Cortex_m7内核cache深入了解和应用
一,cache概述
从下图可以看出,从M7内核才开始有的cache,这对于从M0,M3,M4一路走来的小伙伴来说,多了一个cache就多了一个障碍。

Cortex-M7 core with 32K/32K L1 I/D-Cache!这提供了极高的性能,代码无论是从芯片上的内存,外部闪存,还是外部内存运行!介绍种类包括:L1 cache, memory types, attributes and MPU(Memory Protection Unit). 指导用户如何使用缓存开发以正确和高性能方式运行应用程序。
cache价值:由于对这些存储器的子系统,比如 OCRAM,FlexSPI,SEMC的访问可能需要多个周期(特别是在具有多个等待状态的外部存储器接口上),因此L1缓存的设计目的是加快对存储器的读/写操作。这带来了很大的性能提升。
I/DTCM(FlexRAM banks configured as TCM)由CPU核直接访问,绕过L1缓存。因此,建议将关键代码和数据放入TCM中,就像向量表vector table一样
flush:在有的书中称作invalidate
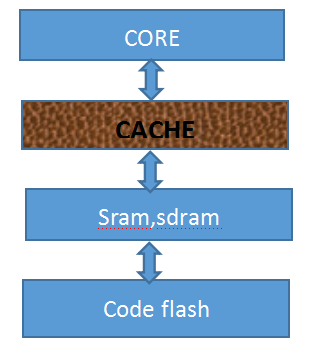
存贮器结构如下图:
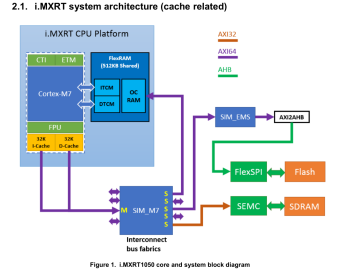
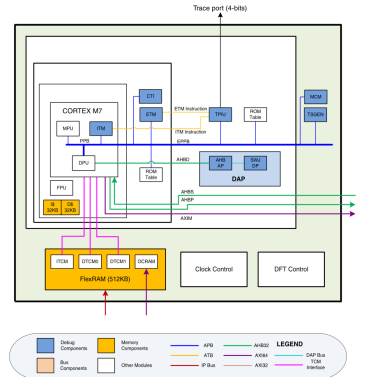
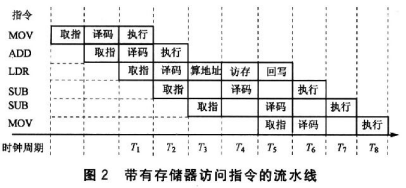
Cortex-M7是6级双发射流水线,下图是一个示意图。
高速缓存cache基础知识:
程序执行的局部规律性包括时间局部规律性和空间局部规律性。
时间局部规律性:在程序执行过程中,刚刚被访问的信息可能很快被再次访问,典型情况是程序中存在大量的循环。
空间局部规律性:在程序执行过程中,那些与被访问的地址相临近的信息也有可能很快被访问。典型情况是程序中存在大量的顺序执行。
按照程序执行的“局部性规律”,程序中的数据或者代码被访问后,该数据和代码以及邻近的数据代码近期再被访问的概率要远大于,近期未被访问的数据或者代码被访问的概率。因此,当数据或代码被访问后,被认为是经常访问的数据和代码,将被存入到cache,当再次访问该数据或者代码时直接从该cache读取数据或者代码的值,而不是到内存中重新读取。
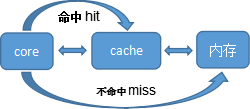
有了cache后,core对内存中的数据访问流程如下图所示:
二.Cortex-M7内核的L1 Cache
L1 Cache由多行内存区组成,每行有32字节,每行都配有一个地址标签。
数据缓冲DCache:是每4行为一组,称为4-way set associative。
指令缓冲区ICache:是2行为一组, 称为2-way set-associative
这样节省地址标签,不用每个行都标记一个地址。
Cache hit:要访问的数据/指令在cache里面.
Cache miss:要访问的数据/指令不在cache里面.
