python爬取数据分析
一.python爬虫使用的模块
1.import requests
2.from bs4 import BeautifulSoup
3.pandas 数据分析高级接口模块
二. 爬取数据在第一个请求中时, 使用BeautifulSoup
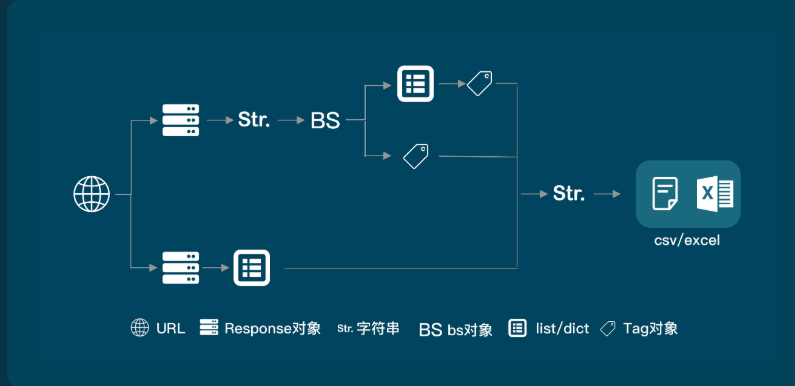
- import requests
# 引用requests库
from bs4 import BeautifulSoup
# 引用BeautifulSoup库
res_movies = requests.get('https://movie.douban.com/chart')
# 获取数据
bs_movies = BeautifulSoup(res_movies.text,'html.parser')
# 解析数据
list_movies= bs_movies.find_all('div',class_='pl2')
# 查找最小父级标签
list_all = []
# 创建一个空列表,用于存储信息
for movie in list_movies:
tag_a = movie.find('a')
# 提取第0个父级标签中的<a>标签
name = tag_a.text.replace(' ', '').replace('\n', '')
