【ARM-Linux开发】Linux模块机制浅析
Linux模块机制浅析
Linux允许用户通过插入模块,实现干预内核的目的。一直以来,对linux的模块机制都不够清晰,因此本文对内核模块的加载机制进行简单地分析。
模块的Hello World!
我们通过创建一个简单的模块进行测试。首先是源文件main.c和Makefile。
florian@florian-pc:~/module$ cat main.c
#include<linux/module.h>
#include<linux/init.h>
static int __init init(void)
{
printk("Hi module!\n");
return 0;
}
static void __exit exit(void)
{
printk("Bye module!\n");
}
module_init(init);
module_exit(exit);
其中init为模块入口函数,在模块加载时被调用执行,exit为模块出口函数,在模块卸载被调用执行。
florian@florian-pc:~/module$ cat Makefile
obj-m += main.o
#generate the path
CURRENT_PATH:=$(shell pwd)
#the current kernel version number
LINUX_KERNEL:=$(shell uname -r)
#the absolute path
LINUX_KERNEL_PATH:=/usr/src/linux-headers-$(LINUX_KERNEL)
#complie object
all:
make -C 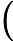


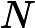
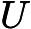





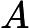
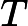
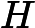

 (LINUXKERNELPATH)M=(CURRENT_PATH)
(LINUXKERNELPATH)M=(CURRENT_PATH)
modules
#clean
clean:
make -C (LINUXKERNELPATH)M=(CURRENT_PATH)
clean
其中,obj-m指定了目标文件的名称,文件名需要和源文件名相同(扩展名除外),以便于make自动推导。
然后使用make命令编译模块,得到模块文件main.ko。
florian@florian-pc:~/module$ make
make -C /usr/src/linux-headers-2.6.35-22-generic M=/home/florian/module modules
make[1]: 正在进入目录 `/usr/src/linux-headers-2.6.35-22-generic'
Building modules, stage 2.
MODPOST 1 modules
make[1]:正在离开目录 `/usr/src/linux-headers-2.6.35-22-generic'
使用insmod和rmmod命令对模块进行加载和卸载操作,并使用dmesg打印内核日志。
florian@florian-pc:~/module$ sudo insmod main.ko;dmesg | tail -1
[31077.810049] Hi module!
florian@florian-pc:~/module$ sudo rmmod main.ko;dmesg | tail -1
[31078.960442] Bye module!
通过内核日志信息,可以看出模块的入口函数和出口函数都被正确调用执行。
模块文件
使用readelf命令查看一下模块文件main.ko的信息。
florian@florian-pc:~/module$ readelf -h main.ko
ELF Header:
Magic: 7f 45 4c 46 01 01 01 00 00 00 00 00 00 00 00 00
Class: ELF32
Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: UNIX - System V
ABI Version: 0
Type: REL (Relocatable file)
Machine: Intel 80386
Version: 0x1
Entry point address: 0x0
Start of program headers: 0 (bytes into file)
Start of section headers: 1120 (bytes into file)
Flags: 0x0
Size of this header: 52 (bytes)
Size of program headers: 0 (bytes)
Number of program headers: 0
Size of section headers: 40 (bytes)
Number of section headers: 19
Section header string table index: 16
我们发现main.ko的文件类型为可重定位目标文件,这和一般的目标文件格式没有任何区别。我们知道,目标文件是不能直接执行的,它需要经过链接器的地址空间分配、符号解析和重定位的过程,转化为可执行文件才能执行。
那么,内核将main.ko加载后,是否对其进行了链接呢?
