但是允许为空值(可以存在多个null): (3)普通索引:基本索引类 ...
- Mysql性能优化一:SQL语句性能优化
这里总结了52条对sql的查询优化,下面详细来看看,希望能帮助到你 1, 对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引. 2,应尽量避免在 w ...
随机推荐
- 关于SpringBoot下template文件夹下html页面访问的一些问题
springboot整合了springmvc的拦截功能.拦截了所有的请求.默认放行的资源是:resources/static/ 目录下所有静态资源.(不走controller控制器就能直接访问到资源) ...
- Springboot手动获取bean
使用如下工具类即可 package com.rio.ums.spa.commons.utils; import org.springframework.beans.BeansException; im ...
- APC (Asynchronous Procedure Call)
系统创建新线程时,会同时创建与这个线程相关联的队列,即异步过程调用(APC)的队列. 一些异步操作可以通过加入APC来实现,比如我现在学习的IO请求/完成. BOOL ReadFileEx( HAND ...
- SQL SERVER使用 CROSS APPLY 与 OUTER APPLY 连接查询
概述 CROSS APPLY 与 OUTER APPLY 可以做到: 左表一条关联右表多条记录时,我需要控制右表的某一条或多条记录跟左表匹配的情况. 有两张表:Student(学生表)和 S ...
- linux第三天
一.用户的类型 1.root管理员:所有权限(r w x) 2.文件拥有者(u):谁创建谁拥有 3.组 (g):用户组 4.其它用户(o):不属于用户组,也不是文件的创建者,不是管理员 ...
- Faster-RCNN用于场景文字检测训练测试过程记录(转)
[训练测试过程记录]Faster-RCNN用于场景文字检测 原创 2017年11月06日 20:09:00 标签: 609 编辑 删除 写在前面:github上面的Text-Detection-wit ...
- drf框架 - 三大认证组件 | 认证组件 | 权限组件 | 频率组件
RBAC 基于用户权限访问控制的认证 - Role-Based Access Control Django框架采用的是RBAC认证规则,RBAC认证规则通常会分为 三表规则.五表规则,Django采用 ...
- python的拷贝方式以及深拷贝,浅拷贝详解
python的拷贝方法有:切片方法, 工厂方法, 深拷贝方法, 浅拷贝方法等. 几种方法都可以实现拷贝操作, 具体区别在于两点:1.代码写法不同. 2.内存地址引用不同 代码演示: import co ...
- Kafka 通过python简单的生产消费实现
使用CentOS6.5.python3.6.kafkaScala 2.10 - kafka_2.10-0.8.2.2.tgz (asc, md5) 一.下载kafka 下载地址 https://ka ...
- Linux中三种SCSI target的介绍之LIO
版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog.csdn.net/scaleqiao/article/deta ...