初识HDFS(10分钟了解HDFS、NameNode和DataNode)
概览
首先我们来认识一下HDFS, HDFS(Hadoop Distributed File System )Hadoop分布式文件系统。它其实是将一个大文件分成若干块保存在不同服务器的多个节点中。通过联网让用户感觉像是在本地一样查看文件,为了降低文件丢失造成的错误,它会为每个小文件复制多个副本(默认为三个),以此来实现多机器上的多用户分享文件和存储空间。
HDFS特点:
① 保存多个副本,且提供容错机制,副本丢失或宕机自动恢复。默认存3份。
② 运行在廉价的机器上。
③ 适合大数据的处理。因为小文件也占用一个块,小文件越多(1000个1k文件)块越 多,NameNode压力越大。
如:将一个大文件分成三块A、B、C的存储方式
PS:数据复制原则:
除了最后一个块之外的文件中的所有块都是相同的大小。
HDFS的放置策略:
是将一个副本放在本地机架中的一个节点上,另一个位于不同(远程)机架中的节点上,而最后一个位于不同节点上远程机架。
涉及到的属性:
块大小:Hadoop1版本里默认为64M,Hadoop2版本里默认为128M
复制因子:每个文件加上其文件副本的份数
HDFS的基本结构

如上图所示,HDFS基本结构分NameNode、SecondaryNameNode、DataNode这几个。
NameNode:是Master节点,有点类似Linux里的根目录。管理数据块映射;处理客户端的读写请求;配置副本策略;管理HDFS的名称空间;
SecondaryNameNode:保存着NameNode的部分信息(不是全部信息NameNode宕掉之后恢复数据用),是NameNode的冷备份;合并fsimage和edits然后再发给namenode。(防止edits过大的一种解决方案)
DataNode:负责存储client发来的数据块block;执行数据块的读写操作。是NameNode的小弟。
热备份:b是a的热备份,如果a坏掉。那么b马上运行代替a的工作。
冷备份:b是a的冷备份,如果a坏掉。那么b不能马上代替a工作。但是b上存储a的一些信息,减少a坏掉之后的损失。
fsimage:元数据镜像文件(文件系统的目录树。)
edits:元数据的操作日志(针对文件系统做的修改操作记录)
namenode内存中存储的是=fsimage+edits。
NameNode详解
作用:
Namenode起一个统领的作用,用户通过namenode来实现对其他数据的访问和操作,类似于root根目录的感觉。
Namenode包含:目录与数据块之间的关系(靠fsimage和edits来实现),数据块和节点之间的关系
fsimage文件与edits文件是Namenode结点上的核心文件。
Namenode中仅仅存储目录树信息,而关于BLOCK的位置信息则是从各个Datanode上传到Namenode上的。
Namenode的目录树信息就是物理的存储在fsimage这个文件中的,当Namenode启动的时候会首先读取fsimage这个文件,将目录树信息装载到内存中。
而edits存储的是日志信息,在Namenode启动后所有对目录结构的增加,删除,修改等操作都会记录到edits文件中,并不会同步的记录在fsimage中。
而当Namenode结点关闭的时候,也不会将fsimage与edits文件进行合并,这个合并的过程实际上是发生在Namenode启动的过程中。
也就是说,当Namenode启动的时候,首先装载fsimage文件,然后在应用edits文件,最后还会将最新的目录树信息更新到新的fsimage文件中,然后启用新的edits文件。
整个流程是没有问题的,但是有个小瑕疵,就是如果Namenode在启动后发生的改变过多,会导致edits文件变得非常大,大得程度与Namenode的更新频率有关系。
那么在下一次Namenode启动的过程中,读取了fsimage文件后,会应用这个无比大的edits文件,导致启动时间变长,并且不可控,可能需要启动几个小时也说不定。
Namenode的edits文件过大的问题,也就是SecondeNamenode要解决的主要问题。
SecondNamenode会按照一定规则被唤醒,然后进行fsimage文件与edits文件的合并,防止edits文件过大,导致Namenode启动时间过长。
DataNode详解
DataNode在HDFS中真正存储数据。
首先解释块(block)的概念:
- DataNode在存储数据的时候是按照block为单位读写数据的。block是hdfs读写数据的基本单位。
- 假设文件大小是100GB,从字节位置0开始,每128MB字节划分为一个block,依此类推,可以划分出很多的block。每个block就是128MB大小。
- block本质上是一个 逻辑概念,意味着block里面不会真正的存储数据,只是划分文件的。
- block里也会存副本,副本优点是安全,缺点是占空间
SecondaryNode
执行过程:从NameNode上 下载元数据信息(fsimage,edits),然后把二者合并,生成新的fsimage,在本地保存,并将其推送到NameNode,同时重置NameNode的edits.
