hadoop综合
对CSV文件进行预处理生成无标题文本文件,将爬虫大作业产生的csv文件上传到HDFS
首先,我们需要在本地中创建一个/usr/local/bigdatacase/dataset文件夹,具体的步骤为:
① cd /usr/local
② sudo mkdir bigdatacase
③ cd bigdatacase/
④ sudo mkdir dataset
⑤ cd dataset/
如下图所示:

其次,我们把lagoupy.csv文件放到下载这个文件夹中,并使用命令把lagoupy.csv文件拷贝到我们刚刚所创建的文件夹中,具体步骤如下:
① sudo cp /home/chen/下载/lagoupy.csv /usr/local/bigdatacase/dataset/ #把lagoupy.csv文件拷到刚刚所创建的文件夹中
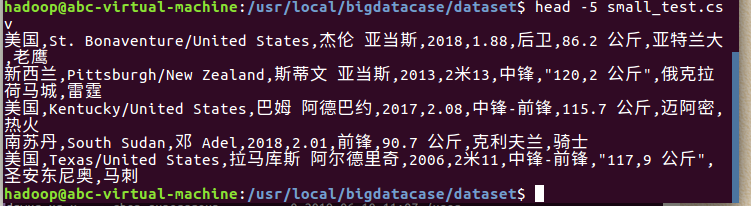
② head -5 small_test.csv #查看这个文件的前五行

对CSV文件进行预处理生成无标题文本文件,步骤如下:
① sudo sed -i '1d' lagoupy.csv #删除第一行记录
② head -5 small_test.csv #查看前五行记录
如下图所示:
接着,启动hadoop,步骤如下:
① start-all.sh #启动hadoop
② jps #查看hadoop是否启动成功
如下图所示:

最后,我们把本地的文件上传至HDFS中,步骤如下:
① hdfs dfs -mkdir -p /bigdatacase/dataset #在hdfs上新建/bigdatacase/dataset
