集合类源码(五)Collection之BlockingQueue(LinkedTransferQueue, PriorityBlockingQueue, SynchronousQueue)
LinkedTransferQueue
功能
全名
public class LinkedTransferQueue<E>
extends AbstractQueue<E>
implements TransferQueue<E>, Serializable
简述
基于链表的的无界队列。队列的头是某个生产者在队列中停留时间最长的元素。队列的尾部是某个生产者在队列中时间最短的元素。
注意,与大多数集合不同,size方法不是一个常量时间操作。由于这些队列的异步性,确定当前元素的数量需要遍历元素,因此如果在遍历期间修改此集合,可能会报告不准确的结果。
此外,批量操作addAll、removeAll、retainAll、containsAll、equals和toArray不能保证自动执行。例如,与addAll操作并发操作的迭代器可能只查看一些添加的元素。
从JDK1.7被引入,它既有SynchronousQueue的“交换”特性(还比SynchronousQueue多了用于存储的空间),也具有阻塞队列的“阻塞”特性(由于不加锁,性能比LinkedBlockingQueue要好得多)
方法
// 返回该队列中元素的Spliterator。返回的spliterator是弱一致的。
public Spliterator<E> spliterator() // 将指定的元素插入到此队列的末尾。因为队列是无界的,所以这个方法永远不会阻塞。
public void put(E e) // 将指定的元素插入到此队列的末尾。因为队列是无界的,所以这个方法永远不会阻塞或返回false。后两个参数不会被用到。
public boolean offer(E e, long timeout, TimeUnit unit) // 将指定的元素插入到此队列的末尾。因为队列是无界的,所以这个方法永远不会返回false。
public boolean offer(E e) // 将指定的元素插入到此队列的末尾。因为队列是无界的,所以这个方法永远不会抛出IllegalStateException或返回false。
public boolean add(E e) // 如果可能,立即将元素传输给等待的使用者。更准确地说,如果存在一个消费者已经在等待接收它(take()方法或超时的poll方法),则立即传输指定的元素,否则返回false而不排队该元素。
public boolean tryTransfer(E e) // 将元素传输给使用者,如有必要则等待。更准确地说,如果存在一个消费者已经在等待接收指定的元素(take()方法或超时的poll方法),则立即传输指定的元素,否则将在此队列的末尾插入指定的元素并等待,直到消费者接收到该元素。
public void transfer(E e) throws InterruptedException // 如果可以在超时之前将元素传输给使用者,则将其传输给使用者。更准确地说,如果存在一个消费者已经等待则立即转移指定的元素;否则在这个队列的尾部插入指定元素并等待,直到该元素被一个消费者接收到,如果元素可以被转移之前超时则返回false。
public boolean tryTransfer(E e, long timeout, TimeUnit unit) throws InterruptedException // 检索并删除此队列的头,如有必要则等待,直到某个元素可用为止。
public E take() throws InterruptedException // 检索并删除此队列的头,如果有必要,则需要等待指定的等待时间。
public E poll(long timeout, TimeUnit unit) throws InterruptedException // 检索并删除此队列的头,如果此队列为空,则返回null。
public E poll() // 从此队列中删除所有可用元素并将它们添加到给定集合中。此操作可能比重复轮询此队列更有效。在试图将元素添加到集合c时遇到失败抛出相关异常时可能会导致:元素不在原集合或者集合c中,或者两个集合中都没有。
public int drainTo(Collection<? super E> c) // 从该队列中最多删除给定数量的可用元素,并将它们添加到给定集合中。异常情况同上
public int drainTo(Collection<? super E> c, int maxElements) // 按适当的顺序返回此队列中元素的迭代器。元素将按从第一个(head)到最后一个(tail)的顺序返回。返回的迭代器是弱一致的。
public Iterator<E> iterator() // 检索但不删除此队列的头,在此队列为空时返回null。
public E peek() // 如果此队列不包含元素,则返回true。
public boolean isEmpty() // 如果至少有一个消费者在通过BlockingQueue.take()或超时的poll()方法等待接收元素,则返回true。
public boolean hasWaitingConsumer() // 返回此队列中的元素数量。如果此队列大于Integer.MAX_VALUE个元素,则返回Integer.MAX_VALUE。注意,与大多数集合不同,此方法不是常量时间操作。由于这些队列的异步性,确定当前元素的数量需要O(n)遍历。
public int size() // 返回通过BlockingQueue.take()或超时的poll()方法等待接收元素的消费者数量的估计值。返回值是事件瞬间状态的近似值,如果消费者已经完成或放弃等待,则返回值可能不准确。该值可能对监视和启发有用,但对同步控制没用。此方法的实现可能比TransferQueue.hasWaitingConsumer()方法的实现慢得多。
public int getWaitingConsumerCount() // 如果指定元素存在,则从此队列中移除第一个匹配的元素。
public boolean remove(Object o) // 如果此队列包含至少一个指定的元素,则返回true。
public boolean contains(Object o) // 总是返回 Integer.MAX_VALUE ,因为这是无界队列
public int remainingCapacity()
原理
凡是涉及到添加的方法:put、offer、offer(timeout)、add,都是不会阻塞,直接返回的。而这些方法都是调用的同一个方法:private E xfer(E e, boolean haveData, int how, long nanos)
涉及取出的方法:take、poll、poll(timeout),有数据则出队,无数据则阻塞。同样,这些方法都是调用的同一个方法:private E xfer(E e, boolean haveData, int how, long nanos)
由于这个方法被两种操作共用,仅仅按句注释,完全不知所以然,所以我拿出一个场景,按照代码走的过程解释一遍:take线程先启动,拿不到数据则阻塞;然后put线程向里面塞数据;
成员变量
/*
* Possible values for "how" argument in xfer method.
