java线程基础巩固---分析Thread的join方法详细介绍,结合一个典型案例
关于Thread中的join方法貌似在实际多线程编程当中没怎么用过,在当初学j2se的时候倒时去学习过它的用法,不过现在早已经忘得差不多啦,所以对它再复习复习下。
首先先观察下JDK对它的介绍:

其实就是等待一个线程结束,对它记忆中还是有印象的,下面实践一下:
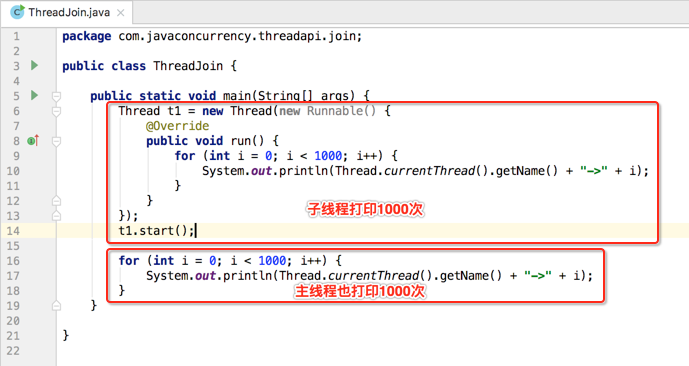
这时很显然打印是交替进行的:
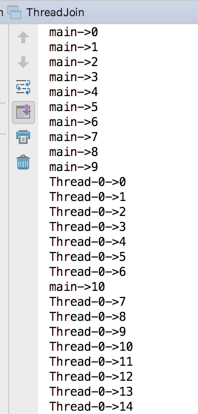
那如果我们想让子线程执行完了之后再执行主线程呢?这时就可以用join来实现啦,如下:

这时结果就是先输出子线程的,然后再输出主线程的了,那join的主要作用就是会等待线程执行完,另外需要注意:join()必须是在start()之后:

接下来对其代码进行修改:

那t1和t2打印结果会是顺序的么,也就是只有t1打印完了才会打印t2?看结果:
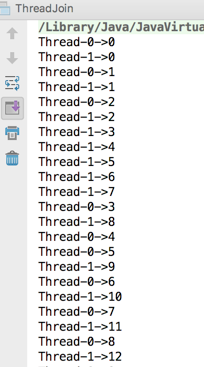
很显然是并行交替执行的,但main线程是在等t1和t2线程结束之后再执行的么?这个应该比较容易猜到,当然是啦:
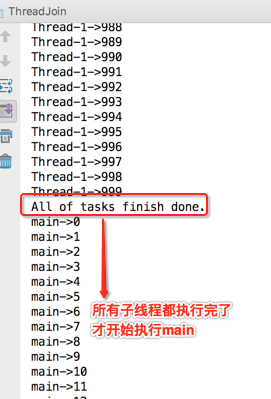
接下来用一下join()的另外两个重载:

这时编译运行:
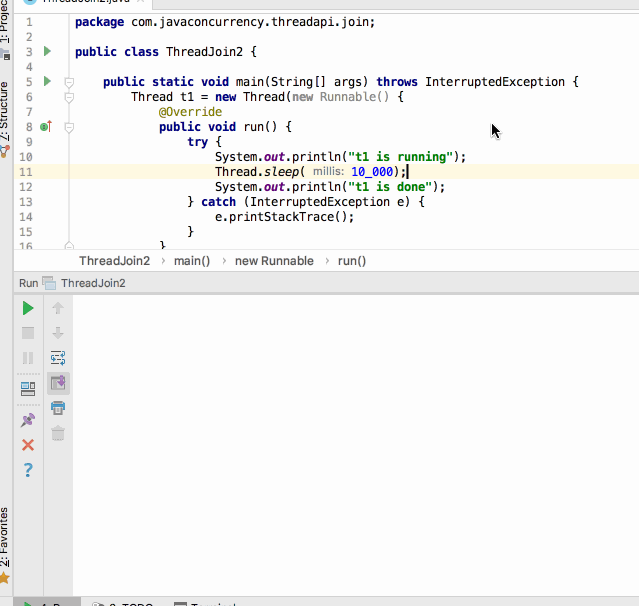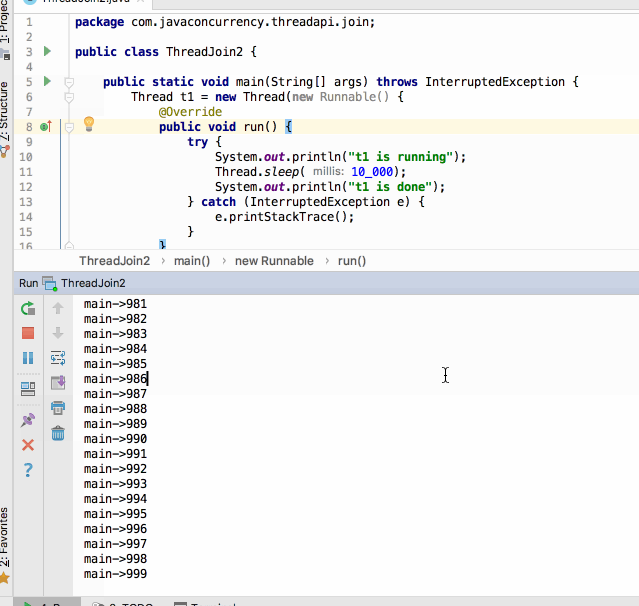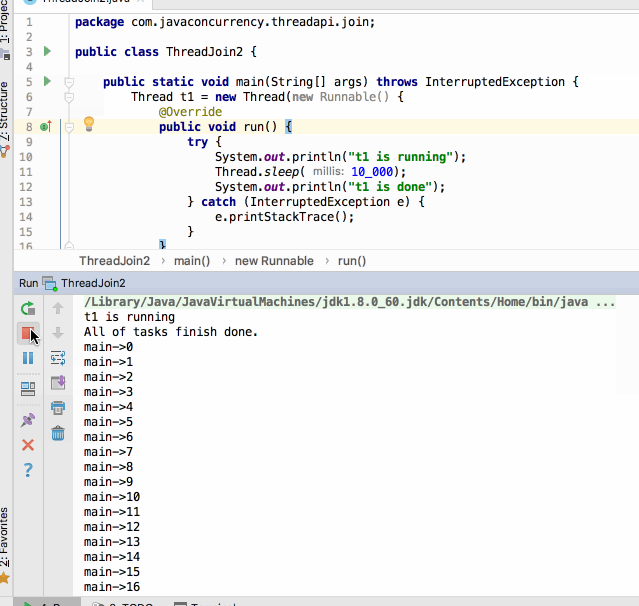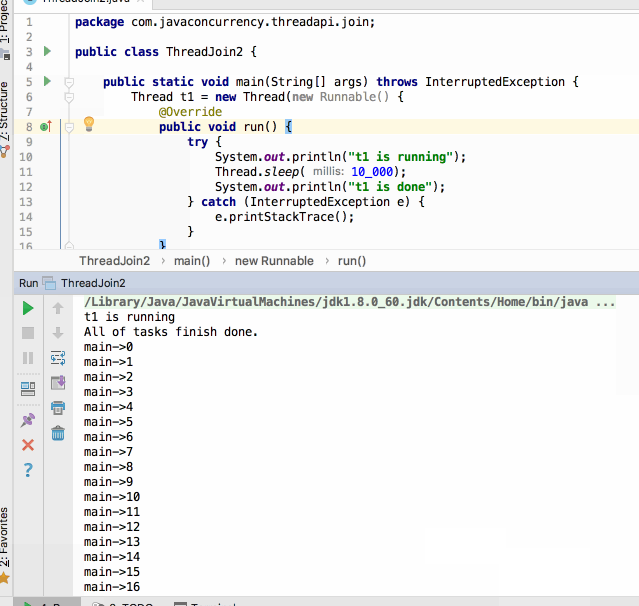
可以看到只等了100ms程序就开始往下执行main线程了,并且当子线程过了10s之后程序才退出,当然也可以给join传入一个ns:

具体就不运行了,这里看下面这种写法:
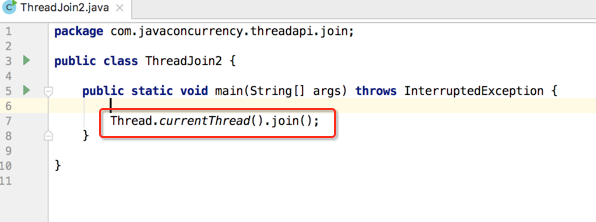
那运行之后会怎样?