Core 读cache时:
若hit,则直接从cache读出数据即可。
若miss,有两种处理方式:
>read through ,直接从内存中读出
>read allocate,先把数据读到cache,再从cache读出。如果 CPU 要读取的 SRAM 区数据在 Cache 中已经加载好,就可以直接从 Cache 里面读取。如果没有,就用到配置 read allocate 了,意思就是在 Cache 里面开辟区域,将 SRAM 区数据加载进来,后续的操作,CPU 可以直接从 Cache 里面读取,从而时间加速。
Core 写cache时:
若hit,两种处理方式:
>write-through模式:
可以直接写到内存中同时放到Cache里面,优点是内存和cache同步更新,没有多总线访问造成的数据一致性问题,缺点是无法在写操作上面发挥性能。
>Write back模式:Cache line会被标为dirty,等到此行被evicted(驱逐,赶出, flush)时,才会执行实际的写操作,将Cache Line里面的数据写入到相应的存 储区。Write back安全隐患:如果 Cache 命中的情况下,此时仅 Cache 更新了,而 SRAM,SDRAM 没有更新,那么 DMA 直接从 SRAM 里面读出来的就是错误的。
若miss,两种处理方式:
>write-allocate:先把要写的数据载入到cache,写cache,然后再flush进内存。
>no-write-allocate:直接写入内存。
Cache 命中是访问的地址落在了给定的 Cache Line 里面,所以硬件需要做少量的地址比较工作,以检查此地址是否被缓存。如果命中了,将用于缓存读操作或者写操作。如果没有命中,则分配和标记新行,填充新的读写操作。如果所有行都分配完毕了,Cache 控制器将支持 eviction 操作。根据 Cache Line 替换算法,一行将被清除 Clean,无效化 Invalid 或者重新配置。数据缓存和指令缓存是采用的伪随机替换算法。Cache支持的4种基本操作,1.使能,2.禁止,3.清空,4.无效化。
Clean清空操作是将Cache Line中标记为dirty的数据写入到内存里面,无效化Invalid是将 Cache Line 标记为无效,等同于删除操作。这样Cache 空间就都腾出来了,可以加载新的指令/数据。
三.cache配合MPU使用
MPU(memory protection unit),首先需要通过MPU配置相应memory的属性(normal, strongly-ordered, device, XN etc.)
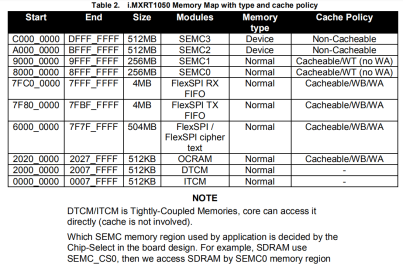
RT1052存储器默认映射和属性

四.什么是 cache 一致性问题
对于指令缓冲I-Cache,用户不用管,这里主要说的是数据缓存 D-Cache。
所谓的 Cache 一致性问题, 主要指的是由于 D-cache 存在时,表现在有多个 Host(典型的如 MCU 的 Core, DMA 等)访问同一块内存时, 由于数据会缓存在 D-cache 中而没有更新实际的物理内存。
在实际应用中,有以下两种情况:
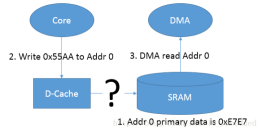
4.1
第一种情况是当有core写物理内存(SRAM,0x20200000)的指令时,(对应SDK例程:*(uint8_t *)(startAddr + count) = 0xffu;)Core 会先去更新相应的 cache-line(Write-back 策略),在没有 clean 的情况下,会导致其对应的实际物理内存中的数据并没有被更新,如果这个时候有其它的 Host(如 DMA)访问这段内存时,就会出现问题(由于实际物理内存并未被更新,和 D-cache 中的不一致),如果clean一下(对应SDK例程:L1CACHE_CleanDCacheByRange(startAddr, MEM_DMATRANSFER_LEN);)这就是所谓的 cache 一致性的问题。
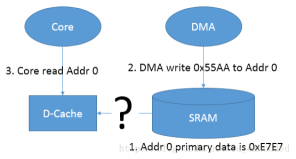
4.2
第二种情况是 DMA 更新了某段物理内存(DMA 和 cache 直接没有直接通道),而这个时候 Core 再读取这段内存的时候,由于相对应地址的 cache-line 没有被 invalidate,导致 Core 读到的是 cache-line 中的数据,而非被 DMA 更新过的实际物理内存的数据。
五。解决 cache 一致性问题
有两种可选方案:
一.所有的共享存储器都定义为共享属性
• 这些区域将默认不被缓存到 D-Cache。
• 所有的操作都直接针对二级存储器(内部Flash,外部存储器),性能降低。
• 因为缓存对这些区域是透明的,写软件更容易
二.通过软件进行cache的维护
(1)Cortex-M7 的写操作要是全局可见的
• 使用透写属性(通过 MPU 设置)。
• 使用 SIWT@CACR(Shared = Write Through)。
• 通过指令清 D-cache,然后所有更新位置禁止 D-Cache操作
这种情况,在DMA从SRAM搬运数据到SDRAM时,需要先执行clean。