*/
private static final int NOW = 0; // for untimed poll, tryTransfer
private static final int ASYNC = 1; // for offer, put, add
private static final int SYNC = 2; // for transfer, take
private static final int TIMED = 3; // for timed poll, tryTransfer // put、offer、add: xfer(e, true, ASYNC, 0)
// take: xfer(null, false, SYNC, 0)
// poll: xfer(null, false, NOW, 0)
// timed poll: xfer(null, false, TIMED, unit.toNanos(timeout))
// transfer: xfer(e, true, SYNC, 0)
// tryTransfer: xfer(e, true, NOW, 0)
// timed tryTransfer: xfer(e, true, TIMED, unit.toNanos(timeout))
// ASYNC和NOW不阻塞;SYNC和TIMED会阻塞。
take线程尝试拿数据
// take线程: xfer(null, false, SYNC, 0)
private E xfer(E e, boolean haveData, int how, long nanos) {
if (haveData && (e == null))
throw new NullPointerException();
Node s = null; // the node to append, if needed retry:
for (;;) { // restart on append race
// 从head开始遍历(第一次插入时队列为空,也就是head为null,直接跳过循环)
for (Node h = head, p = h; p != null;) { // find & match first node
// 查看当前节点的状态:有数据则为true,无数据则为false
boolean isData = p.isData;
// 当前节点存储的数据
Object item = p.item;
if (item != p && (item != null) == isData) { // unmatched
// 不匹配的情况: put的时候发现head里有数据(isData = true,haveData = true),take的时候发现head里是个空节点(isData = false,haveData = false)
// 匹配的情况: put的时候发现head里是个空节点(isData = false,haveData = true),take的时候发现head里有数据(isData = true,haveData = false)
if (isData == haveData) // 不匹配则break
break;
if (p.casItem(item, e)) { // match
for (Node q = p; q != h;) {
Node n = q.next; // update by 2 unless singleton
if (head == h && casHead(h, n == null ? q : n)) {
h.forgetNext();
break;
} // advance and retry
if ((h = head) == null ||
(q = h.next) == null || !q.isMatched())
break; // unless slack < 2
}
LockSupport.unpark(p.waiter);
return LinkedTransferQueue.<E>cast(item);
}
}
Node n = p.next;
p = (p != n) ? n : (h = head); // Use head if p offlist
} if (how != NOW) { // No matches available
if (s == null)
s = new Node(e, haveData);
// 添加一个空节点new Node(null, false)
Node pred = tryAppend(s, haveData);
if (pred == null)
continue retry; // lost race vs opposite mode
if (how != ASYNC)
// 阻塞等待,直到节点里有数据,被put线程唤醒
return awaitMatch(s, pred, e, (how == TIMED), nanos);
}
return e; // not waiting
}
}
一句话:take线程拿不到数据,添加一个空节点然后等待
tryAppend
private Node tryAppend(Node s, boolean haveData) {
// 从尾部开始
for (Node t = tail, p = t;;) { // move p to last node and append
Node n, u; // temps for reads of next & tail
// 如果队列空,直接放在head的位置并返回
if (p == null && (p = head) == null) {
if (casHead(null, s))
return s; // initialize
}
// 如果无法将具有给定模式的节点追加到此节点,则返回true。因为此节点是不匹配的,并且具有相反的数据模式。
// 比如一个场景,take线程在执行上面casHead之前,put线程已经向队列里添加了数据,此时take线程再执行casHead是不会成功的,然后就会走cannotPrecede方法
else if (p.cannotPrecede(haveData))
return null; // lost race vs opposite mode
// 不是最后一个节点,则继续遍历
else if ((n = p.next) != null) // not last; keep traversing
p = p != t && t != (u = tail) ? (t = u) : // stale tail
(p != n) ? n : null; // restart if off list
// CAS插入到最后失败,向后遍历
else if (!p.casNext(null, s))
p = p.next; // re-read on CAS failure
else {
// 根据松弛阈值更新tail
if (p != t) { // update if slack now >= 2
while ((tail != t || !casTail(t, s)) &&
(t = tail) != null &&
(s = t.next) != null && // advance and retry
(s = s.next) != null && s != t);
}
return p;
}
}
}
awaiMatch
/**
* Spins/yields/blocks until node s is matched or caller gives up.