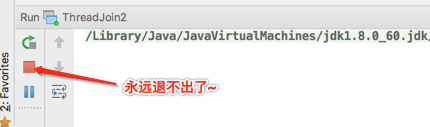
这是由于join()在等main线程退出,但是main线程又由于这句话永远退不出,所以就死循环了,这个在有些场合会用得到,先对这种写法有个大致的印象。
接下来通过一个小案例进一步来体会下join的用法:就是分别采集不同服务器的数据,而每台服务器数据的采集由一个单独的线程进行处理,每采集一条数据则需要将这数据进行入库,其中统计总数据采集的开始时间与结束时间,下面用代码来模拟下:
public class ThreadJoin3 {
public static void main(String[] args) throws InterruptedException {
long startTime = System.currentTimeMillis();
Thread t1 = new Thread(new CaptureRunnable("M1", 5000L));
Thread t2 = new Thread(new CaptureRunnable("M2", 7000L));
Thread t3 = new Thread(new CaptureRunnable("M3", 10000L));
t1.start();
t2.start();
t3.start();
long endTime = System.currentTimeMillis();
System.out.printf("Save data begin time is:%s, end time is:%s\n", startTime, endTime);
}
}
/**
* 采集数据的业务代码
*/
class CaptureRunnable implements Runnable {
/* 采集的机器名 */
private String machineName;
/* 采取花费的时间,直接由外部传过来模拟了 */
private long spendTime;
public CaptureRunnable(String machineName, long spendTime) {
this.machineName = machineName;
this.spendTime = spendTime;
}
@Override
public void run() {
//do the really capture data;
try {
Thread.sleep(spendTime);
System.out.printf(machineName + " completed data capture at time [%s] and successfully.\n", System.currentTimeMillis());
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public String getResult() {
return machineName + " finish.";
