spark学习记录-1
mapreduce的限制
适合“一趟”计算操作
很难组合和嵌套操作符号
无法表示迭代操作
========
由于复制、序列化和磁盘IO导致mapreduce慢
复杂的应用、流计算、内部查询都因为maprecude缺少有效的数据共享而变慢
======
迭代操作每一次复制都需要磁盘IO
内部查询和在线处理都需要磁盘IO
========spark的目标
在内存中保存更多的数据来提升性能
扩展maprecude模型来更好支持两个常见的分析应用:1,迭代算法(机器学习、图)2,内部数据挖掘
增强可编码性:1,多api库,2更少的代码
======
spark组成
spark sql,spark straming(real-time),graphx,mllib(meachine learning)
======
可以使用一下几种模式来运行:
在它的standalone cluster mode下
在hadoop yarn
在apache mesos
在kubernetes
活着在云上面
==========
数据来源:
1,本地文件file:///opt/httpd/logs/access_log
2,amazon S3
3,hadooop distributed filesystem
4,hbase,cassandra,etc
===========
spark 集群cluster
============
spark workflow
首先产生一个SparkContext对象(1,告诉spark怎么并且在哪里去访问集群;2,连接不同类型的集群管理者,egYARN,Mesos,本身的)
然后使用集群管理分配资源
最后使用Spark executer来运行计算过程,读取数据块
==============
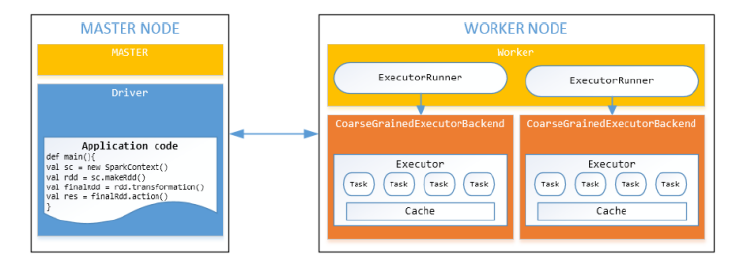
workers节点和执行者
worker节点是能运行executors的机器(1,每个worker一个jvm或者一个process,2每个worker可以产生多个executor)
Executor可以运行任务(1,在子jvm中运行,2在一个线程池中执行一个或者多个任务)
=========
Solution: Resilient Distributed Datasets
弹性分布式数据集
=========
RDD 操作
transformation:返回一个新的RDD,function包括:map,filter,flatMap,groupByKey,reduceByKey,aggragateByKey,filter,join
action:评估并且返回一个新的value,当一个RDD对象调用action方法时,处理查询的所有数据都会被同时计算,结果值返回;方法包括
reduce,collect,count,first,take,countByKey,foreach,saveAsTextFile
============
怎么使用RDD
1,从data source中产生一个RDD(1,利用现存的集合lists,arrays;2,RDD的变换;3,从hdfs或者其他数据系统)
2,使用RDD变换
3,使用RDD操作
=======
产生一个RDD
从hdfs,textfiles,amazons S3,hbase,序列号文件,其他的hadoop输入格式
(//从文件中产生一个RDD
JavaRDD<String> distFile = sc.textFile("data.txt",4)//rdd分为4个部分
)
(//从集合创建RDD
list<Integer> data = Arrays.aslist(1,2,3,4,5);
JavaRDD<Integer> distData = sc.parallelize(data);
)
========
spark学习记录-1的更多相关文章
- spark学习记录-2
spark编程模型 ====== spark如何工作的? 1.user应用产生RDD,操作变形,运行action操作 2.操作的结果在有向无环图DAG中 3.DAG被编译到stages阶段中 4.每一 ...
- Spark学习记录
SpringStrongGuo Hadoop与Spark Hadoop主要解决,海量数据的存储和海量数据的分析计算. Spark主要解决海量数据的分析计算. Spark运行模式 1)Local:运行在 ...