*
* @param s 等待的节点
* @param pred s的前驱,或者s本身(如果没有前驱),或者null(如果未知)
* @param e 检查匹配的比较值
* @param timed 如果为true,则只等待超时时间
* @param nanos 超时时间,只有在timed等于true时使用
* @return 返回匹配项,如果在中断或超时时未匹配,则返回e
*/
private E awaitMatch(Node s, Node pred, E e, boolean timed, long nanos) {
// 如果指定了超时,则计算超时时间
final long deadline = timed ? System.nanoTime() + nanos : 0L;
// 获取当前线程
Thread w = Thread.currentThread();
int spins = -1; // initialized after first item and cancel checks
ThreadLocalRandom randomYields = null; // bound if needed for (;;) {
// 等待节点的当前数据
Object item = s.item;
// 如果是take和timed poll方法,e为null。也就是说,当前数据不为null,证明此时等待线程可以返回了。
// 如果是transfer和timed tryTransfer方法,e为待添加的值。也就是说,当前数据为null被取走了,证明此时等待线程可以返回了。
if (item != e) { // matched
// assert item != s;
// 清除writer,不再等待
s.forgetContents(); // avoid garbage
return LinkedTransferQueue.<E>cast(item);
}
// 线程中断或者超时 并且 成功的将s的item设置为s
if ((w.isInterrupted() || (timed && nanos <= 0)) &&
s.casItem(e, s)) { // cancel
// 断开当前节点和pred的连接
unsplice(pred, s);
return e;
} // 自旋()
if (spins < 0) { // establish spins at/near front
// 计算自旋次数
if ((spins = spinsFor(pred, s.isData)) > 0)
randomYields = ThreadLocalRandom.current();
}
else if (spins > 0) { // spin
--spins;
if (randomYields.nextInt(CHAINED_SPINS) == 0)
// yield()方法会通知线程调度器放弃对处理器的占用,但调度器可以忽视这个通知。yield()方法主要是为了保障线程间调度的连续性,防止某个线程一直长时间占用cpu资源。
// 也就是让掉当前线程 CPU 的时间片,使正在运行中的线程重新变成就绪状态,并重新竞争 CPU 的调度权。它可能会获取到,也有可能被其他线程获取到。
Thread.yield(); // occasionally yield
}
// 如果当前节点的waiter为空,则设置为当前线程
else if (s.waiter == null) {
s.waiter = w; // request unpark then recheck
}
// 如果设置了超时
else if (timed) {
nanos = deadline - System.nanoTime();
if (nanos > 0L)
// 在指定的等待时间内,禁止当前线程用于线程调度
LockSupport.parkNanos(this, nanos);
}
else {
// 禁止当前线程用于线程调度
LockSupport.park(this);
}
}
}
=====总体来说,xfer的操作分为三个阶段:第一个在方法xfer中实现,第二个在tryAppend中实现,第三个在方法awaitMatch中实现。=====
1. 尝试匹配现有节点
从head开始,跳过已经匹配的节点,直到找到一个相反模式的不匹配节点(如果存在的话),在这种情况下匹配它并返回,如果有必要,也会将head更新到经过匹配节点的节点(如果列表中没有其他不匹配的节点,则是节点本身)。
如果CAS失败,那么循环将重试前进头两步,直到成功或在松弛阈值限制之下最多两步。2. 尝试添加一个新节点(方法tryAppend)
从当前尾部指针开始,找到实际的最后一个节点并尝试添加一个新节点(如果head为空,则建立第一个节点)。只有在其前一个节点已经匹配或具有相同模式的情况下,才可以添加节点。
如果检测到其他情况,则在遍历过程中必须附加一个模式相反的新节点,因此必须在阶段1重新启动。3.等待匹配或取消(方法awaitMatch)
等待另一个线程匹配节点;相反,如果当前线程被中断或等待超时,则取消。在多处理器上,我们使用队列前旋转:如果一个节点看起来是队列中第一个不匹配的节点,它会在阻塞之前旋转一点。
在这两种情况下,在阻塞之前,它会尝试将当前“head”和第一个不匹配的节点之间的任何节点进行反拼接。
队列前端旋转极大地提高了竞争激烈的队列的性能。只要它相对简短且“安静”,旋转就不会对竞争较少的队列的性能造成太大影响。
在spin期间,线程检查它们的中断状态并生成一个线程本地随机数来决定是否偶尔执行一个Thread.yield。
put线程添加数据
// put: xfer(e, true, ASYNC, 0)
private E xfer(E e, boolean haveData, int how, long nanos) {
if (haveData && (e == null))
throw new NullPointerException();
Node s = null; // the node to append, if needed retry:
for (;;) { // restart on append race
// 从head开始遍历
for (Node h = head, p = h; p != null;) { // find & match first node
// 此时队列里只有一个空节点,isData = false
boolean isData = p.isData;
// item = null
Object item = p.item;
if (item != p && (item != null) == isData) { // unmatched
// 由于isData=false,haveData=true,所以不走break
if (isData == haveData) // can't match
break;
// 直接把新数据e添加到当前空节点里(CAS:如果预期值null和内存值null相同,则将内存值替换成e)
if (p.casItem(item, e)) { // match
// 基于阈值的方法进行更新,松弛阈值为2。也就是说,当当前指针距离第一个或者最后一个节点有两个或更多步时,更新head/tail。
for (Node q = p; q != h;) {
Node n = q.next; // update by 2 unless singleton
if (head == h && casHead(h, n == null ? q : n)) {
h.forgetNext();
break;
} // advance and retry
if ((h = head) == null ||
(q = h.next) == null || !q.isMatched())
break; // unless slack < 2
}
// 唤醒阻塞的take线程
LockSupport.unpark(p.waiter);
// 返回
return LinkedTransferQueue.<E>cast(item);
}
}
Node n = p.next;
p = (p != n) ? n : (h = head); // Use head if p offlist
} if (how != NOW) { // No matches available
if (s == null)
s = new Node(e, haveData);
Node pred = tryAppend(s, haveData);
if (pred == null)
continue retry; // lost race vs opposite mode
if (how != ASYNC)
return awaitMatch(s, pred, e, (how == TIMED), nanos);
}
return e; // not waiting
}
}
这里是Debug的put过程,发现一个含有等待线程的空节点。

正常包含数据的节点不包含witer

工作过程
首先put操作都是无阻塞直接返回;当take线程来取数据的时候,发现没有数据,则先new一个空节点(isData属性为false,代表这个节点期望能够添加数据),如果队列为空,直接放在头结点的位置,队列不为空则放在尾节点后面。有多个take线程,则依次添加到尾节点。添加完毕则阻塞等待在节点上;当put线程添加数据的时候,如果发现存在take线程等待的空节点,则优先把数据放在空节点,并唤醒阻塞线程取走数据。
再解释一下“模式”
前面说到第一个阶段是从head开始,跳过已经匹配的节点,直到找到一个相反模式的不匹配节点。具体来讲就是:
put:haveData=true,与之相匹配节点的模式是isData=true,不匹配则属isData=false;
take:haveData=false,与之相匹配节点的模式是isData=false,不匹配则属isData=true;
优缺点
优点:集LinkedBlockingQueue,SynchronousQueue的优点于一身,同时利用CAS实现了无锁处理,性能得到很大的提高
缺点:无界队列,使用不当会消耗内存。
看过源码可以知道这个队列是没有锁的,那么怎样保证的线程安全?