# 电影名,使用replace方法去掉多余的空格及换行符
url = tag_a['href']
# 电影详情页的链接
tag_p = movie.find('p', class_='pl')
# 提取父级标签中的<p>标签
information = tag_p.text.replace(' ', '').replace('\n', '')
# 电影基本信息,使用replace方法去掉多余的空格及换行符
tag_div = movie.find('div', class_='star clearfix')
# 提取父级标签中的<div>标签
rating = tag_div.text.replace(' ', '').replace('\n', '')
# 电影评分信息,使用replace方法去掉多余的空格及换行符
list_all.append([name,url,information,rating])
# 将电影名、URL、电影基本信息和电影评分信息,封装为列表,用append方法添加进list_all
print(list_all)
# 打印
三.当数据不在第一个请求中时, 使用network获取数据
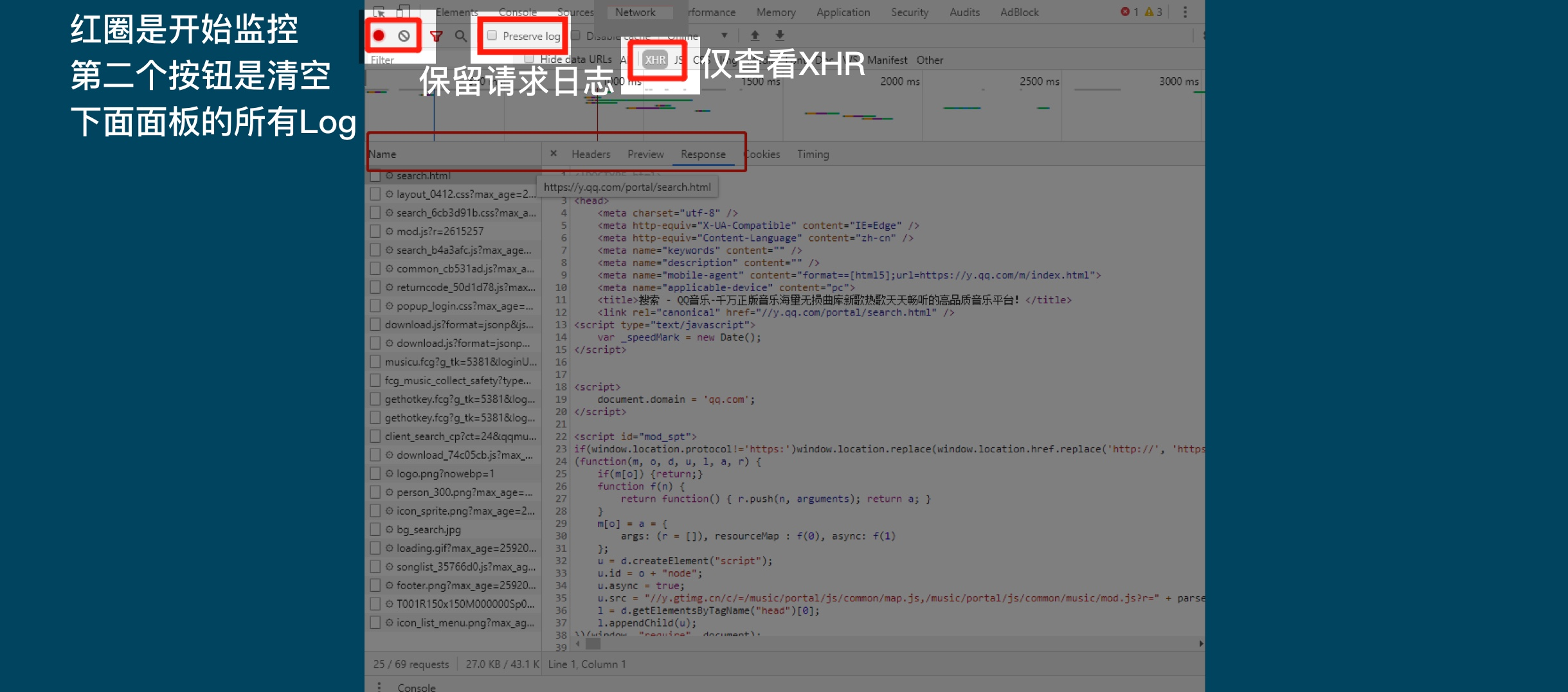

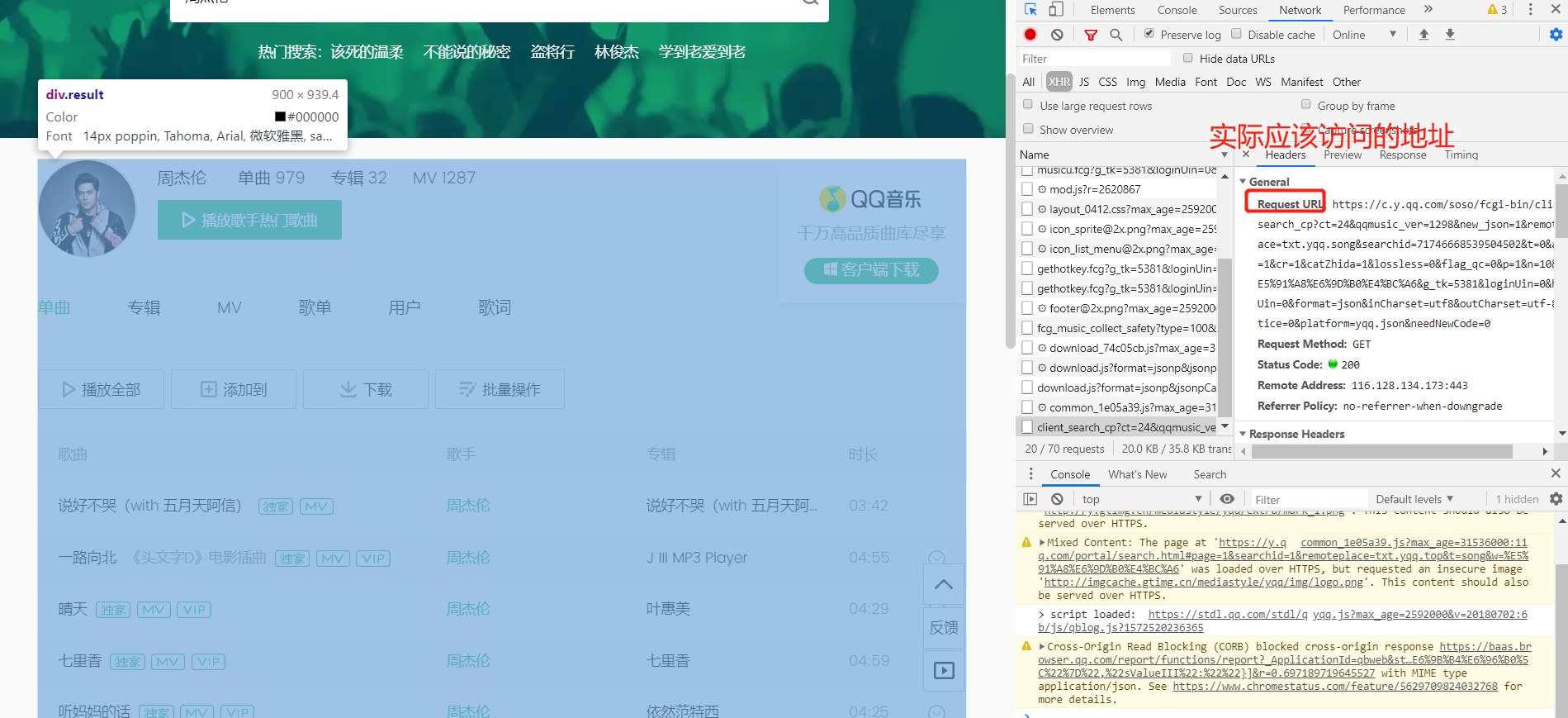
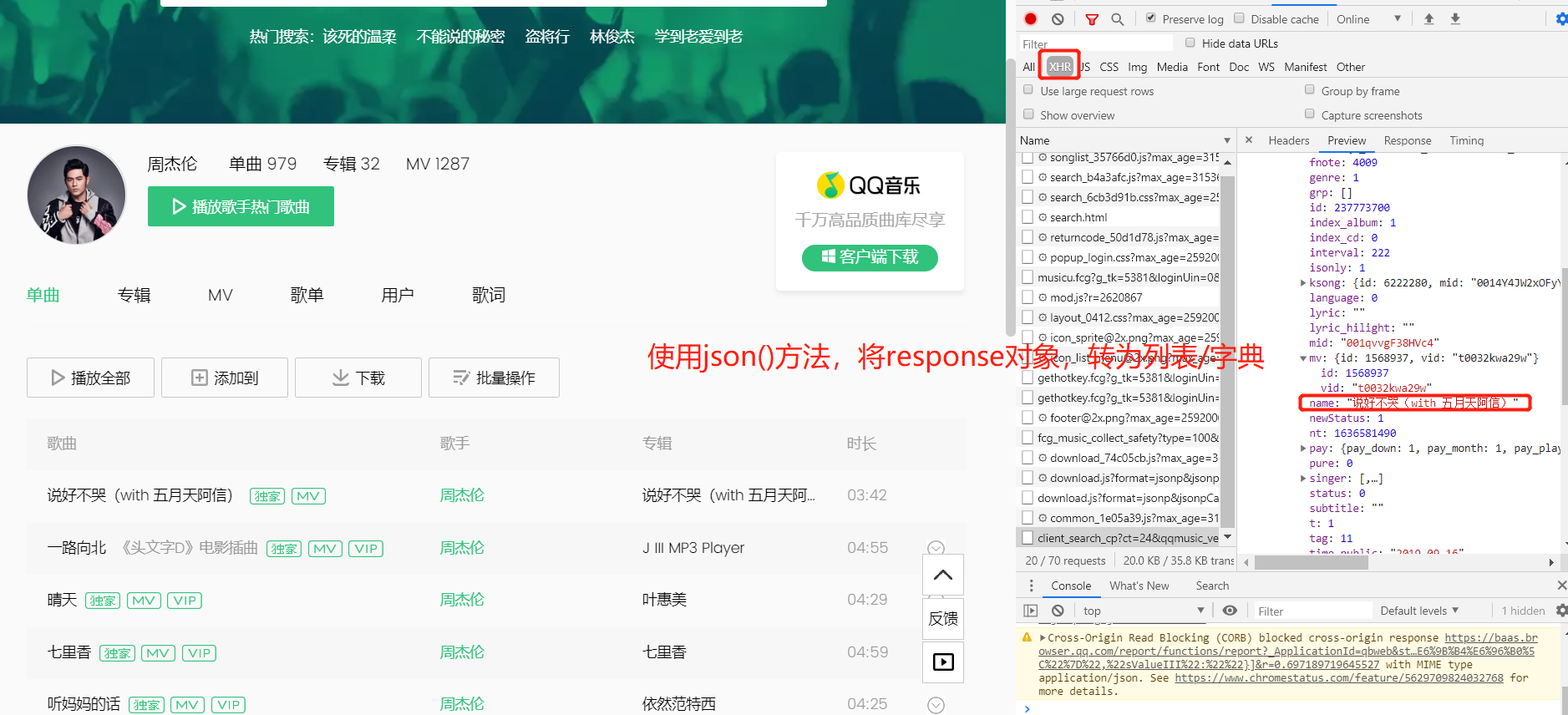
例如:
- import requests
from bs4 import BeautifulSoup- res = requests.get('https://c.y.qq.com/soso/fcgi-bin/client_search_cp?ct=24&qqmusic_ver=1298&new_json=1&remoteplace=txt.yqq.song&searchid=71746668539504502&t=0&aggr=1&cr=1&catZhida=1&lossless=0&flag_qc=0&p=1&n=10&w=%E5%91%A8%E6%9D%B0%E4%BC%A6&g_tk=5381&loginUin=0&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq.json&needNewCode=0')
res_json = res.json()
songs = res_json['data']['song']['list']
