【神经网络与深度学习】【计算机视觉】Faster R-CNN
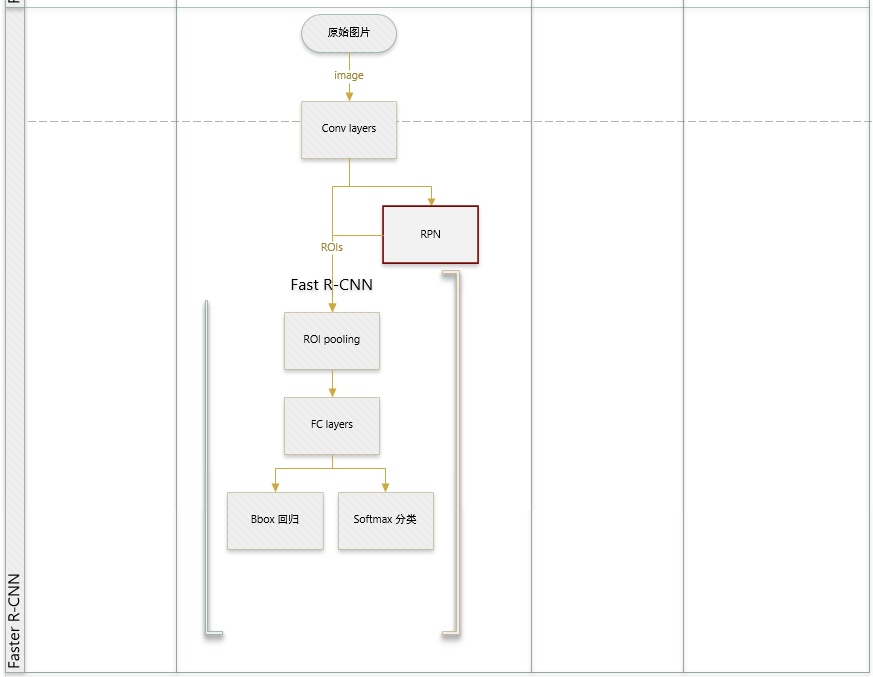
Faster R-CNN
论文提出:网络中的各个卷积层特征(feature map)也可以用来预测类别相关的region proposal(不需要事先执行诸如selective search之类的算法),但是如果简单的在前面增加一个专门提取proposal的网络又显得不够优雅,所以最终把region proposal提取和Fast-RCNN部分融合进了一个网络模型 (区域生成网络 RPN层),虽然训练阶段仍然要分多步,但是检测阶段非常方便快捷,准确率也与原来的Fast-RCNN相差不多,从此,再也不用担心region
proposal提取耗时比实际对象检测还多这种尴尬场景了。(faster RCNN可以大致看做“区域生成网络+fast RCNN“的系统,用区域生成网络代替fast RCNN中的Selective Search方法)

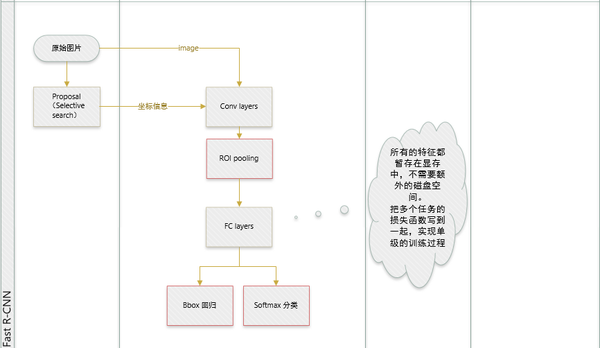

区域生成网络 ( Region Proposal Networks )
分析:
如何训练出一个网络来替代selective search相类似的功能呢?论文借鉴SPP和ROI中的思想 在feature map中提取proposal。 先通过对应关系把feature map的点映射回原图(参看:原始图片中的ROI如何映射到到feature
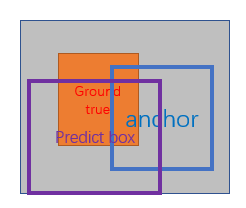
map?),在每一个对应的原图设计不同的固定尺度窗口(bbox),根据该窗口与ground truth的IOU给它正负标签,让它学习里面是否有object,这样就训练一个网络(Region Proposal Network)。
由于我们只需要找出大致的地方,无论是精确定位位置还是尺寸,后面的工作都可以完成,作者对bbox做了三个固定:固定尺度变化(三种尺度),固定scale ratio变化(三种ratio),固定采样方式(只在feature map的每个点在原图中的对应ROI上采样,反正后面的工作能进行调整) 。如此就可以降低任务复杂度。
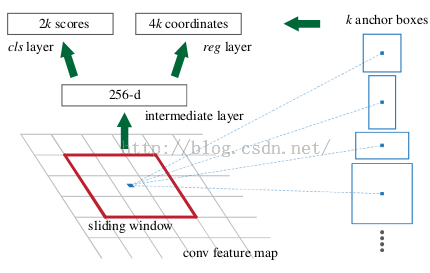
可以在特征图上提取proposal之后,网络前面就可以共享卷积计算结果(SPP减少计算量的思想)。这个网络的结果就是卷积层的每个点都有有关于k个achor boxes的输出,包括是不是物体,调整box相应的位置。
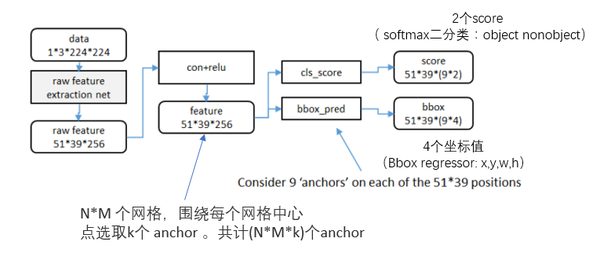
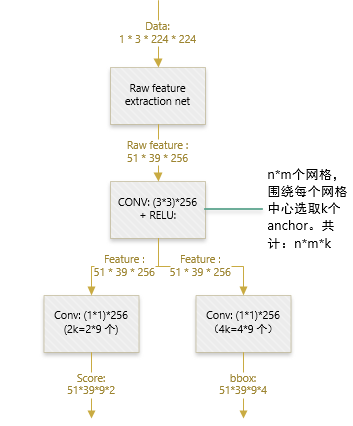
具体过程:
- 得到最终用来预测的feature map:图片在输入网络后,依次经过一系列conv+relu (套用ImageNet上常见的分类网络即可 本论文实验了5层的ZF,16层的VGG-16)得到的feature map,额外添加一个conv+relu层,输出51*39*256维特征(feature map)。准备后续用来选取proposal,并且此时坐标依然可以映射回原图。