可以看到,在核心方法里用了很多CAS方法,比如:casHead、casNext等等,其内部调用的都是UNSAFE的本地方法。实际上就是靠这些原子操作的CAS方法来保证的线程安全:原子操作,也就是同一时刻只有一个线程能执行,比如一个put和一个take线程同时执行到casHead(null, s)方法,由于原子性同一时刻只有一个能执行成功,等CPU调度到另一个线程的时候,这个方法是不能成功执行的,然后后面还有后续的判断来保证不出错。
你可能会问了,现在的CPU都是多核的,意味着在同一时刻多个线程可以并行处理,那么这个队列就不是安全的了。
首先操作系统有内核线程和用户线程之分:如果是用户线程,OS是无法感知的,真正的多核CPU处理的是内核级线程。用户线程的弊端之一就是不能利用多CPU资源。所以,应用里的线程还是CPU调度来模拟“并行”的假象。
PriorityBlockingQueue
功能
全名
public class PriorityBlockingQueue<E>
extends AbstractQueue<E>
implements BlockingQueue<E>, Serializable
简述
使用与PriorityQueue类相同的排序规则并提供阻塞检索操作的无界阻塞队列。虽然该队列在逻辑上是无界的,但是由于资源耗尽(OutOfMemoryError)可能导致尝试添加的操作失败。此类不允许空元素。依赖于自然排序的优先级队列也不允许插入不可比较的对象(这样做会导致ClassCastException)。
方法
// 将指定的元素插入此优先队列。
public boolean add(E e) // 将指定的元素插入此优先队列。因为队列是无界的,所以这个方法永远不会返回false。
public boolean offer(E e) // 将指定的元素插入此优先队列。因为队列是无界的,所以这个方法永远不会阻塞。
public void put(E e) // 将指定的元素插入此优先队列。因为队列是无界的,所以这个方法永远不会阻塞或返回false。
public boolean offer(E e, long timeout, TimeUnit unit) // 检索并删除此队列的头,如果此队列为空,则返回null。
public E poll() // 检索并删除此队列的头,如有必要则等待,直到某个元素可用为止。
public E take() throws InterruptedException // 检索并删除此队列的头,如有必要,则需要等待指定的超时时间。
public E poll(long timeout, TimeUnit unit) throws InterruptedException // 检索但不删除此队列的头,在此队列为空时返回null。
public E peek() // 返回用于对该队列中的元素排序的比较器,如果该队列使用其元素的自然排序,则返回null。
public Comparator<? super E> comparator() // 返回此集合中的元素数。如果队列元素大于Integer.MAX_VALUE,则只返回Integer.MAX_VALUE
public int size() // 因为是无界队列,总返回Integer.MAX_VALUE
public int remainingCapacity() // 如果指定元素存在,则从此队列中移除匹配到的第一个元素。
public boolean remove(Object o) // 如果此队列包含至少一个指定的元素,则返回true。
public boolean contains(Object o) // 返回一个数组,该数组包含此队列中的所有元素,按适当的顺序排列。返回的数组将是“安全的”,因为此队列不维护对它的引用。
public Object[] toArray() // 返回一个数组,该数组包含此队列中的所有元素,按适当的顺序排列;返回数组的运行时类型是指定数组的运行时类型。
public <T> T[] toArray(T[] a) // 返回此集合的字符串表示形式。
public String toString() // 从此队列中删除所有可用元素并将它们添加到给定集合中。此操作可能比重复轮询此队列更有效。在试图将元素添加到集合c时遇到失败抛出相关异常时可能会导致:元素不在原集合或者集合c中,或者两个集合中都没有。
public int drainTo(Collection<? super E> c) // 从该队列中最多删除给定数量的可用元素,并将它们添加到给定集合中。异常情况同上
public int drainTo(Collection<? super E> c, int maxElements) // 删除此队列中的所有元素。此调用返回后,队列将为空。
public void clear() // 返回此队列中元素的迭代器。迭代器不会以任何特定的顺序返回元素。返回的迭代器是弱一致的。
public Iterator<E> iterator() // 返回该队列中元素的Spliterator。返回的spliterator是弱一致的。
public Spliterator<E> spliterator()
原理
内部结构
优先队列的存储结构是一个数组,逻辑结构是一个平衡的二叉堆(小顶堆),你也可以传入自定义的Comparator来使之成为一个大顶堆。
成员变量
/**
* 初始容量
*/
private static final int DEFAULT_INITIAL_CAPACITY = 11;
/**
* 内部最大容量
*/
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
/**
* 队列存储结构
*/
private transient Object[] queue;
/**
* 队列元素数量
*/
private transient int size;
/**
* 比较器,如果为空,队列使用自然顺序排序
*/
private transient Comparator<? super E> comparator;
/**
* 重入锁
*/
private final ReentrantLock lock;
/**
* 当队列为空则阻塞
*/
private final Condition notEmpty;
add、put、offer(E, long, TimeUnit)都是调用的offer方法
public boolean offer(E e) {
if (e == null)
throw new NullPointerException();
final ReentrantLock lock = this.lock;
lock.lock();
int n, cap;
Object[] array;
// 只要元素数量大于等于当前容量,则执行扩容
while ((n = size) >= (cap = (array = queue).length))
tryGrow(array, cap);
try {
// 用户自定义的比较器
Comparator<? super E> cmp = comparator;
if (cmp == null)
// 使用自然顺序排序。在n的位置上插入e,执行siftUp操作,使得堆结构不变
siftUpComparable(n, e, array);
else
// 使用传入的比较器
siftUpUsingComparator(n, e, array, cmp);
// 元素数量 +1
size = n + 1;
// 通知阻塞的take线程
notEmpty.signal();
} finally {
lock.unlock();
}
return true;
}
// 计算出新容量,new一个新容量大小的数组,利用System.arraycopy方法把老数组内容复制到新数组。
private void tryGrow(Object[] array, int oldCap) {
lock.unlock(); // must release and then re-acquire main lock
Object[] newArray = null;
if (allocationSpinLock == 0 &&
UNSAFE.compareAndSwapInt(this, allocationSpinLockOffset,
0, 1)) {
try {
// 如果老容量小于64,则新容量=2*老容量+2;否则新容量=1.5*老容量
int newCap = oldCap + ((oldCap < 64) ?