L1CACHE_CleanInvalidateDCache();
(2)其他主设备的写操作要对 Cortex-M7 可见
• 比如作废 Cortex-M7 Dache 中数据
这种情况,在DMA从SDRAM搬运数据到SRAM时,需要搬运后执行Invalidate。
L1CACHE_CleanInvalidateDCache()
六.常见函数解释
SCB_EnableICache() 和 SCB_EnableDCache()
使能 I-cache 或 D-cache。
SCB_DisableICache() 和 SCB_DisableDCache()
禁用 I-cache 或 D-cache。
SCB_InvalidateICache()
使 I-cache 无效,I-cache 被 invalidate 之后,当读取指令时,会忽略相应的 cache-line 中的内容(因为被 validate 了),而从真实的物理地址中去获取相应的指令
SCB_InvalidateDCache()
使 D-cache 无效,D-cache 被 invalidate 之后,当有 Host(如 core,DMA 等)读取数据时,会忽略相应的 cache-line 中的内容( 因为被 validate 了),从真实的物理地址中去获取相应的数据
SCB_InvalidateDCache_by_Addr()
根据地址信息无效其对应的 cache-line。
SCB_CleanDCache()
Clean 所有的 cache-line,即将 dirty 的 cache-line 全部写到 cache line 对应的真实的物理地址中所谓的 drity 属性,
即写操作时, 更新了相应的 cache-line,但是没有更新到真实的物理地址,而这个 clean 的动作, 就是将 cache 中的内容更新到真实的物理地址中。
SCB_CleanDCache_by_Addr()
根据地址信息 clean 其对应的 cache-line
SCB_CleanInvalidateDCache_by_Addr()
根据地址信息 clean 并 invalidate 其对应的 cache-line。
SCB_CleanInvalidateDCache()
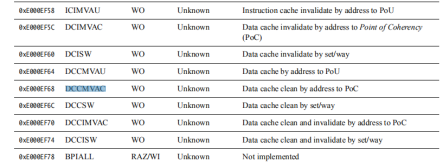
七. 其他指令解释
功能描述
DMB
数据存储器隔离。DMB 指令保证: 仅当所有在它前面的存储器访问操作
都执行完毕后,才提交(commit)在它后面的存储器访问操作。
DSB
数据同步隔离。比 DMB 严格: 仅当所有在它前面的存储器访问操作
都执行完毕后,才执行在它后面的指令(亦即任何指令都要等待存储器访 问操作——译者注)
ISB
指令同步隔离。最严格:它会清洗流水线,以保证所有它前面的指令都执
行完毕之后,才执行它后面的指令。
对于高级底层技巧:“自我更新”(self-mofifying)代码,非常有用。举例 来说,如果某个程序从下一条要执行的指令处更新了自己,
但是先前的旧指令已经被预取到流水线 中去了,此时就必须清洗流水线,把旧版本的指令洗出去,再预取新版本的指令。因此,必须在被 更新代码段的前面使用 ISB,以保证旧的代码从流水线中被清洗出去,不再有机会执行
Bootloader在跳转到app之前的清洗,就是1个例子,如下:
--------------------------------------------
LPUART_Deinit(LPUART1);
vSceneRenew();
__ISB();
__DSB();
/* Enable I cache and D cache */
SCB_DisableDCache();
SCB_DisableICache();
vControlSwitch();
--------------------------------------------------------------------
L1CACHE_InvalidateICacheByRange函数也是1个例子:
/**Invalidate cortex-m7 L1 instruction cache by range.***/
void L1CACHE_InvalidateICacheByRange(uint32_t address, uint32_t size_byte)
{
#if (__DCACHE_PRESENT == 1U)
uint32_t addr = address & (uint32_t)~(FSL_FEATURE_L1ICACHE_LINESIZE_BYTE - 1);
int32_t size = size_byte + address - addr;
uint32_t linesize = 32U;
__DSB();
while (size > 0)
{
SCB->ICIMVAU = addr;
addr += linesize;
size -= linesize;
}
__DSB();
__ISB();
#endif
}
以上内容参考了网上很多博客,还有官方文档,再次表示感谢,若有侵权,请联系删除,谢谢!
技术交流微信 18124528727.
