Video Architecture Search
Video Architecture Search
2019-10-20 06:48:26
This blog is from: https://ai.googleblog.com/2019/10/video-architecture-search.html
Posted by Michael S. Ryoo, Research Scientist and AJ Piergiovanni, Student Researcher, Robotics at Google
Video understanding is a challenging problem. Because a video contains spatio-temporal data, its feature representation is required to abstract both appearance and motion information. This is not only essential for automated understanding of the semantic content of videos, such as web-video classification or sport activity recognition, but is also crucial for robot perception and learning. Just like humans, an input from a robot’s camera is seldom a static snapshot of the world, but takes the form of a continuous video.
The abilities of today’s deep learning models are greatly dependent on their neural architectures. Convolutional neural networks (CNNs) for videos are normally built by manually extending known 2D architectures such as Inception and ResNet to 3D or by carefully designing two-stream CNN architectures that fuse together both appearance and motion information. However, designing an optimal video architecture to best take advantage of spatio-temporal information in videos still remains an open problem. Although neural architecture search (e.g., Zoph et al, Real et al) to discover good architectures has been widely explored for images, machine-optimized neural architectures for videos have not yet been developed. Video CNNs are typically computation- and memory-intensive, and designing an approach to efficiently search for them while capturing their unique properties has been difficult.
In response to these challenges, we have conducted a series of studies into automatic searches for more optimal network architectures for video understanding. We showcase three different neural architecture evolution algorithms: learning layers and their module configuration (EvaNet); learning multi-stream connectivity (AssembleNet); and building computationally efficient and compact networks (TinyVideoNet). The video architectures we developed outperform existing hand-made models on multiple public datasets by a significant margin, and demonstrate a 10x~100x improvement in network runtime.
EvaNet: The first evolved video architectures
EvaNet, which we introduce in “Evolving Space-Time Neural Architectures for Videos” at ICCV 2019, is the very first attempt to design neural architecture search for video architectures. EvaNet is a module-level architecture search that focuses on finding types of spatio-temporal convolutional layers as well as their optimal sequential or parallel configurations. An evolutionary algorithm with mutation operators is used for the search, iteratively updating a population of architectures. This allows for parallel and more efficient exploration of the search space, which is necessary for video architecture search to consider diverse spatio-temporal layers and their combinations. EvaNet evolves multiple modules (at different locations within the network) to generate different architectures.