模块数据结构
首先,我们了解一下模块的内核数据结构。
linux3.5.2/kernel/module.h:220
struct module
{
……
/* Startup function. */
int (*init)(void);
……
/* Destruction function. */
void (*exit)(void);
……
};
模块数据结构的init和exit函数指针记录了我们定义的模块入口函数和出口函数。
模块加载
模块加载由内核的系统调用init_module完成。
linux3.5.2/kernel/module.c:3009
/* This is where the real work happens */
SYSCALL_DEFINE3(init_module, void __user *, umod,
unsigned long, len, const char __user *, uargs)
{
struct module *mod;
int ret = 0;
……
/* Do all the hard work */
mod = load_module(umod, len, uargs);//模块加载
……
/* Start the module */
if (mod->init != NULL)
ret = do_one_initcall(mod->init);//模块init函数调用
……
return 0;
}
系统调用init_module由SYSCALL_DEFINE3(init_module...)实现,其中有两个关键的函数调用。load_module用于模块加载,do_one_initcall用于回调模块的init函数。
函数load_module的实现为。
linux3.5.2/kernel/module.c:2864
/* Allocate and load the module: note that size of section 0 is always
zero, and we rely on this for optional sections. */
static struct module *load_module(void __user *umod,
unsigned long len,
const char __user *uargs)
{
struct load_info info = { NULL, };
struct module *mod;
long err;
……
/* Copy in the blobs from userspace, check they are vaguely sane. */
err = copy_and_check(&info, umod, len, uargs);//拷贝到内核
if (err)
return ERR_PTR(err);
/* Figure out module layout, and allocate all the memory. */
mod = layout_and_allocate(&info);//地址空间分配
if (IS_ERR(mod)) {
err = PTR_ERR(mod);
goto free_copy;
}
……
/* Fix up syms, so that st_value is a pointer to location. */
err = simplify_symbols(mod, &info);//符号解析
if (err < 0)
goto free_modinfo;
err = apply_relocations(mod, &info);//重定位
if (err < 0)
goto free_modinfo;
……
}
函数load_module内有四个关键的函数调用。copy_and_check将模块从用户空间拷贝到内核空间,layout_and_allocate为模块进行地址空间分配,simplify_symbols为模块进行符号解析,apply_relocations为模块进行重定位。
由此可见,模块加载时,内核为模块文件main.ko进行了链接的过程!
至于函数do_one_initcall的实现就比较简单了。
linux3.5.2/kernel/init.c:673
int __init_or_module do_one_initcall(initcall_t fn)
{
int count = preempt_count();
int ret;
if (initcall_debug)
ret = do_one_initcall_debug(fn);
else
ret = fn();//调用init module
……
return ret;
}
即调用了模块的入口函数init。
模块卸载
模块卸载由内核的系统调用delete_module完成。
linux3.5.2/kernel/module.c:768
SYSCALL_DEFINE2(delete_module, const char __user *, name_user,
unsigned int, flags)
{
struct module *mod;
char name[MODULE_NAME_LEN];
int ret, forced = 0;
……
/* Final destruction now no one is using it. */
if (mod->exit != NULL)
mod->exit();//调用exit module
……
free_module(mod);//卸载模块
……
}
通过回调exit完成模块的出口函数功能,最后调用free_module将模块卸载。
结论
如此看来,内核模块其实并不神秘。传统的用户程序需要编译为可执行程序才能执行,而模块程序只需要编译为目标文件的形式便可以加载到内核,有内核实现模块的链接,将之转化为可执行代码。同时,在内核加载和卸载的过程中,会通过函数回调用户定义的模块入口函数和模块出口函数,实现相应的功能。
参考资料
【ARM-Linux开发】Linux模块机制浅析的更多相关文章
- Linux模块机制浅析
Linux模块机制浅析 Linux允许用户通过插入模块,实现干预内核的目的.一直以来,对linux的模块机制都不够清晰,因此本文对内核模块的加载机制进行简单地分析. 模块的Hello World! ...
- Linux模块机制浅析_转
Linux模块机制浅析 转自:http://www.cnblogs.com/fanzhidongyzby/p/3730131.htmlLinux允许用户通过插入模块,实现干预内核的目的.一直以来,对l ...
- webpack模块机制浅析【一】
webpack模块机制浅析[一] 今天看了看webpack打包后的代码,所以就去分析了下代码的运行机制. 下面这段代码是webpack打包后的最基本的形式,可以说是[骨架] (function(roo ...