- 计算Anchors: 在feature map上的每个特征点预测多个region proposals。具体作法是:把每个特征点映射回映射回原图的感受野的中心点当成一个基准点,然后围绕这个基准点选取k个不同scale、aspect ratio的anchor。论文中3个scale(三种面积
),3个aspect
ratio( {1:1,1:2,2:1} )
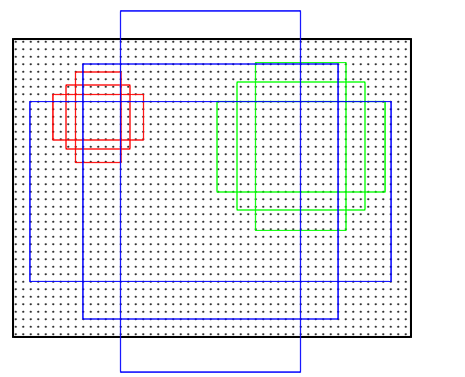
- 关于正负样本的划分: 考察训练集中的每张图像(含有人工标定的ground true box) 的所有anchor(N*M*k)
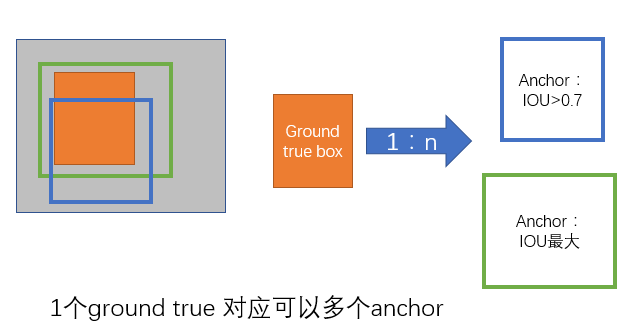
- a. 对每个标定的ground true box区域,与其重叠比例最大的anchor记为 正样本 (保证每个ground true 至少对应一个正样本anchor)
- b. 对a)剩余的anchor,如果其与某个标定区域重叠比例大于0.7,记为正样本(每个ground true box可能会对应多个正样本anchor。但每个正样本anchor 只可能对应一个grand true box);如果其与任意一个标定的重叠比例都小于0.3,记为负样本。
- c. 对a),b)剩余的anchor,弃去不用。
- d. 跨越图像边界的anchor弃去不用
- 定义损失函数:对于每个anchor,首先在后面接上一个二分类softmax,有2个score 输出用以表示其是一个物体的概率与不是一个物体的概率 (
),然后再接上一个bounding box的regressor
输出代表这个anchor的4个坐标位置(),因此RPN的总体Loss函数可以定义为 :
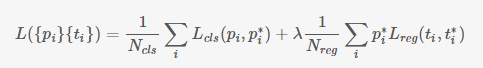
- i表示第i个anchor,当anchor是正样本时
=1 ,是负样本则=0 。
表示
一个与正样本anchor 相关的ground true box 坐标 (每个正样本anchor 只可能对应一个ground true box: 一个正样本anchor 与某个grand true box对应,那么该anchor与ground true box 的IOU要么是所有anchor中最大,要么大于0.7) - x,y,w,h分别表示box的中心坐标和宽高,
分别表示 predicted box, anchor box, and ground truth box
(y,w,h同理)表示ground
true box相对于anchor box的偏移,学习目标自然就是让前者接近后者的值。
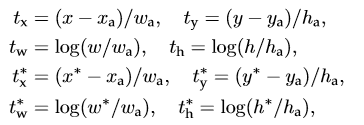
- 其中
是:
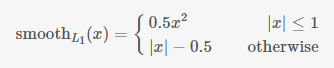
是关于两种类别 (object vs. not object) 的log loss
训练:正负样本的选择,文中提到如果对每幅图的所有anchor都去优化loss function,那么最终会因为负样本过多导致最终得到的模型对正样本预测准确率很低(It is possible to optimize for the loss functions of all anchors, but this will bias towards negative samples as they are dominate)。