for i in range(len(songs)):
print(songs[i]['name'])
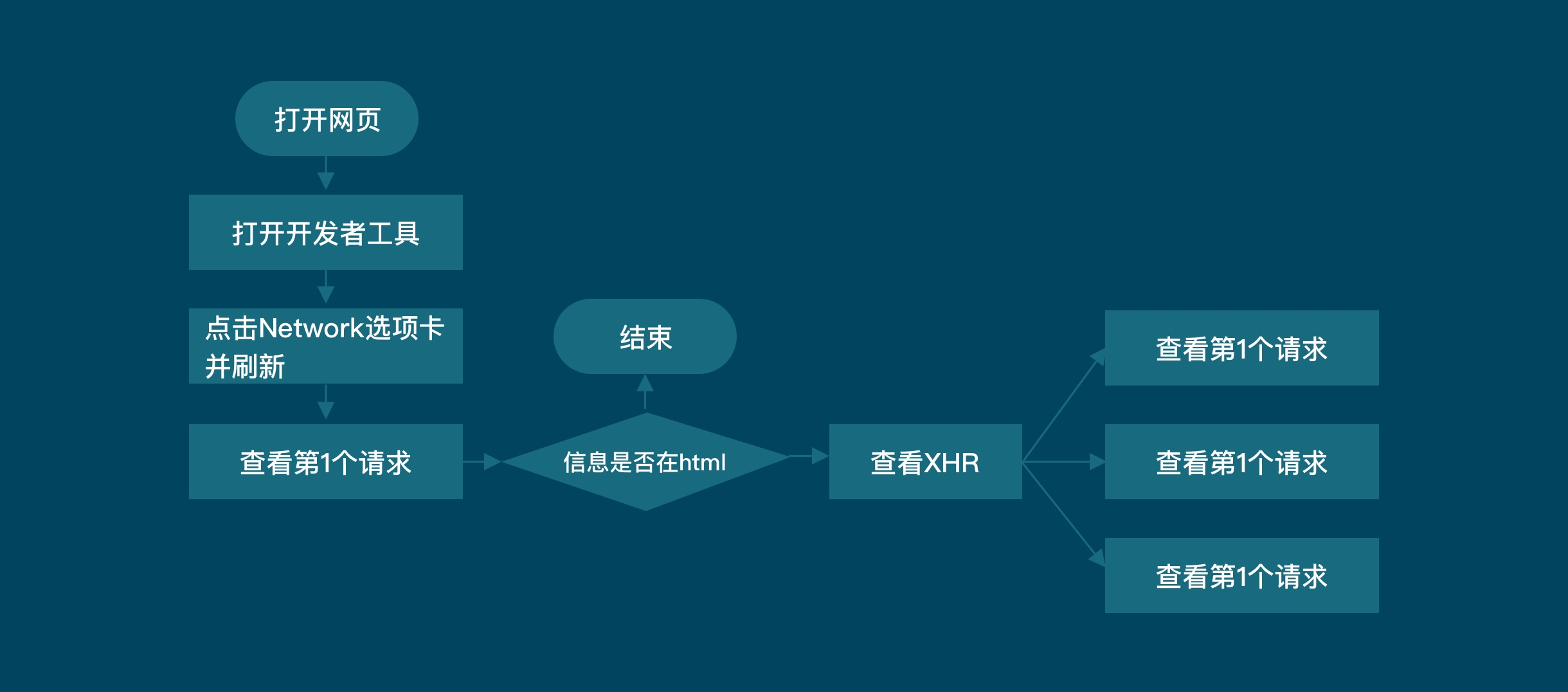
四. 带参数param可以请求不同数据, 带header可以伪装为浏览器
import requests
# 引用requests模块
for i in range(0,3):
url = 'https://movie.douban.com/j/search_subjects'
- header = {
'Origin': 'https://y.qq.com',
'Referer': 'https://y.qq.com/portal/search.html',
'Sec-Fetch-Mode': 'cors',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)'
}
param = {'type': 'movie',
'tag': '热门',
'sort': 'recommend',
'page_limit': '20',
'page_start': i*20}
# print(param)
res_movie = requests.get(url,params=param, headers=header)
# 调用get方法,下载电影列表
json_movie = res_movie.json()
# 使用json()方法,将response对象,转为列表/字典
# print(json_movie)
list_movies = json_movie['subjects']
# 一层一层地取字典,获取电影名称
for comment in list_movies:
# list_movies,comment是它里面的元素
print(comment['title'])
# 输出电影名名称
五.保存数据


python爬取数据分析的更多相关文章
- Python 爬取 热词并进行分类数据分析-[解释修复+热词引用]
日期:2020.02.02 博客期:141 星期日 [本博客的代码如若要使用,请在下方评论区留言,之后再用(就是跟我说一声)] 所有相关跳转: a.[简单准备] b.[云图制作+数据导入] c.[拓扑 ...
- 利用Python爬取朋友圈数据,爬到你开始怀疑人生
人生最难的事是自我认知,用Python爬取朋友圈数据,让我们重新审视自己,审视我们周围的圈子. 文:朱元禄(@数据分析-jacky) 哲学的两大问题:1.我是谁?2.我们从哪里来? 本文 jacky试 ...