(oldCap + 2) : // grow faster if small
(oldCap >> 1));
// 判断是否超过了最大容量
if (newCap - MAX_ARRAY_SIZE > 0) { // possible overflow
int minCap = oldCap + 1;
if (minCap < 0 || minCap > MAX_ARRAY_SIZE)
throw new OutOfMemoryError();
newCap = MAX_ARRAY_SIZE;
}
// 创建一个新数组
if (newCap > oldCap && queue == array)
newArray = new Object[newCap];
} finally {
allocationSpinLock = 0;
}
}
if (newArray == null) // back off if another thread is allocating
Thread.yield();
lock.lock();
if (newArray != null && queue == array) {
queue = newArray;
// 把老数组的内容复制到新数组
System.arraycopy(array, 0, newArray, 0, oldCap);
}
}
// 在k位置插入元素x,通过向上提升x直到它大于或等于其父节点或者是根节点,来保持堆不变。
private static <T> void siftUpComparable(int k, T x, Object[] array) {
Comparable<? super T> key = (Comparable<? super T>) x;
while (k > 0) {
// parent=(child-1)/2
int parent = (k - 1) >>> 1;
// parent的值
Object e = array[parent];
// 如果新元素大于等于父节点,break
if (key.compareTo((T) e) >= 0)
break;
array[k] = e;
// 小于父节点,则继续向上移动
k = parent;
}
// 最后把新元素插入到适当的位置
array[k] = key;
}
sfitUp过程如下。说白了添加就是把新元素放在最后,然后为了保持堆的性质,把新元素提升到合适的位置,保证每一棵子树的根都比左右孩子小。
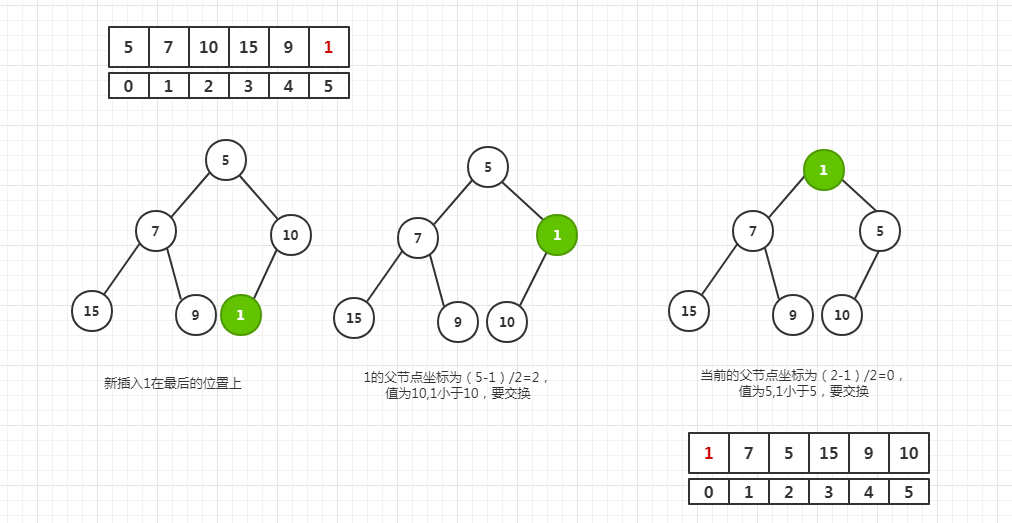
poll、take和timed poll
public E poll() {
final ReentrantLock lock = this.lock;
lock.lock();
try {
// 直接返回
return dequeue();
} finally {
lock.unlock();
}
}
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
E result;
try {
// 队列为空,阻塞
while ( (result = dequeue()) == null)
notEmpty.await();
} finally {
lock.unlock();
}
return result;
}
public E poll(long timeout, TimeUnit unit) throws InterruptedException {
long nanos = unit.toNanos(timeout);
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
E result;
try {
// 队列为空,阻塞一定时间
while ( (result = dequeue()) == null && nanos > 0)
nanos = notEmpty.awaitNanos(nanos);
} finally {
lock.unlock();
}
return result;
}
实际上出队调用的都是dequeue方法
private E dequeue() {
// 最后一个元素的下标
int n = size - 1;
// 队列空,返回null
if (n < 0)
return null;
else {
// 当前内部数组
Object[] array = queue;
// 保存队头元素
E result = (E) array[0];
// 临时变量保存数组最后一个元素,也就是队尾元素
E x = (E) array[n];
// 最后一个元素置空
array[n] = null;
Comparator<? super E> cmp = comparator;
// 根据有无比较器执行对应的siftDown操作
if (cmp == null)
// 这里可以看出,当出队的时候,先删除第一个元素,然后把最后一个元素添加到第一位。然后再进行整理以保证堆的性质不变。因为最后一个元素肯定比第一个大,所以要把它向下降级。
siftDownComparable(0, x, array, n);
else
siftDownUsingComparator(0, x, array, n, cmp);
// 修改size
size = n;
return result;
}
}
// 将元素x插入到k的位置,通过循环将x降级到树的下面,直到它小于或等于它的子元素,或者是叶子,从而保持堆不变。
// dequeue操作:k=0,x=最后一个元素,n=最后一个元素下标
private static <T> void siftDownComparable(int k, T x, Object[] array, int n) {
if (n > 0) {
Comparable<? super T> key = (Comparable<? super T>)x;
// 无符号右移1位,也就是n/2
int half = n >>> 1; // loop while a non-leaf
while (k < half) {