- 训练RPN:文中提到如果每幅图的所有anchor都去参与优化loss function,那么最终会因为负样本过多导致最终得到的模型对正样本预测准确率很低。因此 在每幅图像中随机采样256个anchors去参与计算一次mini-batch的损失。正负比例1:1(如果正样本少于128则补充采样负样本)

注意点:
- 在到达全连接层之前,卷积层和Pooling层对图片输入大小其实没有size的限制,因此RCNN系列的网络模型其实是不需要实现把图片resize到固定大小的;
- n=3看起来很小,但是要考虑到这是非常高层的feature map,其size本身也没有多大,因此 3×33×3 9个矩形中,每个矩形窗框都是可以感知到很大范围的。
Sharing Features for RPN and Fast R-CNN
前面已经讨论如何训练提取proposal的RPN,分类采用Fast R-CNN。如何把这两者放在同一个网络结构中训练出一个共享卷积的Multi-task网络模型。
我们知道,如果是分别训练两种不同任务的网络模型,即使它们的结构、参数完全一致,但各自的卷积层内的卷积核也会向着不同的方向改变,导致无法共享网络权重,论文作者提出了三种可能的方式:
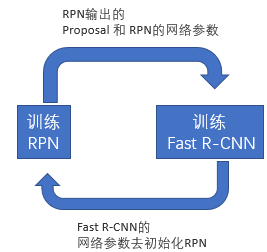
- Alternating training:此方法其实就是一个不断迭代的训练过程,既然分别训练RPN和Fast-RCNN可能让网络朝不同的方向收敛,a)那么我们可以先独立训练RPN,然后用这个RPN的网络权重对Fast-RCNN网络进行初始化并且用之前RPN输出proposal作为此时Fast-RCNN的输入训练Fast R-CNN。b) 用Fast R-CNN的网络参数去初始化RPN。之后不断迭代这个过程,即循环训练RPN、Fast-RCNN。
- Approximate joint training:这里与前一种方法不同,不再是串行训练RPN和Fast-RCNN,而是尝试把二者融入到一个网络内,具体融合的网络结构如下图所示,可以看到,proposals是由中间的RPN层输出的,而不是从网络外部得到。需要注意的一点,名字中的"approximate"是因为反向传播阶段RPN产生的cls score能够获得梯度用以更新参数,但是proposal的坐标预测则直接把梯度舍弃了,这个设置可以使backward时该网络层能得到一个解析解(closed results),并且相对于Alternating
traing减少了25-50%的训练时间。(此处不太理解: 每次mini-batch的RPN输出的proposal box坐标信息固定,让Fast R-CNN的regressor去修正位置?)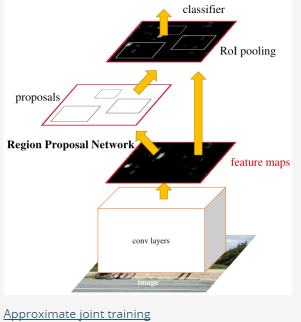
- Non-approximate training:上面的Approximate joint training把proposal的坐标预测梯度直接舍弃,所以被称作approximate,那么理论上如果不舍弃是不是能更好的提升RPN部分网络的性能呢?作者把这种训练方式称为“ Non-approximate joint training”,但是此方法在paper中只是一笔带过,表示“This is a nontrivial problem and a solution can be given by an “RoI