}
}
编译运行:
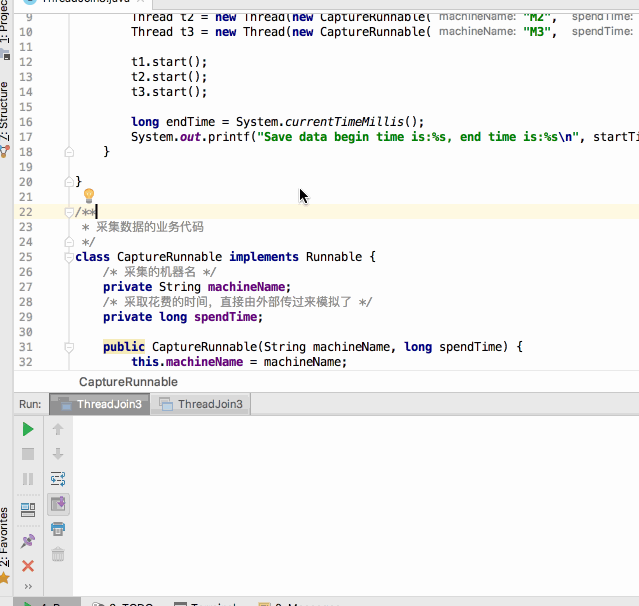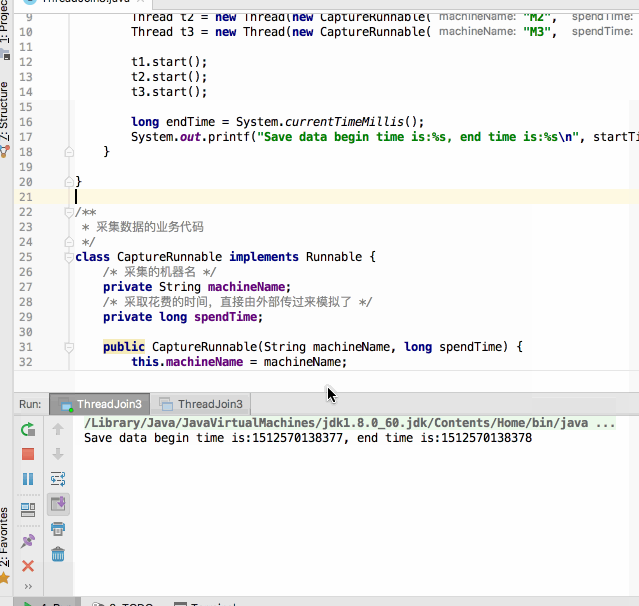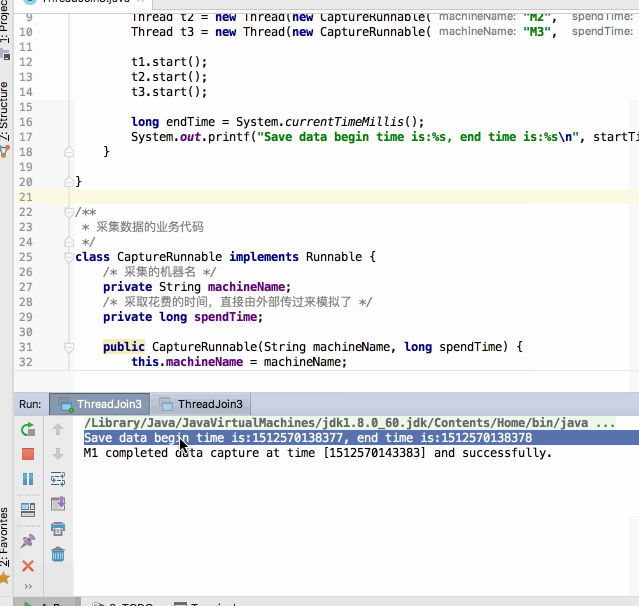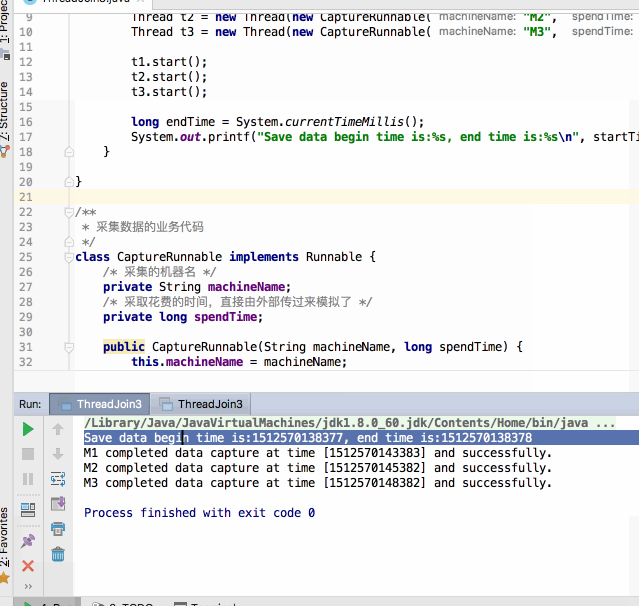
呃~~还没运行完其统计的开始时间与结束时间就已经提前打印出来了,那不是我们期望的,这时join()就可以很好的解决这个问题啦,修改代码如下:
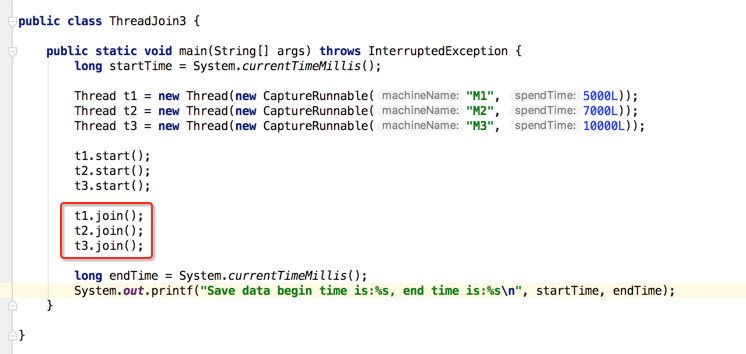
编译运行:
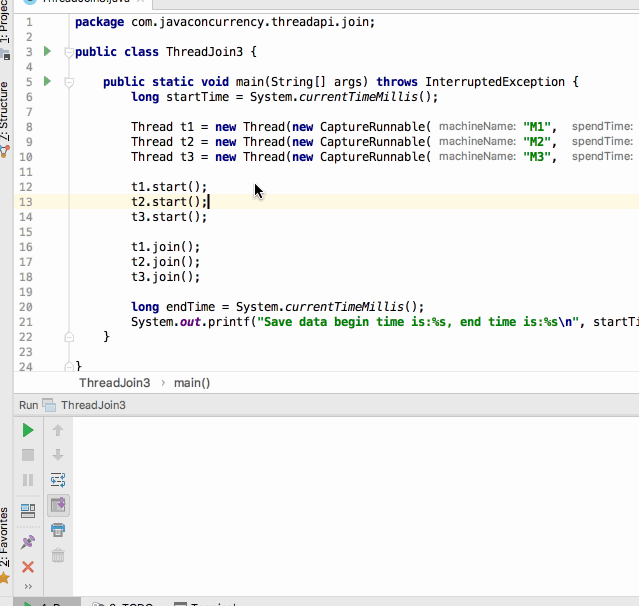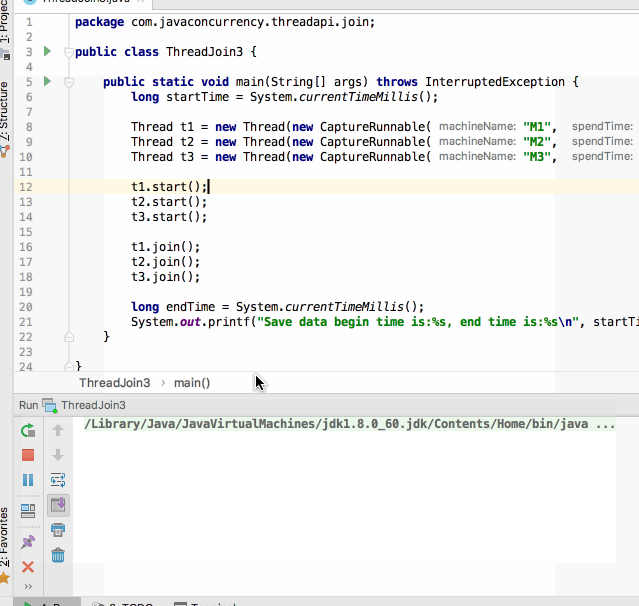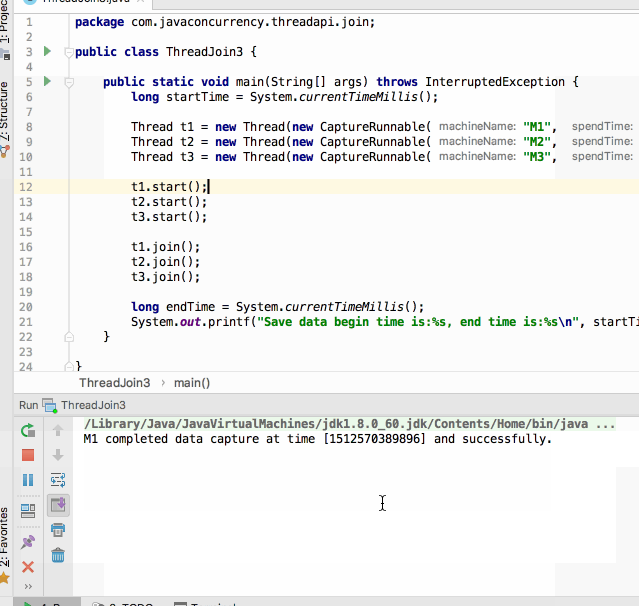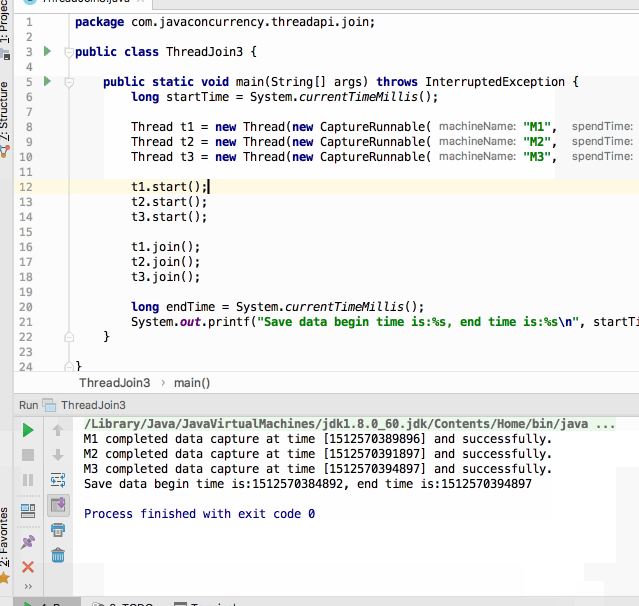
嗯~~完美解决~~
java线程基础巩固---分析Thread的join方法详细介绍,结合一个典型案例的更多相关文章
- Java线程:CountDownLatch 与Thread 的 join()
需求: 主程序中需要等待所有子线程完成后 再继续任务 两种实现方式: 一种使用join() 方法:当在当前线程中调用某个线程 thread 的 join() 方法时,当前线程就会阻塞,直到thread ...