// child=2*parent+1(child存储的是左右孩子中较小的那一个)
int child = (k << 1) + 1; // 假设左孩子最小
// 当前节点的左孩子的值
Object c = array[child];
// 右孩子=左孩子+1
int right = child + 1;
// 右孩子的下标小于最后一个元素的下标,并且左孩子大于右孩子
if (right < n &&
((Comparable<? super T>) c).compareTo((T) array[right]) > 0)
// 此时,较小的孩子为右孩子,将右孩子的值和下标存起来
c = array[child = right];
// 如果此时元素x小于等于它孩子中较小的一个,break
if (key.compareTo((T) c) <= 0)
break;
array[k] = c;
// 大于孩子节点,继续向下
k = child;
}
// 最后把元素插到合适的位置
array[k] = key;
}
}
siftDown过程如下。说白了,出队就是把第一个元素删除,然后拿出最后一个元素x,从堆的第一个元素的位置k=0开始,x与左右孩子中较小的一个c相比较,如果x大,k指向c的位置,当前位置存储c,进入下一次比较;最后把x放在k指向的位置。
这里为什么不说“交换”了呢,因为这才是严谨的说法,在实际上也并没有比较一次交换一次,而是把仅仅把当前k的位置填充了c,c的原位置仍然存储的c,直到下一次比较出了结果。
在前面的入队过程,直接用了“交换”,因为这样比较直白,容易理解,但是要记住实际实现并不是“交换”。
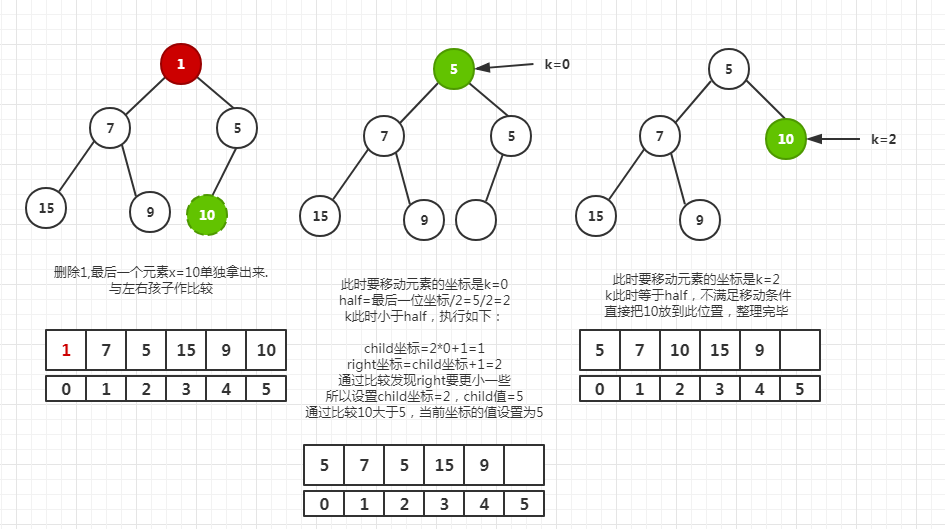
对于remove方法,是先找到目标的下标,然后根据情况做siftUp或者siftDown处理
public boolean remove(Object o) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
// 先找到下标
int i = indexOf(o);
if (i == -1)
return false;
// 移除指定位置的元素
removeAt(i);
return true;
} finally {
lock.unlock();
}
}
private void removeAt(int i) {
Object[] array = queue;
int n = size - 1;
// 特殊情况,移除最后一个元素,很好处理
if (n == i) // removed last element
array[i] = null;
else {
// 最后一个元素
E moved = (E) array[n];
array[n] = null;
Comparator<? super E> cmp = comparator;
if (cmp == null)
// 用最后一个元素moved填充到删除的i位置,然后为了保障堆性质,对moved做降级处理
siftDownComparable(i, moved, array, n);
else
siftDownUsingComparator(i, moved, array, n, cmp);
// 如果在i位置上的moved元素不需要做降级处理,则需要做提升处理
if (array[i] == moved) {
if (cmp == null)
siftUpComparable(i, moved, array);
else
siftUpUsingComparator(i, moved, array, cmp);
}
}
size = n;
}
优缺点
这个是PriorityQueue的阻塞队列版本,实现大致一样。优先级队列可以对任务进行排序,不过因为这个是个无界队列,生产者控制不好会有内存问题。
SynchronousQueue
功能
全名
public class SynchronousQueue<E>
extends AbstractQueue<E>
implements BlockingQueue<E>, Serializable
简述
一个阻塞队列,其中每个插入操作必须等待另一个线程的相应删除操作,反之亦然。同步队列没有任何内部容量。
您无法查看同步队列,因为一个元素只有在您试图删除它时才会出现;你不能插入一个元素(使用任何方法),除非另一个线程试图删除它;
您不能进行迭代,因为没有需要迭代的内容。队列的头是第一个队列插入线程试图添加到队列中的元素;如果没有这样的排队线程,那么就没有可以删除的元素,并且poll()将返回null。
它们非常适合于切换设计,在这种设计中,在一个线程中运行的对象必须与在另一个线程中运行的对象同步,以便传递一些信息、事件或任务。
该类支持一个可选的公平性策略,用于对正在等待的生产者和消费者线程进行排序。默认情况下,不保证这种顺序。但是,将公平性设置为true的队列将按FIFO顺序授予线程访问权。SynchronousQueue的内部实现了两个类,一个是TransferStack类,使用LIFO顺序存储元素,这个类用于非公平模式;还有一个类是TransferQueue,使用FIFI顺序存储元素,这个类用于公平模式。
方法
// 将指定的元素添加到此队列中,如有必要则等待另一个线程接收它。
public void put(E e) throws InterruptedException // 将指定的元素插入此队列,如有必要,将等待到指定的等待时间,以便另一个线程接收它。
public boolean offer(E e, long timeout, TimeUnit unit) throws InterruptedException // 如果另一个线程正在等待接收指定的元素,则将其插入此队列。
public boolean offer(E e) // 检索并删除此队列的头,如有必要等待另一个线程插入它。
public E take() throws InterruptedException // 检索并删除此队列的头,如有必要,则在超时时间之内等待另一个线程插入它。