warping” layer as developed in [15], which is beyond the scope of this paper”,
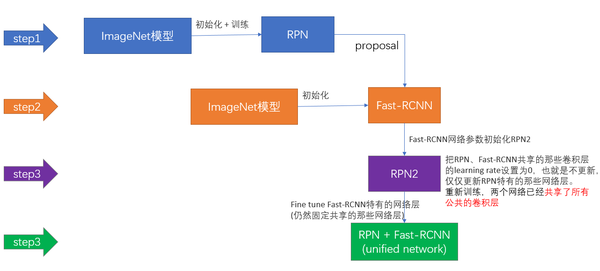
上面说完了三种可能的训练方法,可非常神奇的是作者发布的源代码里却用了另外一种叫做4-Step Alternating Training的方法,思路和迭代的Alternating training有点类似,但是细节有点差别:
- 第一步:用ImageNet模型初始化,独立训练一个RPN网络;
- 第二步:仍然用ImageNet模型初始化,但是使用上一步RPN网络产生的proposal作为输入,训练一个Fast-RCNN网络,至此,两个网络每一层的参数完全不共享;
- 第三步:使用第二步的Fast-RCNN网络参数初始化一个新的RPN网络,但是把RPN、Fast-RCNN共享的那些卷积层的learning rate设置为0,也就是不更新,仅仅更新RPN特有的那些网络层,重新训练,此时,两个网络已经共享了所有公共的卷积层;
- 第四步:仍然固定共享的那些网络层,把Fast-RCNN特有的网络层也加入进来,形成一个unified network,继续训练,fine tune Fast-RCNN特有的网络层,此时,该网络已经实现我们设想的目标,即网络内部预测proposal并实现检测的功能。
参考:
【神经网络与深度学习】【计算机视觉】Faster R-CNN的更多相关文章
- [神经网络与深度学习][计算机视觉]SSD编译时遇到了json_parser_read.hpp:257:264: error: ‘type name’ declared as function ret
运行make之后出现如下错误: /usr/include/boost/property_tree/detail/json_parser_read.hpp:257:264: error: 'type n ...
- 【神经网络与深度学习】卷积神经网络(CNN)
[神经网络与深度学习]卷积神经网络(CNN) 标签:[神经网络与深度学习] 实际上前面已经发布过一次,但是这次重新复习了一下,决定再发博一次. 说明:以后的总结,还应该以我的认识进行总结,这样比较符合 ...
- (转)神经网络和深度学习简史(第一部分):从感知机到BP算法
深度|神经网络和深度学习简史(第一部分):从感知机到BP算法 2016-01-23 机器之心 来自Andrey Kurenkov 作者:Andrey Kurenkov 机器之心编译出品 参与:chen ...
- 【吴恩达课后测验】Course 1 - 神经网络和深度学习 - 第一周测验【中英】
[吴恩达课后测验]Course 1 - 神经网络和深度学习 - 第一周测验[中英] 第一周测验 - 深度学习简介 和“AI是新电力”相类似的说法是什么? [ ]AI为我们的家庭和办公室的个人设备供电 ...