-------------------------------------------------END---------------------------------------------------------------
Cortex_m7内核cache深入了解和应用的更多相关文章
- linux 内核cache
写驱动总会碰到和cache相关的东西 记录下用到的接口: 驱动中用的内存地址一般为内核地址,用户调用驱动接口时,有时候会把自己申请的地址赋给驱动,此时用户kmalloc得到内核地址, 再用mmap获得 ...
- Linux内核中内存cache的实现【转】
Linux内核中内存cache的实现 转自:http://blog.chinaunix.net/uid-127037-id-2919545.html 本文档的Copyleft归yfydz所有,使用 ...
- 协程 & 用户级(内核级)线程 & 切换开销 & 协程与异步回调的差异
今天先是看到多线程级别的内容,然后又看到协程的内容. 基本的领会是,协程是对异步回调方式的一种变换,同样是在一个线程内,协程通过主动放弃时间片交由其他协程执行来协作,故名协程. 而协程很早就有了,那时 ...
- 【内核】linux内核启动流程详细分析
Linux内核启动流程 arch/arm/kernel/head-armv.S 该文件是内核最先执行的一个文件,包括内核入口ENTRY(stext)到start_kernel间的初始化代码, 主要作用 ...
- 【内核】linux内核启动流程详细分析【转】
转自:http://www.cnblogs.com/lcw/p/3337937.html Linux内核启动流程 arch/arm/kernel/head-armv.S 该文件是内核最先执行的一个文件 ...
- 77%的Linux运维都不懂的内核问题
前言 之前在实习时,听了 OOM 的分享之后,就对 Linux 内核内存管理充满兴趣,但是这块知识非常庞大,没有一定积累,不敢写下,担心误人子弟,所以经过一个一段时间的积累,对内核内存有一定了解之后, ...
- linux下epoll实现机制
linux下epoll实现机制 原作者:陶辉 链接:http://blog.csdn.net/russell_tao/article/details/7160071 先简单回顾下如何使用C库封装的se ...
- linux I/O复用
转载自:哈维.dpkirin url:http://blog.csdn.NET/zhang_shuai_2011/article/details/7675797 http://blog.csdn.Ne ...
- Android的进程等级
Android五个进程等级 1.前台进程(Foreground process): 用户当前工作所需要的.一个进程如果满足下列任何条件被认为是前台进程: 正运行着一个正在与用户交互的活动(Activi ...
随机推荐
- 范仁义html+css课程---1、html基本结构
范仁义html+css课程---1.html基本结构 一.总结 一句话总结: html标签中包含head标签和body标签,head标签里面主要写用户不可见的内容,比如字符集编码,body标签里面主要 ...
- [Linux] 60s快速分析Linux性能
转载: https://www.cnblogs.com/zichuan/p/10440617.html 之前在地铁上看到过一篇快速分析Linux系统性能的文章,觉得以后有用,今天就找了一下,转载过来. ...
- SetThreadAffinityMask windows下绑定线程(进程)到指定的CPU核心
原帖地址:https://www.cnblogs.com/lvdongjie/p/4476766.html 一个程序指定到单独一个CPU上运行会比不指定CPU运行时快.这中间主要有两个原因:1)CPU ...
- useReducer代替Redux小案例-1(七)
使用useContext和useReducer是可以实现类似Redux的效果,并且一些简单的个人项目,完全可以用下面的方案代替Redux,这种做法要比Redux简单一些.因为useContext和us ...
- HttpWebRequest使用时发生阻塞的解决办法
HttpWebRequest使用如下: 第一种:使用Using 释放资源 /// <summary> /// Http Get请求返回数据 /// </summary> /// ...
- git命令note
日志查看 git log 太乱? git log --pretty=oneline 版本回退 git reset --hard commit_id git reset --hard HEAD^ 上上版 ...
- ubuntu下安装ftp服务
1. 安装vsftpd $ sudo apt-get install vsftpd 2. 创建一个用户user-ftp用于ftp服务 $ sudo adduser user-ftp 3.创建一个文件/ ...
- Xamarin图表开发基础教程(2)OxyPlot框架
Xamarin图表开发基础教程(2)OxyPlot框架 OxyPlot图表设计 OxyPlot是一个基于.Net的跨平台图表库.该图表库也支持Xamarin应用开发.该组件支持多种类型的图表.本章将主 ...
- iframe子页面无法返回上一页的问题
本文讨论的场景是ipad终端. 如题,因业务需要,需要使用iframe嵌套子页面.让外层始终保持一个socket连接,避免socket每跳转一个页面都要重新关闭建立连接的问题.但是这样问题来了,上线后 ...
- libfacedetection
libfacedetection测试 #include <stdio.h> #include <opencv2/opencv.hpp> #include <facedet ...