② hdfs dfs -ls /
③ hdfs dfs -put ./lagoupy.csv /bigdatacase/dataset #把本地文件small_test.csv上传至hdfs中
④ hdfs dfs -ls /bigdatacase/dataset #查看
⑤ hdfs dfs -cat /bigdatacase/dataset/small_test.csv | head -5 #查看hdfs中small_test.csv的前五行
如下图所示:

把hdfs中的文本文件最终导入到数据仓库Hive中
首先,启动hive,步骤如下:
① service mysql start #启动mysql数据库
② cd /usr/local/hive
③ ./bin/hive #启动hive
如下图所示:

① create database db; -- 创建数据库dbpy
② use db;
③ create external table labling
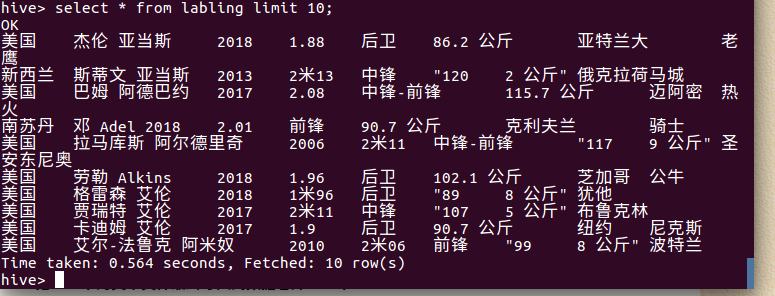
④ select * from labling limit 10; -- 查看lagou_py中前10行的数据
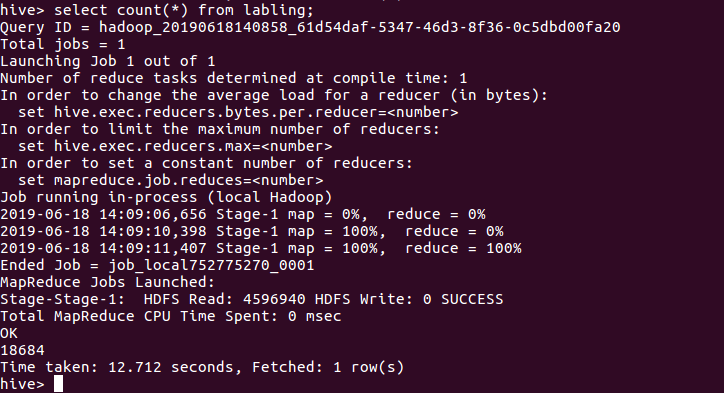
查询条数统计分析
用聚合函数count()计算出表内有多少条行数据 hive> select count(*) from labling;
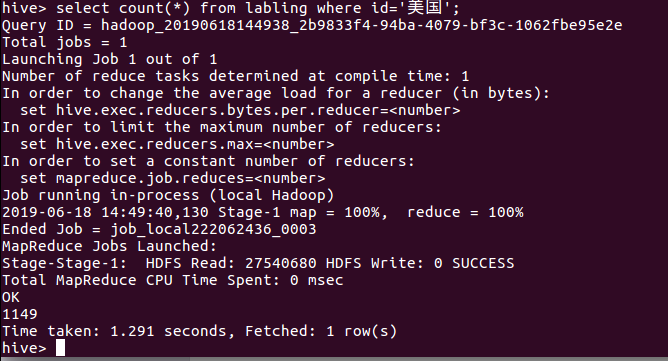
美国国籍的球员数:
美国国籍的球员:
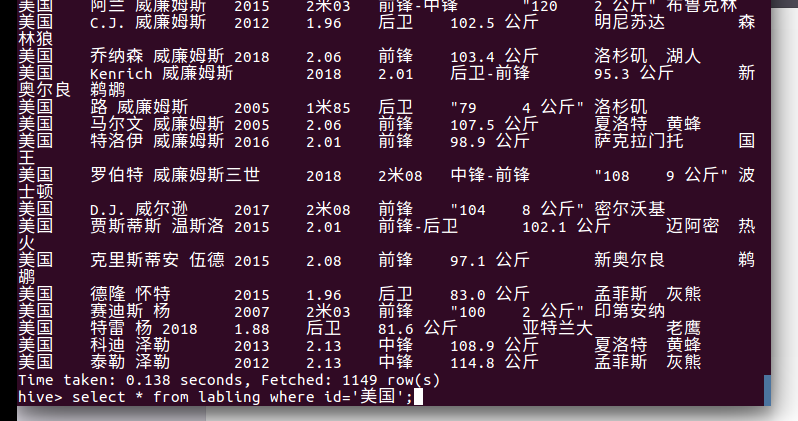
查询老鹰的球员:
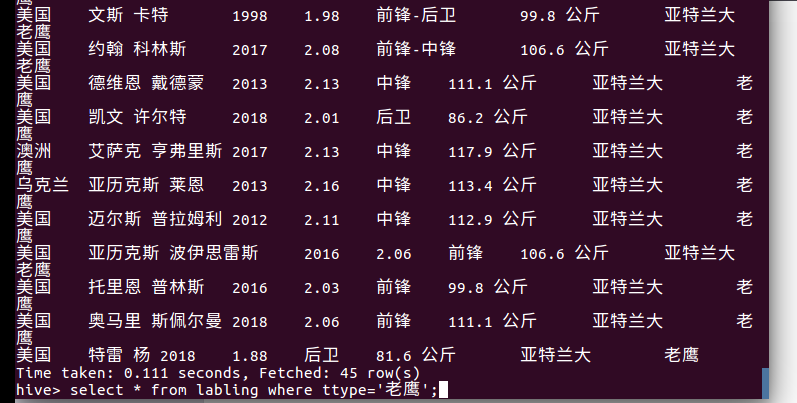
查询老鹰的球员数:
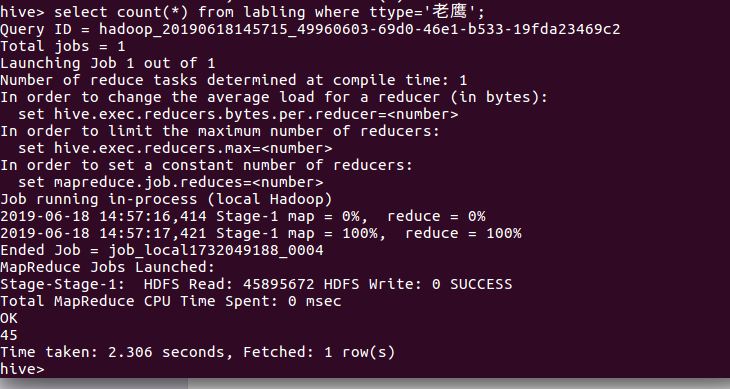
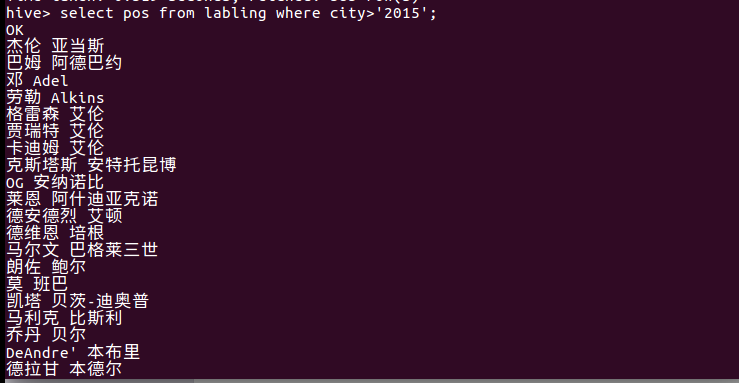
查询球员2015年以后进入NBA的人数:
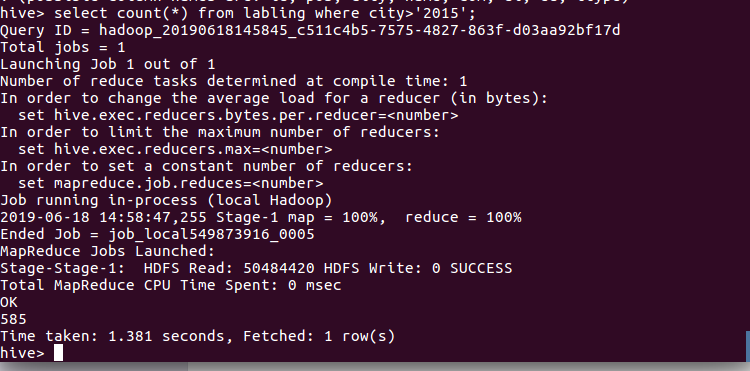
查询2015年以后进入NBA球员的名字
hadoop综合的更多相关文章
- Hadoop综合大作业
Hadoop综合大作业 要求: 用Hive对爬虫大作业产生的文本文件(或者英文词频统计下载的英文长篇小说)词频统计. 用Hive对爬虫大作业产生的csv文件进行数据分析 1. 用Hive对爬虫大作业产 ...
- Hadoop 综合揭秘——HBase的原理与应用
前言 现今互联网科技发展日新月异,大数据.云计算.人工智能等技术已经成为前瞻性产品,海量数据和超高并发让传统的 Web2.0 网站有点力不从心,暴露了很多难以克服的问题.为此,Google.Amazo ...
- Hadoop 综合揭秘——MapReduce 基础编程(介绍 Combine、Partitioner、WritableComparable、WritableComparator 使用方式)
前言 本文主要介绍 MapReduce 的原理及开发,讲解如何利用 Combine.Partitioner.WritableComparator等组件对数据进行排序筛选聚合分组的功能.由于文章是针对开 ...