- 深度学习(一)——CNN算法流程
深度学习(一)——CNN(卷积神经网络)算法流程 参考:http://dataunion.org/11692.html 0 引言 20世纪60年代,Hubel和Wiesel在研究猫脑皮层中用于局部敏感 ...
- [DeeplearningAI笔记]神经网络与深度学习人工智能行业大师访谈
觉得有用的话,欢迎一起讨论相互学习~Follow Me 吴恩达采访Geoffrey Hinton NG:前几十年,你就已经发明了这么多神经网络和深度学习相关的概念,我其实很好奇,在这么多你发明的东西中 ...
- R语言︱H2o深度学习的一些R语言实践——H2o包
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- R语言H2o包的几个应用案例 笔者寄语:受启发 ...
- 【吴恩达课后测验】Course 1 - 神经网络和深度学习 - 第二周测验【中英】
[中英][吴恩达课后测验]Course 1 - 神经网络和深度学习 - 第二周测验 第2周测验 - 神经网络基础 神经元节点计算什么? [ ]神经元节点先计算激活函数,再计算线性函数(z = Wx + ...
- 对比《动手学深度学习》 PDF代码+《神经网络与深度学习 》PDF
随着AlphaGo与李世石大战的落幕,人工智能成为话题焦点.AlphaGo背后的工作原理"深度学习"也跳入大众的视野.什么是深度学习,什么是神经网络,为何一段程序在精密的围棋大赛中 ...
- 如何理解归一化(Normalization)对于神经网络(深度学习)的帮助?
如何理解归一化(Normalization)对于神经网络(深度学习)的帮助? 作者:知乎用户链接:https://www.zhihu.com/question/326034346/answer/730 ...
随机推荐
- 关于微信小程序在ios中无法调起摄像头问题
这几天关于微信小程序开发关于wx.chooseVideo组件问题,因为自己一直是安卓手机上测试,可以调取摄像头,但是应用在ios上无法打开摄像头,困扰了好多天,经过反复查看官方文档,今天总算修复了这个 ...
- 题解 LA2889
题目大意 多组数据,每组数据给出一个正整数 \(n\),输出第 \(n\) 大的回文数(即 \(1,2,3,\cdots\)). 分析 不难发现,\(n\) 位的回文数有 \(9*10^{\lfloo ...
- 二、python介绍
python第一篇-------python介绍 一.python介绍 python的创始人为吉多·范罗苏姆(Guido van Rossum).1989年的圣诞节期间,Guido开始写Python语 ...
- S1_搭建分布式OpenStack集群_09 cinder 控制节点配置
一.创建数据库创建数据库以及用户:# mysql -uroot -p12345678MariaDB [(none)]> CREATE DATABASE cinder;MariaDB [(none ...
- navicat设置唯一
https://blog.csdn.net/Song_JiangTao/article/details/82192189
- AD域服务器组策略实现文件夹重定向 保护文件安全
网络管理员或许都遇到过类似的烦恼.如系统崩溃后,原来存放在 C盘的应用程序专署数据都丢失了;或者桌面上的文件莫名其妙少了,等等.有时候,我们也千方百计提醒员工不要把文件存放在桌面上,但是他们总是不听 ...
- cyyz: Day 4 网络流整理
Day 4 网络流的理论性知识(算了..我自己都看不下去,还是整理些例题以后复习用吧qaq): 一.PPT(主要内容) 二.搜自度娘 定义: 年,L.R. 福特和 D.R. 富尔克森等人给出了解决 ...
- linux命令之------Cat命令
Cat命令 作用:cat命令用于连接文件并打印,查看文件内容: -n或--number:由1开始对所有输出的行数编号: -b或--number-nonblank:和-n相似,只不过对于空白行不做编号: ...
- Myschool试题
题目: 1.查询所有学生记录,包含年级名称2.查询S1年级下的学生记录 一.com.myschool.dao 1 BaseDao package com.myschool.dao; import ja ...
- Docker快速部署gitlab应用实战
Gitlab是一个用于仓库管理系统开源项目,使用Git作为代码管理工具,并在此基础上搭建的web服务,可通过web界面进行访问公开或者私人项目,拥有类似于GIthub类似的功能,能够浏览源代码,可管理 ...