- java线程基础巩固---构造Thread对象你也许不知道的几件事
关于Thread的构造在JDK文档中如下: 之后会把上面所有的构造都会学习到,这次主要是去研究一下图上标红的默认构造,当然大家肯定对于它都有些不屑,这有啥可学的,不new一个然后start线程不就启动 ...
- Thread中join()方法进行介绍
http://www.cnblogs.com/skywang12345/p/3479275.html https://blog.csdn.net/dabing69221/article/details ...
- Java 线程池原理分析
1.简介 线程池可以简单看做是一组线程的集合,通过使用线程池,我们可以方便的复用线程,避免了频繁创建和销毁线程所带来的开销.在应用上,线程池可应用在后端相关服务中.比如 Web 服务器,数据库服务器等 ...
- 【Java并发专题之二】Java线程基础
使用线程更好的提高资源利用率,但也会带来上下文切换的消耗,频繁的内核态和用户态的切换消耗,如果代码设计不好,可能弊大于利. 一.线程 进程是分配资源的最小单位,线程是程序执行的最小单位:线程是依附于进 ...
- Java 线程基础,从这篇开始
线程作为操作系统中最少调度单位,在当前系统的运行环境中,一般都拥有多核处理器,为了更好的充分利用 CPU,掌握其正确使用方式,能更高效的使程序运行.同时,在 Java 面试中,也是极其重要的一个模块. ...
- java 线程基础篇,看这一篇就够了。
前言: Java三大基础框架:集合,线程,io基本是开发必用,面试必问的核心内容,今天我们讲讲线程. 想要把线程理解透彻,这需要具备很多方面的知识和经验,本篇主要是关于线程基础包括线程状态和常用方法. ...
- JAVA线程基础
一.线程状态 由于参考的维度不一样,线程状态划分也不一样,我这里简单的分为5大类,并且会说明状态变迁的详细过程:
- 【Java线程与内存分析工具】VisualVM与MAT简明教程
目录 前言 VisualVM 安装与配置 本地使用 远程监控 MAT 使用场景 安装与配置 获得堆转储文件 分析堆转储文件 窥探对象内存值 堆转储文件对比分析 总结 前言 本文将简要介绍Java线程与 ...
随机推荐
- Java内存分析工具
内存分析工具 IDEA插件(VisualVM Launcher) 执行main函数的时候,同时启动jvisualvm,实时查看资源消耗情况.如图效果: Eclipse Memory Analyzer ...
- jmap使用
今天写的服务在处理大文件是出现Java heap space错误,因此结识了jmap jmap是JDK自带的一个工具,可以做jvm性能调优 可以生成dump文件,查询finalize执行队列.Java ...
- 查看LINUX进程内存占用情况及启动时间
可以直接使用top命令后,查看%MEM的内容.可以选择按进程查看或者按用户查看,如想查看oracle用户的进程内存使用情况的话可以使用如下的命令: (1) top top命令是Linux下常用的性能分 ...
- java8新特性(2)--接口的默认方法
1.默认方法的定义和作用 在Java8以前的版本中,由接口定义的方法是抽象的,不包括方法体.JDK8版本的发布改变了这一点,其中给接口添加了一个新的功能:默认方法.默认方法允许为接口方法定义默认实现. ...
- LeetCode 572. 另一个树的子树(Subtree of Another Tree) 40
572. 另一个树的子树 572. Subtree of Another Tree 题目描述 给定两个非空二叉树 s 和 t,检验 s 中是否包含和 t 具有相同结构和节点值的子树.s 的一个子树包括 ...
- Charles手机代理设置
Charles工具 手机 方法/步骤 1.打开Charles 点击Proxy,选择proxy settings,输入端口8888 打开电脑,在cmd中输入ipconfig,查看本地 ...
- 我的Vue朝圣之路2
1.创建第一个Vue案例 1. 引入Vue.js 2. 创建Vue对象 el : 指定根element(选择器) data : 初始化数据(页面可以访问) 3. 双向数据绑定 ...
- html中实现某区域内右键自定义菜单
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- HDFS-HA高可用集群搭建
HA高可用集群搭建 1.总体集群规划 在hadoop102.hadoop103和hadoop104三个节点上部署Zookeeper. hadoop102 hadoop103 hadoop104 Nam ...
- Disruptor与Netty实现百万级(十)
实体对象: import java.io.Serializable; public class TranslatorData implements Serializable { private sta ...