public E poll(long timeout, TimeUnit unit) throws InterruptedException // 如果另一个线程当前正在使某个元素可用,则检索并删除此队列的头。
public E poll() // 总是返回true。同步队列没有内部容量。
public boolean isEmpty() // 总是返回0。同步队列没有内部容量。
public int size() // 总是返回0。同步队列没有内部容量。
public int remainingCapacity() // 什么也不做。同步队列没有内部容量。
public void clear() // 总是返回false。同步队列没有内部容量。
public boolean contains(Object o) // 总是返回false。同步队列没有内部容量。
public boolean remove(Object o) // 返回false,除非指定的集合为空。同步队列没有内部容量。
public boolean containsAll(Collection<?> c) // 总是返回false。同步队列没有内部容量。
public boolean removeAll(Collection<?> c) // 总是返回false。同步队列没有内部容量。
public boolean retainAll(Collection<?> c) // 总是返回null。除非主动等待,否则同步队列不会返回元素。
public E peek() // 返回一个空迭代器,其中hasNext总是返回false。
public Iterator<E> iterator() // 返回一个空的spliterator,其中对Spliterator.trysplit()的调用总是返回null。
public Spliterator<E> spliterator() // 返回一个0长度数组。
public Object[] toArray() // 将指定数组的zeroeth元素设置为null(如果数组长度非零)并返回它。
public <T> T[] toArray(T[] a) // 从此队列中删除所有可用元素并将它们添加到给定集合中。此操作可能比重复轮询此队列更有效。在试图将元素添加到集合c时遇到失败抛出相关异常时可能会导致:元素不在原集合或者集合c中,或者两个集合中都没有。
public int drainTo(Collection<? super E> c) // 从该队列中最多删除给定数量的可用元素,并将它们添加到给定集合中。异常情况同上
public int drainTo(Collection<? super E> c, int maxElements)
原理
首先transfer在SynchronousQueue就已经有体现了,只不过没有暴露给开发者。
abstract static class Transferer<E> {
/**
* Performs a put or take.
*
* @param e if non-null, the item to be handed to a consumer;
* if null, requests that transfer return an item
* offered by producer.
* @param timed if this operation should timeout
* @param nanos the timeout, in nanoseconds
* @return if non-null, the item provided or received; if null,
* the operation failed due to timeout or interrupt --
* the caller can distinguish which of these occurred
* by checking Thread.interrupted.
*/
abstract E transfer(E e, boolean timed, long nanos);
}
这个抽象类有两种实现,一个用于公平模式,一个用于非公平模式。
// 默认是非公平的
public SynchronousQueue() {
this(false);
}
// 也可以手动指定
public SynchronousQueue(boolean fair) {
transferer = fair ? new TransferQueue<E>() : new TransferStack<E>();
}
先简单说一句,对于put、timed offer方法,如果没有对应的消费者,则会阻塞,而offer方法如果没有消费者则直接返回;对于take、timed poll方法,如果没有对应的生产者,则会阻塞,而poll方法如果没有对应生产者则直接返回。
而他们调用的都是同一个方法:transfer,所以下面只分析这个方法。
关于公平与非公平:
公平模式:CAS + 利用FIFO队列先进先出的性质来阻塞多余的生产者和消费者,保证队头是等待时间最长的元素;
非公平模式:CAS + 利用LIFO栈先进后出的性质来阻塞多余的生产者和消费者,不保证生产消费顺序,容易出现饥渴的情况;
TransferStack
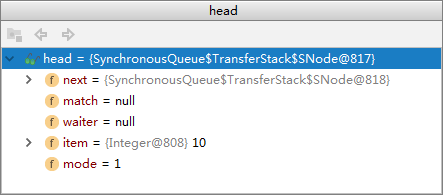
先来看一下成员变量(内部结构是一个链表,存储每一个阻塞的线程。当put阻塞的时候,mode=1;当take阻塞的时候,mode=0)
put
take
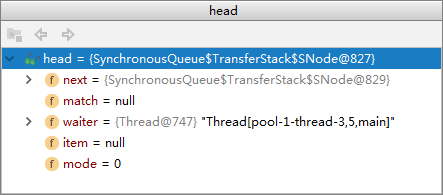
未完待续
TransferQueue
优缺点
集合类源码(五)Collection之BlockingQueue(LinkedTransferQueue, PriorityBlockingQueue, SynchronousQueue)的更多相关文章
- Java集合类源码解析:Vector
[学习笔记]转载 Java集合类源码解析:Vector 引言 之前的文章我们学习了一个集合类 ArrayList,今天讲它的一个兄弟 Vector.为什么说是它兄弟呢?因为从容器的构造来说,Vec ...