Our experimental results confirm the benefits of such video CNN architectures obtained by evolving heterogeneous modules. The approach often finds that non-trivial modules composed of multiple parallel layers are most effective as they are faster and exhibit superior performance to hand-designed modules. Another interesting aspect is that we obtain a number of similarly well-performing, but diverse architectures as a result of the evolution, without extra computation. Forming an ensemble with them further improves performance. Due to their parallel nature, even an ensemble of models is computationally more efficient than the other standard video networks, such as (2+1)D ResNet. We have open sourced the code.
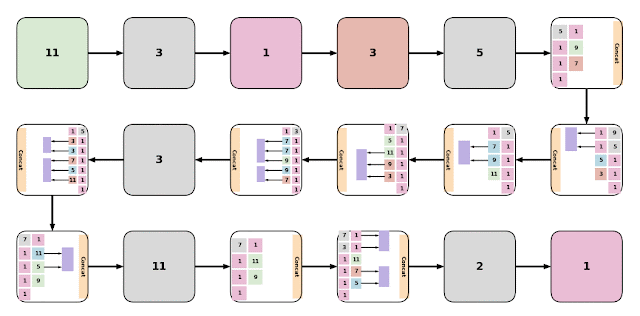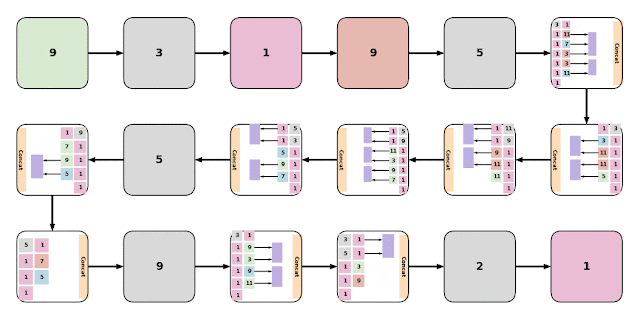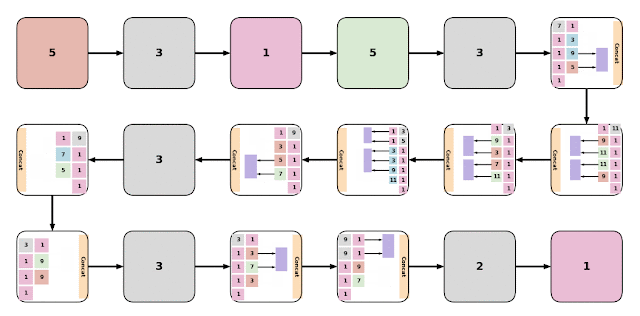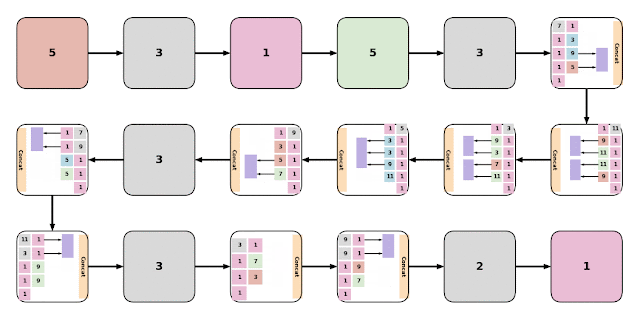 |
| Examples of various EvaNet architectures. Each colored box (large or small) represents a layer with the color of the box indicating its type: 3D conv. (blue), (2+1)D conv. (orange), iTGM (green), max pooling (grey), averaging (purple), and 1x1 conv. (pink). Layers are often grouped to form modules (large boxes). Digits within each box indicate the filter size. |
AssembleNet: Building stronger and better (multi-stream) models
In “AssembleNet: Searching for Multi-Stream Neural Connectivity in Video Architectures”, we look into a new method of fusing different sub-networks with different input modalities (e.g., RGB and optical flow) and temporal resolutions. AssembleNet is a “family” of learnable architectures that provide a generic approach to learn the “connectivity” among feature representations across input modalities, while being optimized for the target task. We introduce a general formulation that allows representation of various forms of multi-stream CNNs as directed graphs, coupled with an efficient evolutionary algorithm to explore the high-level network connectivity. The objective is to learn better feature representations across appearance and motion visual clues in videos. Unlike previous hand-designed two-stream models that use late fusion or fixed intermediate fusion, AssembleNet evolves a population of overly-connected, multi-stream, multi-resolution architectures while guiding their mutations by connection weight learning. We are looking at four-stream architectures with various intermediate connections for the first time — 2 streams per RGB and optical flow, each one at different temporal resolutions.
The figure below shows an example of an AssembleNet architecture, found by evolving a pool of random initial multi-stream architectures over 50~150 rounds. We tested AssembleNet on two very popular video recognition datasets: Charades and Moments-in-Time (MiT). Its performance on MiT is the first above 34%. The performances on Charades is even more impressive at 58.6% mean Average Precision (mAP), whereas previous best known results are 42.5 and 45.2.