工作原理(转自“大牛笔记”的博客,由于实现是清晰,受益很大,在此不做改动)
写操作:

有一个文件FileA,100M大小。Client将FileA写入到HDFS上。
HDFS按默认配置。
HDFS分布在三个机架上Rack1,Rack2,Rack3。
a. Client将FileA按64M分块。分成两块,block1和Block2;
b. Client向nameNode发送写数据请求,如图蓝色虚线①------>。
c. NameNode节点,记录block信息。并返回可用的DataNode,如粉色虚线②--------->。
Block1: host2,host1,host3
Block2: host7,host8,host4
原理:
NameNode具有RackAware机架感知功能,这个可以配置。
若client为DataNode节点,那存储block时,规则为:副本1,同client的节点上;副本2,不同机架节点上;副本3,同第二个副本机架的另一个节点上;其他副本随机挑选。
若client不为DataNode节点,那存储block时,规则为:副本1,随机选择一个节点上;副本2,不同副本1,机架上;副本3,同副本2相同的另一个节点上;其他副本随机挑选。
d. client向DataNode发送block1;发送过程是以流式写入。
流式写入过程,
1>将64M的block1按64k的package划分;
2>然后将第一个package发送给host2;
3>host2接收完后,将第一个package发送给host1,同时client想host2发送第二个package;
4>host1接收完第一个package后,发送给host3,同时接收host2发来的第二个package。
5>以此类推,如图红线实线所示,直到将block1发送完毕。
6>host2,host1,host3向NameNode,host2向Client发送通知,说“消息发送完了”。如图粉红颜色实线所示。
7>client收到host2发来的消息后,向namenode发送消息,说我写完了。这样就真完成了。如图黄色粗实线
8>发送完block1后,再向host7,host8,host4发送block2,如图蓝色实线所示。
9>发送完block2后,host7,host8,host4向NameNode,host7向Client发送通知,如图浅绿色实线所示。
10>client向NameNode发送消息,说我写完了,如图黄色粗实线。。。这样就完毕了。
分析,通过写过程,我们可以了解到:
①写1T文件,我们需要3T的存储,3T的网络流量贷款。
②在执行读或写的过程中,NameNode和DataNode通过HeartBeat进行保存通信,确定DataNode活着。如果发现DataNode死掉了,就将死掉的DataNode上的数据,放到其他节点去。读取时,要读其他节点去。
③挂掉一个节点,没关系,还有其他节点可以备份;甚至,挂掉某一个机架,也没关系;其他机架上,也有备份。
读操作:
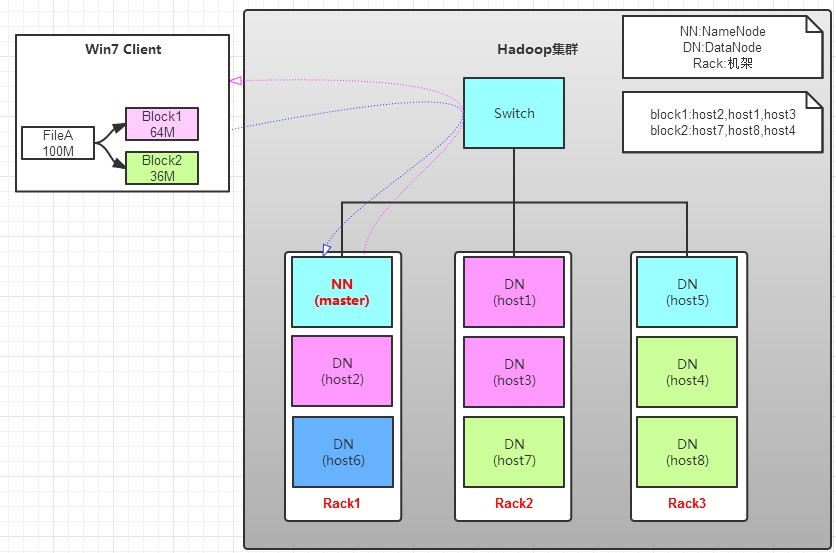
读操作就简单一些了,如图所示,client要从datanode上,读取FileA。而FileA由block1和block2组成。
那么,读操作流程为:
a. client向namenode发送读请求。
b. namenode查看Metadata信息,返回fileA的block的位置。
block1:host2,host1,host3
block2:host7,host8,host4
c. block的位置是有先后顺序的,先读block1,再读block2。而且block1去host2上读取;然后block2,去host7上读取;
上面例子中,client位于机架外,那么如果client位于机架内某个DataNode上,例如,client是host6。那么读取的时候,遵循的规律是:
优选读取本机架上的数据。
运算和存储在同一个服务器中,每一个服务器都可以是本地服务器
补充
元数据
元数据被定义为:描述数据的数据,对数据及信息资源的描述性信息。(类似于Linux中的i节点)
以 “blk_”开头的文件就是 存储数据的block。这里的命名是有规律的,除了block文件外,还有后 缀是“meta”的文件 ,这是block的源数据文件,存放一些元数据信息。
数据复制
NameNode做出关于块复制的所有决定。它周期性地从集群中的每个DataNode接收到一个心跳和一个阻塞报告。收到心跳意味着DataNode正常运行。Blockreport包含DataNode上所有块的列表。
参考文献:
http://www.cnblogs.com/laov/p/3434917.html
https://www.ibm.com/developerworks/cn/opensource/os-cn-hadoop-name-node/
http://www.cnblogs.com/linuxprobe/p/5594431.html
初识HDFS(10分钟了解HDFS、NameNode和DataNode)的更多相关文章
- cdh中hdfs非ha环境迁移Namenode与secondaryNamenode,从uc机器到阿里;
1.停掉外部接入服务: 2 NameNode Metadata备份: 2.1 备份fsimage数据,(该操作适用HA和非HA的NameNode),使用如下命令进行备份: [root@cdh01 df ...