- 大数据应用期末总评——Hadoop综合大作业
作业要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339 Hadoop综合大作业 要求: 1.将爬虫大作业产生的csv文件 ...
- 【大数据应用期末总评】Hadoop综合大作业
作业要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339 一.Hadoop综合大作业 要求: 1.将爬虫大作业产生的csv ...
- 《Hadoop综合大作业》
作业要求来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339 我主要的爬取内容是关于热门微博文章“996”与日剧<我要 ...
- 菜鸟学IT之Hadoop综合大作业
Hadoop综合大作业 作业来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3363 1.将爬虫大作业产生的csv文件上传到HDF ...
- 大数据应用期末总评Hadoop综合大作业
作业要求来源于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339 1.将爬虫大作业产生的csv文件上传到HDFS 此次作业选取的 ...
- Hadoop综合大作业1
本次作业来源于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3363 一.课程评分标准: 分数组成: 考勤 10 平时作业 30 爬 ...
- 【大数据应用技术】作业十二|Hadoop综合大作业
本次作业的要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339 前言 本次作业是在<爬虫大作业>的基础上进行的 ...
随机推荐
- vue+element 通过ref修改一切硬核样式~
今天的需求是这样的,点击按钮,弹出一个Popover 弹出框 然后老大说,把弹出框往下移移,box-shadow值设的大一些... 然后就查看elenent的Popover文档,并没有方法,而且这个组 ...
- Mac音频播放
Mac音频播放 audioqueue播放pcm数据 http://msching.github.io/blog/2014/08/02/audio-in-ios-5/ audiounit播放pcm数据 ...
- [LeetCode] 198. 打家劫舍II ☆☆☆(动态规划)
描述 你是一个专业的小偷,计划偷窃沿街的房屋,每间房内都藏有一定的现金.这个地方所有的房屋都围成一圈,这意味着第一个房屋和最后一个房屋是紧挨着的.同时,相邻的房屋装有相互连通的防盗系统,如果两间相邻的 ...
- Linux命令——screen
参考:linux 技巧:使用 screen 管理你的远程会话 How to use GNU screen - the terminal multiplexer - linux
- Kali下的内网劫持(四)
在前面我都演示的是在Kali下用命令行的形式将在目标主机上操作的用户的信息捕获的过程,那么接下来我将演示在Kali中用图形界面的ettercap对目标主机的用户进行会话劫持: 首先启动图形界面的ett ...
- python笔记35-装饰器
前言 python装饰器本质上就是一个函数,它可以让其他函数在不需要做任何代码变动的前提下增加额外的功能,装饰器的返回值也是一个函数对象. 很多python初学者学到面向对象类和方法是一道大坎,那么p ...
- Go语言 - 函数 | 作用域 | 匿名函数 | 闭包 | 内置函数
函数是组织好的.可重复使用的.用于执行指定任务的代码块.本文介绍了Go语言中函数的相关内容. 介绍 Go语言中支持函数.匿名函数和闭包,并且函数在Go语言中属于“一等公民”. 函数可以赋值给变量 函数 ...
- c#中的多态学习总结
c#的多台方法,大体上和c++的类似,但是有点区别的,我这里刚刚初学,因此把重点记录下. 多态是同一个行为具有多个不同表现形式或形态的能力. 多态性意味着有多重形式.在面向对象编程范式中,多态性往往表 ...
- lxml_time_代理
import requests from pyquery import PyQuery as pq import json import jsonpath from lxml import etree ...
- [学习笔记] Miller-Rabin 质数测试
Miller-Rabin 事先声明,因为菜鸡Hastin知识水平有限就是菜,因此语言可能不是特别规范,仅供理解. step 0 问一个数\(p\)是否为质数,\(p<=10^{18}\). 一个 ...