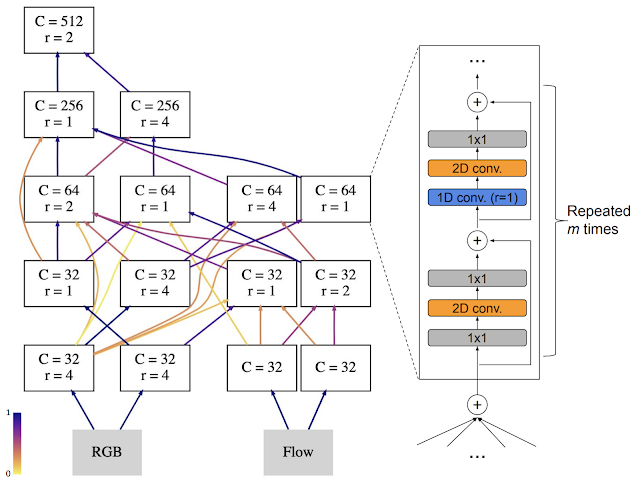 |
| The representative AssembleNet model evolved using the Moments-in-Time dataset. A node corresponds to a block of spatio-temporal convolutional layers, and each edge specifies their connectivity. Darker edges mean stronger connections. AssembleNet is a family of learnable multi-stream architectures, optimized for the target task. |
 |
| A figure comparing AssembleNet with state-of-the-art, hand-designed models on Charades (left) and Moments-in-Time (right) datasets. AssembleNet-50 or AssembleNet-101 has an equivalent number of parameters to a two-stream ResNet-50 or ResNet-101. |
Tiny Video Networks: The fastest video understanding networks
In order for a video CNN model to be useful for devices operating in a real-world environment, such as that needed by robots, real-time, efficient computation is necessary. However, achieving state-of-the-art results on video recognition tasks currently requires extremely large networks, often with tens to hundreds of convolutional layers, that are applied to many input frames. As a result, these networks often suffer from very slow runtimes, requiring at least 500+ ms per 1-second video snippet on a contemporary GPU and 2000+ ms on a CPU. In Tiny Video Networks, we address this by automatically designing networks that provide comparable performance at a fraction of the computational cost. Our Tiny Video Networks (TinyVideoNets) achieve competitive accuracy and run efficiently, at real-time or better speeds, within 37 to 100 ms on a CPU and 10 ms on a GPU per ~1 second video clip, achieving hundreds of times faster speeds than the other human-designed contemporary models.
These performance gains are achieved by explicitly considering the model run-time during the architecture evolution and forcing the algorithm to explore the search space while including spatial or temporal resolution and channel size to reduce computations. The below figure illustrates two simple, but very effective architectures, found by TinyVideoNet. Interestingly the learned model architectures have fewer convolutional layers than typical video architectures: Tiny Video Networks prefers lightweight elements, such as 2D pooling, gating layers, and squeeze-and-excitation layers. Further, TinyVideoNet is able to jointly optimize parameters and runtime to provide efficient networks that can be used by future network exploration.
 |
| TinyVideoNet (TVN) architectures evolved to maximize the recognition performance while keeping its computation time within the desired limit. For instance, TVN-1 (top) runs at 37 ms on a CPU and 10ms on a GPU. TVN-2 (bottom) runs at 65ms on a CPU and 13ms on a GPU. |
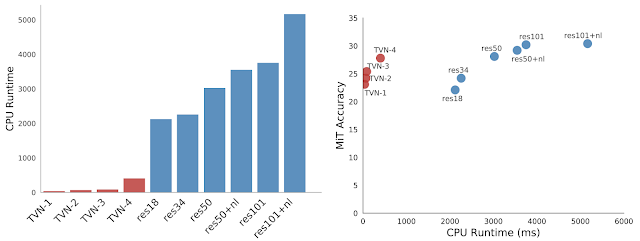 |
| CPU runtime of TinyVideoNet models compared to prior models (left) and runtime vs. model accuracy of TinyVideoNets compared to (2+1)D ResNet models (right). Note that TinyVideoNets take a part of this time-accuracy space where no other models exist, i.e., extremely fast but still accurate. |
Conclusion
To our knowledge, this is the very first work on neural architecture search for video understanding. The video architectures we generate with our new evolutionary algorithms outperform the best known hand-designed CNN architectures on public datasets, by a significant margin. We also show that learning computationally efficient video models, TinyVideoNets, is possible with architecture evolution. This research opens new directions and demonstrates the promise of machine-evolved CNNs for video understanding.
Acknowledgements
This research was conducted by Michael S. Ryoo, AJ Piergiovanni, and Anelia Angelova. Alex Toshev and Mingxing Tan also contributed to this work. We thank Vincent Vanhoucke, Juhana Kangaspunta, Esteban Real, Ping Yu, Sarah Sirajuddin, and the Robotics at Google team for discussion and support.
Video Architecture Search的更多相关文章
- 论文笔记:Progressive Neural Architecture Search
Progressive Neural Architecture Search 2019-03-18 20:28:13 Paper:http://openaccess.thecvf.com/conten ...
- 论文笔记:Auto-DeepLab: Hierarchical Neural Architecture Search for Semantic Image Segmentation
Auto-DeepLab: Hierarchical Neural Architecture Search for Semantic Image Segmentation2019-03-18 14:4 ...