- JDK8集合类源码解析 - HashSet
HashSet 特点:不允许放入重复元素 查看源码,发现HashSet是基于HashMap来实现的,对HashMap做了一次“封装”. private transient HashMap<E,O ...
- Java集合类源码解析:HashMap (基于JDK1.8)
目录 前言 HashMap的数据结构 深入源码 两个参数 成员变量 四个构造方法 插入数据的方法:put() 哈希函数:hash() 动态扩容:resize() 节点树化.红黑树的拆分 节点树化 红黑 ...
- JDK1.8源码(五)——java.util.Vector类
JDK1.8源码(五)--java.lang. https://www.cnblogs.com/IT-CPC/p/10897559.html
- JUC源码分析-集合篇(九)SynchronousQueue
JUC源码分析-集合篇(九)SynchronousQueue SynchronousQueue 是一个同步阻塞队列,它的每个插入操作都要等待其他线程相应的移除操作,反之亦然.SynchronousQu ...
- Java集合类源码分析
常用类及源码分析 集合类 原理分析 Collection List Vector 扩充容量的方法 ensureCapacityHelper很多方法都加入了synchronized同步语句,来保 ...
- JDK1.8源码(五)——java.util.ArrayList 类
关于 JDK 的集合类的整体介绍可以看这张图,本篇博客我们不系统的介绍整个集合的构造,重点是介绍 ArrayList 类是如何实现的. 1.ArrayList 定义 ArrayList 是一个用数组实 ...
- Java集合类源码解析:ArrayList
目录 前言 源码解析 基本成员变量 添加元素 查询元素 修改元素 删除元素 为什么用 "transient" 修饰数组变量 总结 前言 今天学习一个Java集合类使用最多的类 Ar ...
- Java集合类源码解析:AbstractList
今天学习Java集合类中的一个抽象类,AbstractList. 初识AbstractList AbstractList 是一个抽象类,实现了List<E>接口,是隶属于Java集合框架中 ...
- Java集合类源码解析:AbstractMap
目录 引言 源码解析 抽象函数entrySet() 两个集合视图 操作方法 两个子类 参考: 引言 今天学习一个Java集合的一个抽象类 AbstractMap ,AbstractMap 是Map接口 ...
随机推荐
- 【转】Git使用教程之远程仓库
1.远程仓库 在了解之前,先注册github账号,由于你的本地Git仓库和github仓库之间的传输是通过SSH加密的,所以需要一点设置: 第一步:创建SSH Key.在用户主目录下,看看有没有.ss ...
- JavaWeb项目——博客系统
系统介绍 博客是互联网平台上的个人信息交流中心.通常博客就是用来发表文章,所有的文章都是按照年份和日期排列,有些类似斑竹的日记.看上去平淡无奇,毫无可炫耀之处,但它可以让每个人零成本.零维护地创建自己 ...
- [Caliburn.Micro专题][1]快速入门
目录 1. 什么是Caliburn.Micro? 2. 我是否需要学习CM框架? 3. 如何下手? 3.1 需要理解以下几个概念: 3.2 工程概览 3.3 示例代码 开场白:本系列为个人学习记录,才 ...
- Spring Cloud Eureka的自我保护模式与实例下线剔除
之前我说明了Eureka注册中心的保护模式,由于在该模式下不能剔除失效节点,故按原有配置在实际中不剔除总感觉不是太好,所以深入研究了一下.当然,这里重申一下,不管实例是否有效剔除,消费端实现Ribbo ...
- 还是畅通工程 HDU - 1233
题目链接:https://vjudge.net/problem/HDU-1233 思路: 最小生成树板子. #include <iostream> #include <stdio.h ...
- layer.js的一些常用的技巧
我们在一些弹出框或者其他的一些表单的样式逻辑当中会用到layer的组件,针对我遇到的问题做个小结 1.在使用checkbox进行多选的时候,默认的layer会有一个对勾的样式,但是我们通常在做单选或者 ...
- css 盒子下
1.padding 有小属性 padding-top: 30px; padding-right: 30px; padding-bottom: 30px; padding-left: 30px; 小属性 ...
- JS高阶---变量与函数提升
大纲: 主体: 案例1: 接下来在控制台source里进行断点测试 打好断点后,在控制台测试window .
- InfoQ一波文章:AdaSearch/JAX/TF_Serving/leon.bottou.org/Neural_ODE/NeurIPS_2018最佳论文
和 Nested Partition 有相通之处? 伯克利提出 AdaSearch:一种用于自适应搜索的逐步消除方法 在机器学习领域的诸多任务当中,我们通常希望能够立足预先给定的固定数据集找出问题的答 ...
- 每天一道Rust-LeetCode(2019-06-10)
每天一道Rust-LeetCode(2019-06-02) Z 字形变换 坚持每天一道题,刷题学习Rust. 题目描述 https://leetcode-cn.com/problems/simplif ...