- Python 爬取淘宝商品数据挖掘分析实战
Python 爬取淘宝商品数据挖掘分析实战 项目内容 本案例选择>> 商品类目:沙发: 数量:共100页 4400个商品: 筛选条件:天猫.销量从高到低.价格500元以上. 爬取淘宝商品 ...
- steam夏日促销悄然开始,用Python爬取排行榜上的游戏打折信息
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 不知不觉,一年一度如火如荼的steam夏日促销悄然开始了.每年通过大大小小 ...
- 用Python爬取B站、腾讯视频、爱奇艺和芒果TV视频弹幕!
众所周知,弹幕,即在网络上观看视频时弹出的评论性字幕.不知道大家看视频的时候会不会点开弹幕,于我而言,弹幕是视频内容的良好补充,是一个组织良好的评论序列.通过分析弹幕,我们可以快速洞察广大观众对于视频 ...
- 如何使用Python爬取基金数据,并可视化显示
本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理 以下文章来源于Will的大食堂,作者打饭大叔 前言 美国疫情越来越严峻,大选也进入 ...
- python爬取微信小程序(实战篇)
python爬取微信小程序(实战篇) 本文链接:https://blog.csdn.net/HeyShHeyou/article/details/90452656 展开 一.背景介绍 近期有需求需要抓 ...
- 用Python爬取分析【某东618】畅销商品销量数据,带你看看大家都喜欢买什么!
618购物节,辰哥准备分析一波购物节大家都喜欢买什么?本文以某东为例,Python爬取618活动的畅销商品数据,并进行数据清洗,最后以可视化的方式从不同角度去了解畅销商品中,名列前茅的商品是哪些?销售 ...
- 【Python爬虫案例】用Python爬取李子柒B站视频数据
一.视频数据结果 今天是2021.12.7号,前几天用python爬取了李子柒的油管评论并做了数据分析,可移步至: https://www.cnblogs.com/mashukui/p/1622025 ...
随机推荐
- 解决Invalid Plugin needs a valid package.json
首先.npm install -g plugman 然后,plugman create --name [插件名字] --plugin_id [插件id] 这样会生成一个除了pa ...
- vue install 组件
import share from './index.vue' export default { install: (Vue) => { Vue.prototype.$share = (opti ...
- Maya编程——沿Curve绘制圆柱
操作流程: 1. VS运行代码,生成插件 2. 打开Maya绘制曲线,加载插件 3. 选中绘制的曲线,运行插件 Posts1.0 代码: #include <maya/MSimple.h> ...
- .NET HttpWebRequest应用
提供基于HttpWebRequest的请求的应用类,其中包含:get请求(带参或不带参).post请求.文件传输请求 方法的具体说明: PostHttp:post请求,支持三种提交模式:FROM.JS ...
- mysql8.0 grant 创建账号及权限记录
针对 42000错误 原文:https://stackoverflow.com/questions/50177216/how-to-grant-all-privileges-to-root-user- ...
- webx入门
- Matlab 非线性规划问题模型代码
非线性规划问题的基本内容 非线性规划解决的是自变量在一定的非线性约束或线性约束组合条件下,使得非线性目标函数求得最大值或者最小值的问题. 当目标函数为最小值时,上述问题可以写成如下形式: \[ \mi ...
- day47——css介绍、语法结构、选择器、css权重
day47 今日内容 css介绍 CSS(Cascading Style Sheet,层叠样式表)定义如何显示HTML元素,给HTML设置样式,让它更加美观. 语法结构 div{ color:gree ...
- AVR单片机教程——EasyElectronics Library v1.2手册
索引: bit.h delay.h pin.h wave.h pwm.h led.h rgbw.h button.h switch.h segment.h 主要更新: 添加了segment.h的文档: ...
- pytest_05_fixture之conftest.py
前面一篇讲到用例加setup和teardown可以实现在测试用例之前或之后加入一些操作,但这种是整个脚本全局生效的,如果我想实现以下场景: 用例1需要先登录,用例2不需要登录,用例3需要先登录.很显然 ...