- HDFS体系结构(NameNode、DataNode详解)
hadoop项目地址:http://hadoop.apache.org/ NameNode.DataNode详解 (一)分布式文件系统概述 数据量越来越多,在一个操作系统管辖的范围存不下了,那么就分配 ...
- hadoop的hdfs中的namenode和datanode知识总结
一,NameNode: 1, Namenode是中心服务器,单一节点(简化系统的设计和实现),负责管理文件系统的名称空间(namespace)以及客户端对文件的访问. 2, 文件操作,Namenod ...
- HDFS 10 - HDFS 的联邦机制(Federation 机制)
目录 1 - 为什么需要联邦 2 - Federation 架构设计 3 HDFS Federation 的不足 版权声明 1 - 为什么需要联邦 单 NameNode 的架构存在的问题:当集群中数据 ...
- vivo 万台规模 HDFS 集群升级 HDFS 3.x 实践
vivo 互联网大数据团队-Lv Jia Hadoop 3.x的第一个稳定版本在2017年底就已经发布了,有很多重大的改进. 在HDFS方面,支持了Erasure Coding.More than 2 ...
- HDFS shell操作及HDFS Java API编程
HDFS shell操作及HDFS Java API编程 1.熟悉Hadoop文件结构. 2.进行HDFS shell操作. 3.掌握通过Hadoop Java API对HDFS操作. 4.了解Had ...
- (第3篇)HDFS是什么?HDFS适合做什么?我们应该怎样操作HDFS系统?
摘要: 这篇文章会详细介绍HDFS是什么,HDFS的作用,适合和不适合的场景,我们该如何操作HDFS? HDFS文件系统 Hadoop 附带了一个名为 HDFS(Hadoop分布式文件系统)的分布 ...
- HDFS Federation(转HDFS Federation(HDFS 联盟)介绍 CSDN)
转载地址:http://blog.csdn.net/strongerbit/article/details/7013221 HDFS Federation(HDFS 联盟)介绍 1. 当前HDFS架构 ...
- [转]10分钟梳理MySQL知识点:揭秘亿级高并发数据库调优与最佳实践法则
转:https://mp.weixin.qq.com/s/RYIiHAHHStIMftQT6lQSgA 做业务,要懂基本的SQL语句: 做性能优化,要懂索引,懂引擎: 做分库分表,要懂主从,懂读写分离 ...
随机推荐
- PostgreSQL数据库安装
PostgreSQL数据库安装 postgresqllinux9.6.0 2018年01月31日 10时53分13秒 编译以及安装 源码编译 程序安装 数据库的启动和停止 启动数据库 关闭数据库 数据 ...
- 【统计难题】【HDU - 1251】【map打表或字典树】【字典树模板】
思路 题意:题目为中文题,这里不再过多阐述. 思路1:可以在读入单词表的过程中将单词分解,用map将它一 一记录 思路2:利用字典树,这个方法较快些,下面代码中会分别给出数组和结构体指针两种形式的字典 ...
- 基于Docker容器使用NVIDIA-GPU训练神经网络
一,nvidia K80驱动安装 1, 查看服务器上的Nvidia(英伟达)显卡信息,命令lspci |grep NVIDIA 05:00.0 3D controller: NVIDIA Corpo ...
- ReentrantReadWriteLock中的锁降级
锁降级指的是写锁降级为读锁. 因为读锁与读锁之间不互斥,如果是写锁与读锁或者是写锁与写锁就会互斥,所以由写锁变为读锁就降级了. 如果当前线程拥有写锁,然后将其释放,最后再获取读锁,这种并不能称之为锁降 ...
- NumPy的Linalg线性代数库探究
1.矩阵的行列式 from numpy import * A=mat([[1,2,4,5,7],[9,12,11,8,2],[6,4,3,2,1],[9,1,3,4,5],[0,2,3,4,1]]) ...
- python遇到动态函数---TypeError: unbound method a() must be called with A instance as first argument (got nothing instead)
TypeError: unbound method a() must be called with A instance as first argument (got nothing instead) ...
- opencv图像处理之gamma变换
import cv2 import numpy as np img=cv2.imread('4.jpg') def adjust_gamma(image, gamma=1.0): invGamma = ...
- JavaScript基础05——严格模式
严格模式: 除了正常运行模式,ECMAscript5添加了第二种运行模式:“严格模式”(strict mode).顾名思义,这种模式是的Javascript在更严格的条件下运行. 严格模式的作用: 1 ...
- 数论--扩展欧几里得exgcd
算法思想 我们想求得一组\(x,y\)使得 \(ax+by = \gcd(a,b)\) 根据 \(\gcd(a,b) = \gcd(b,a\bmod b)\) 如果我们现在有\(x',y'\) 使得 ...
- solidworks 学习 (四)
旋钮三维建模