- spark学习笔记总结-spark入门资料精化
Spark学习笔记 Spark简介 spark 可以很容易和yarn结合,直接调用HDFS.Hbase上面的数据,和hadoop结合.配置很容易. spark发展迅猛,框架比hadoop更加灵活实用. ...
- [转]Spark学习之路 (三)Spark之RDD
Spark学习之路 (三)Spark之RDD https://www.cnblogs.com/qingyunzong/p/8899715.html 目录 一.RDD的概述 1.1 什么是RDD? ...
- 【转载】Spark学习——入门
要学习分布式以及数据分析.机器学习之类的,觉得可以通过一些实际的编码项目入手.最近Spark很火,也有不少招聘需要Spark,而且与传统的Hadoop相比,Spark貌似有一些优势.所以就以Spark ...
- Spark学习之Spark SQL(8)
Spark学习之Spark SQL(8) 1. Spark用来操作结构化和半结构化数据的接口--Spark SQL. 2. Spark SQL的三大功能 2.1 Spark SQL可以从各种结构化数据 ...
- Spark学习之数据读取与保存(4)
Spark学习之数据读取与保存(4) 1. 文件格式 Spark对很多种文件格式的读取和保存方式都很简单. 如文本文件的非结构化的文件,如JSON的半结构化文件,如SequenceFile结构化文件. ...
- Spark学习之键值对(pair RDD)操作(3)
Spark学习之键值对(pair RDD)操作(3) 1. 我们通常从一个RDD中提取某些字段(如代表事件时间.用户ID或者其他标识符的字段),并使用这些字段为pair RDD操作中的键. 2. 创建 ...
- Spark学习笔记2——RDD(上)
目录 Spark学习笔记2--RDD(上) RDD是什么? 例子 创建 RDD 并行化方式 读取外部数据集方式 RDD 操作 转化操作 行动操作 惰性求值 Spark学习笔记2--RDD(上) 笔记摘 ...
随机推荐
- [转]数据库性能优化(老Key)
数据库性能优化一:数据库自身优化(大数据量) https://www.cnblogs.com/AK2012/archive/2012/12/25/2012-1228.html 数据库性能优化二:数据库 ...
- unity获取ugui上鼠标位置
public class GetMousePos : MonoBehaviour { public Canvas canvas;//画布 private RectTransform rectTrans ...
- Ubuntu 用户权限相关命令
目标 用户 和 权限 的基本概念 用户管理 终端命令 组管理 终端命令 修改权限 终端命令 01. 用户 和 权限 的基本概念 1.1 基本概念 用户 是 Linux 系统工作中重要的一环,用户管理包 ...
- Linux环境变量$PATH
3. 使用env命令显示所有的环境变量 # env HOSTNAME=redbooks.safe.org PVM_RSH=/usr/bin/rsh Shell=/bin/bash TERM=xterm ...
- Tomcat启动超时设置
Tomcat启动超时设置: 处理方法: 1. 在server中找到当前Tomcat双击. 2.在视图中进行修改.(如下图:)
- Unable to guess the mime type as no guessers are available 2 9
做了一个上传图片的功能,在本地上传通过,服务器报 bug Unable to guess the mime type as no guessers are available(Did you enab ...
- 使用awstats分析nginx日志
1.awstats介绍 本文主要是记录centos6.5下安装配置awstats,并统计nginx访问日志 1.1 awstats介绍 awstats是一款日志统计工具,它使用Perl语言编写,可统计 ...
- SpringCloud2.0 Turbine 断路器集群监控 基础教程(九)
1.启动基础工程 1.1.启动[服务中心]集群,工程名称:springcloud-eureka-server 参考 SpringCloud2.0 Eureka Server 服务中心 基础教程(二) ...
- react native jpush跳转页面不成功解决方法
在点击事件时加入如下红色代码即可 import JPushModule from 'jpush-react-native'; ... componentDidMount() { // 新版本必需写回调 ...
- [software test - 001] Why we need software test?
/* This is a conclusion about the software testing job. */ /* Scope: middle level software tasks, ...