SGD的动量(Momentum)算法
引入动量(Momentum)方法一方面是为了解决“峡谷”和“鞍点”问题;一方面也可以用于SGD 加速,特别是针对高曲率、小幅但是方向一致的梯度。
- 如果把原始的 SGD 想象成一个纸团在重力作用向下滚动,由于质量小受到山壁弹力的干扰大,导致来回震荡;或者在鞍点处因为质量小速度很快减为 0,导致无法离开这块平地。
- 动量方法相当于把纸团换成了铁球;不容易受到外力的干扰,轨迹更加稳定;同时因为在鞍点处因为惯性的作用,更有可能离开平地。
- 动量方法以一种廉价的方式模拟了二阶梯度(牛顿法)
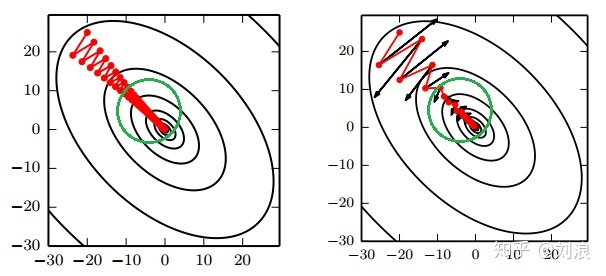
Momentum 梯度下降法,就是计算了梯度的指数加权平均数,并以此来更新权重,它的运行速度几乎总是快于标准的梯度下降算法。
SGD的动量(Momentum)算法的更多相关文章
- Adam那么棒,为什么还对SGD念念不忘 (3)—— 优化算法的选择与使用策略
在前面两篇文章中,我们用一个框架梳理了各大优化算法,并且指出了以Adam为代表的自适应学习率优化算法可能存在的问题.那么,在实践中我们应该如何选择呢? 本文介绍Adam+SGD的组合策略,以及一些比较 ...
- 动量Momentum梯度下降算法
梯度下降是机器学习中用来使模型逼近真实分布的最小偏差的优化方法. 在普通的随机梯度下降和批梯度下降当中,参数的更新是按照如下公式进行的: W = W - αdW b = b - αdb 其中α是学习率 ...
- 简单认识Adam优化器
转载地址 https://www.jianshu.com/p/aebcaf8af76e 基于随机梯度下降(SGD)的优化算法在科研和工程的很多领域里都是极其核心的.很多理论或工程问题都可以转化为对目标 ...
- 深度学习——优化器算法Optimizer详解(BGD、SGD、MBGD、Momentum、NAG、Adagrad、Adadelta、RMSprop、Adam)
在机器学习.深度学习中使用的优化算法除了常见的梯度下降,还有 Adadelta,Adagrad,RMSProp 等几种优化器,都是什么呢,又该怎么选择呢? 在 Sebastian Ruder 的这篇论 ...
- 【深度学习】深入理解优化器Optimizer算法(BGD、SGD、MBGD、Momentum、NAG、Adagrad、Adadelta、RMSprop、Adam)
在机器学习.深度学习中使用的优化算法除了常见的梯度下降,还有 Adadelta,Adagrad,RMSProp 等几种优化器,都是什么呢,又该怎么选择呢? 在 Sebastian Ruder 的这篇论 ...
- 机器学习中几种优化算法的比较(SGD、Momentum、RMSProp、Adam)
有关各种优化算法的详细算法流程和公式可以参考[这篇blog],讲解比较清晰,这里说一下自己对他们之间关系的理解. BGD 与 SGD 首先,最简单的 BGD 以整个训练集的梯度和作为更新方向,缺点是速 ...
- 神经网络优化方法总结:SGD,Momentum,AdaGrad,RMSProp,Adam
1. SGD Batch Gradient Descent 在每一轮的训练过程中,Batch Gradient Descent算法用整个训练集的数据计算cost fuction的梯度,并用该梯度对模型 ...
- 优化方法:SGD,Momentum,AdaGrad,RMSProp,Adam
参考: https://blog.csdn.net/u010089444/article/details/76725843 1. SGD Batch Gradient Descent 在每一轮的训练过 ...
- 深度学习必备:随机梯度下降(SGD)优化算法及可视化
补充在前:实际上在我使用LSTM为流量基线建模时候,发现有效的激活函数是elu.relu.linear.prelu.leaky_relu.softplus,对应的梯度算法是adam.mom.rmspr ...
随机推荐
- golang实战--家庭收支记账软件(面向过程)
1.开发流程 2.目标 模拟实现一个基于文本界面的(家庭记账软件) : 初步掌握编程技巧和调试技巧: 主要包含以下知识点:局部变量和基本数据类型.循环语句.分支语句.简单屏幕格式输出.面向对象编程: ...
- 【转】pywinauto教程
一.环境安装 1.命令行安装方法 pip install pywinauto==0.6.7 2.手动安装方法 安装包下载链接:pyWin32: python调用windows api的库https:/ ...
- 五、Spring之自动装配
Spring之自动装配 Spring利用依赖注入(DI),完成对IOC容器中各个组件依赖关系的赋值. [1]@Autowired @Autowired 注解,它可以对类成员变量.方法及构造函数进行 ...
- python asyncio asyncio wait
import asyncio import time async def get_html(url): print("start get url") await asyncio.s ...
- Rust从入门到放弃(1)—— hello,world
安装及环境配置 特点:安全,性能,并发 rust源配置 RLS安装 cargo rust管理工具,该工具可以愉快方便的管理rust工程 #!/bin/bash mkdir learn cd learn ...
- 将VMWare中的虚拟机时间设定在一个固定值
1.关闭虚拟机 2.用记事本打开虚拟机的.vmx文件 在末尾添加添加: tools.syncTime = "FALSE" time.synchronize.continue = ...
- Java生鲜电商平台-RBAC系统权限的设计与架构
Java生鲜电商平台-RBAC系统权限的设计与架构 说明:根据上面的需求描述以及对需求的分析,我们得知通常的一个中小型系统对于权限系统所需实现的功能以及非功能性的需求,在下面我们将根据需求从技术角度上 ...
- oracle 创建表、删除表、添加字段、删除字段、表备注、字段备注、修改表属性
1.创建表 create table 表名( classid number() primary key, 表字段 数据类型 是否允许为空(not null:不为空/null:允许空) 默认值(defa ...
- windows下编写dll
dll的优点 简单的说,dll有以下几个优点: 1) 节省内存.同一个软件模块,若是以源代码的形式重用,则会被编译到不同的可执行程序中,同时运行这些exe时这些模块的二进制码会被重复加载到内存中.如果 ...
- MySQL的select(极客时间学习笔记)
查询语句 首先, 准备数据, 地址是: https://github.com/cystanford/sql_heros_data, 除了id以外, 24个字段的含义如下: 查询 查询分为单列查询, 多 ...