- 【Linux开发】Linux模块机制浅析
Linux允许用户通过插入模块,实现干预内核的目的.一直以来,对linux的模块机制都不够清晰,因此本文对内核模块的加载机制进行简单地分析. 模块的Hello World! 我们通过创建一个简单的模块 ...
- Linux内核(6) - 模块机制与“Hello World!
有一种感动,叫内牛满面,有一种机制,叫模块机制.显然,这种模块机制给那些Linux的发烧友们带来了方便,因为模块机制意味着人们可以把庞大的Linux内核划分为许许多多个小的模块.对于编写设备驱动程序的 ...
- 通过Anuglar Material串串学客户端开发 - NodeJS模块机制之Module.Exports
module.exports 前文讲到在Angular Material的第二个编译文件docs/gulpfile.js中却看到了一个奇怪的东西module.exports那么module.expor ...
- 【linux驱动笔记】linux模块机制浅析
1. 模块module 操作系统分微内核和宏内核,微内核优点,可以使操作系统仅作很少的事,其它事情如网络处理等都作为应用程序来实现,微内核精简的同时,必然带来性能的下降.而linux的宏内核设 ...
- 应聘linux/ARM嵌入式开发岗位
**************************************************************** 因为发在中华英才和智联招聘没有人采我所以我 在这里发布我的个人简历希望 ...
- linux下nginx模块开发入门
本文模块编写参考http://blog.codinglabs.org/articles/intro-of-nginx-module-development.html 之前讲了nginx的安装,算是对n ...
随机推荐
- js定时器关闭,js定时器停止,一次关闭所有正在运行的定时器,自定义函数clearIntervals()一次关闭所有正在运行的定时器
js定时器关闭,一次关闭所有正在运行的定时器,自定义函数clearIntervals()一次关闭所有正在运行的定时器,原理:利用数组存储定时器id,然后遍历数组,关闭定时器 附上页面的截图,代码在截图 ...
- what-is-the-difference-between-type-and-class
Inspired by Wikipedia... In type theory terms; A type is an abstract interface. Types generally repr ...
- matlab基础向7-8:画图
1.画直角坐标系的二维图 画直线: x1=[1 2 3]; y1=[4 5 6]; plot(x1,y1);%斜率为1的直线,穿过(1,4)(2,5)(3,6) 画抛物线y=x*x(-3<=x& ...
- 68-Flutter中极光推送的使用
1.申请极光账号和建立应用 极光推送的官方网址为:https://www.jiguang.cn/ 注册好后,进入'服务中心',然后再进入'开发者平台',点击创建应用. 这时候会出现新页面,让你填写“应 ...
- Numpy | 04 数组属性
NumPy 数组的维数称为秩(rank),一维数组的秩为 1,二维数组的秩为 2,以此类推. 在 NumPy中,每一个线性的数组称为是一个轴(axis),也就是维度(dimensions).比如说,二 ...
- Linux中tune2fs命令的-o选项
debug 启用此文件系统的调试代码. bsdgroups 在创建新文件时模拟BSD行为:它们将使用创建它们的目录.标准系统V的行为是默认情况下,新创建的文件采用当前进程的fsgid,除非目录设置了s ...
- Ubuntu下手动安装vscode
Ubuntu下手动安装vscode1.下载vscodewget https://vscode.cdn.azure.cn/stable/553cfb2c2205db5f15f3ee8395bbd5cf0 ...
- ffmpeg结合SDL编写播放器(三)
接下来是解析影片的帧 /*** project.c ***/ #include<stdio.h> #include<libavcodec/avcodec.h> #include ...
- 在微信小程序页面间传递数据总结
在微信小程序页面间传递数据 原文链接:https://www.jianshu.com/p/dae1bac5fc75 在开发微信小程序过程之中,遇到这么一些需要在微信小程序页面之间进行数据的传递的情况, ...
- GSEA 基因集富集分析
http://software.broadinstitute.org/gsea/index.jsp GSEA(Gene Set Enrichment Analysis)是一种生物信息学的计算方法,用于 ...