- 论文笔记:Fast Neural Architecture Search of Compact Semantic Segmentation Models via Auxiliary Cells
Fast Neural Architecture Search of Compact Semantic Segmentation Models via Auxiliary Cells 2019-04- ...
- (转)Illustrated: Efficient Neural Architecture Search ---Guide on macro and micro search strategies in ENAS
Illustrated: Efficient Neural Architecture Search --- Guide on macro and micro search strategies in ...
- (转)The Evolved Transformer - Enhancing Transformer with Neural Architecture Search
The Evolved Transformer - Enhancing Transformer with Neural Architecture Search 2019-03-26 19:14:33 ...
- 论文笔记:ProxylessNAS: Direct Neural Architecture Search on Target Task and Hardware
ProxylessNAS: Direct Neural Architecture Search on Target Task and Hardware 2019-03-19 16:13:18 Pape ...
- 论文笔记:DARTS: Differentiable Architecture Search
DARTS: Differentiable Architecture Search 2019-03-19 10:04:26accepted by ICLR 2019 Paper:https://arx ...
- 论文笔记系列-DARTS: Differentiable Architecture Search
Summary 我的理解就是原本节点和节点之间操作是离散的,因为就是从若干个操作中选择某一个,而作者试图使用softmax和relaxation(松弛化)将操作连续化,所以模型结构搜索的任务就转变成了 ...
- 论文笔记系列-Simple And Efficient Architecture Search For Neural Networks
摘要 本文提出了一种新方法,可以基于简单的爬山过程自动搜索性能良好的CNN架构,该算法运算符应用网络态射,然后通过余弦退火进行短期优化运行. 令人惊讶的是,这种简单的方法产生了有竞争力的结果,尽管只需 ...
随机推荐
- git 从远程克隆代码并实现分支开发,合并分支,上传本地代码到远程
首先确认你已经安装了git 1.克隆远程代码到本地的操作 git clone 地址 打开git操作命令行 鼠标右键点击 复制需要克隆的项目的地址类似下面的ssh 输入命令进行 ...
- SparkStreaming之checkpoint检查点
一.简介 流应用程序必须保证7*24全天候运行,因此必须能够适应与程序逻辑无关的故障[例如:系统故障.JVM崩溃等].为了实现这一点,SparkStreaming需要将足够的信息保存到容错存储系统中, ...
- jQuery循环之each()
/** *定义和用法:$(selector).each(function(index,element)) *each()函数会对每个匹配到的元素运行函数(返回false可终止循环). *each()函 ...
- PTA 树的遍历(根据后序中序遍历输出层序遍历)
给定一棵二叉树的后序遍历和中序遍历,请你输出其层序遍历的序列.这里假设键值都是互不相等的正整数. 输入格式:输入第一行给出一个正整数N(≤30),是二叉树中结点的个数.第二行给出其后序遍历序列.第 ...
- django云端留言板
1.创建应用 django-admin startproject cloudms cd cloudms python manage.py startapp msgapp 2.创建模板文件 在cloud ...
- P1486 [NOI2004]郁闷的出纳员[权值线段树]
权值线段树. 我们只用维护一个人是否存在,以及他当前排名,而不关心工资的具体值,这个可以直接算. 不难发现,如果不考虑新的员工,所有员工的工资的差值是不变的. 而加进来一个新的员工时,其工资为\(x\ ...
- 1062 Error 'Duplicate entry '1438019' for key 'PRIMARY'' on query
mysql主从库同步错误:1062 Error 'Duplicate entry '1438019' for key 'PRIMARY'' on querymysql主从库在同步时会发生1062 La ...
- JPA(java持久化API)的环境的搭建
因为我使用的是java工程 所以需要引入的依赖有: <properties> <project.build.sourceEncoding>UTF-8</project.b ...
- 后端将Long类型数据传输到前端出现精度丢失的问题
当将超过16位的数字传输到前端的时候,就会出现精度丢失的问题,然后我按照网上的几种方法实验的时候,只有一种方法成功了.可能是因为环境等方面的问题. 我这里成功是因为:最后使用的是配置mvc的方式,然后 ...
- Lombok 学习资料
Lombok 学习资料 网址 Lombok 官方网站 https://projectlombok.org/features/all Lombok:让JAVA代码更优雅 http://blog.didi ...