myeclipse配置hadoop开发环境
1、安装Hadoop开发插件
hadoop安装包contrib/目录下有个插件hadoop-0.20.2-eclipse-plugin.jar,拷贝到myeclipse根目录下/dropins目录下。
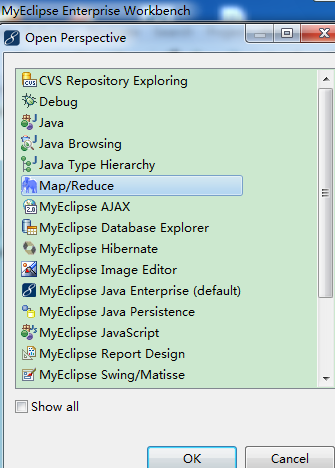
2、 启动myeclipse,打开Perspective:
【Window】->【Open Perspective】->【Other...】->【Map/Reduce】->【OK】
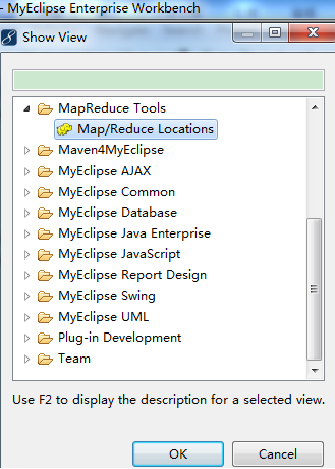
3、 打开一个View:
【Window】->【Show View】->【Other...】->【MapReduce Tools】->【Map/Reduce Locations】->【OK】
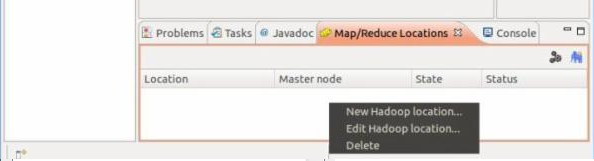
4、 添加Hadoop location:
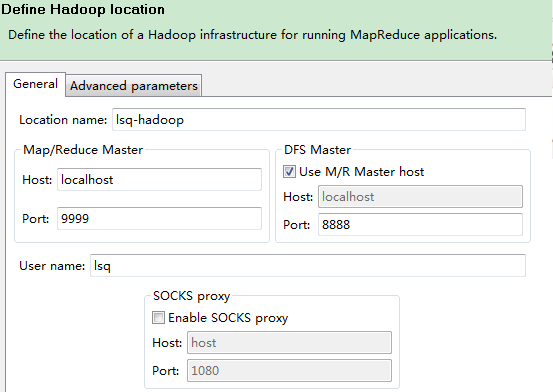
location name: 我填写的是:localhost.
Map/Reduce Master 这个框里
Host:就是jobtracker 所在的集群机器,这里写localhost
Hort:就是jobtracker 的port,这里写的是9999
这两个参数就是mapred-site.xml里面mapred.job.tracker里面的ip和port
DFS Master 这个框里
Host:就是namenode所在的集群机器,这里写localhost
Port:就是namenode的port,这里写8888
这两个参数就是core-site.xml里面fs.default.name里面的ip和port
(Use M/R master host,这个复选框如果选上,就默认和Map/Reduce Master这个框里的host一样,如果不选择,就可以自己定义输入,这里jobtracker 和namenode在一个机器上,所以是一样的,就勾选上)
user name:这个是连接hadoop的用户名,因为我是用lsq用户安装的hadoop,而且没建立其他的用户,所以就用lsq。下面的不用填写。
然后点击finish按钮,此时,这个视图中就有多了一条记录。
重启myeclipse并重新编辑刚才建立的那个连接记录,现在我们编辑advance parameters tab页

(重启编辑advance parameters tab页原因:在新建连接的时候,这个advance paramters tab页面的一些属性会显示不出来,显示不出来也就没法设置,所以必须重启一下eclipse再进来编辑才能看到)
这里大部分的属性都已经自动填写上了,其实就是把core-defaulte.xml、hdfs-defaulte.xml、mapred-defaulte.xml里面的一些配置属性展示出来。因为在安装hadoop的时候,其site系列配置文件里有改动,所以这里也要弄成一样的设置。主要关注的有以下属性:
fs.defualt.name:这个在General tab页已经设置了
mapred.job.tracker:这个在General tab页也设置了
dfs.replication:这个这里默认是3,因为我在hdfs-site.xml里面设置成了1,所以这里也要设置成1
hadoop.job.ugi:这里要填写:lsq,Tardis,逗号前面的是连接的hadoop的用户,逗号后面就写死Tardis(这个属性不知道我怎么没有...)
然后点击finish,然后就连接上了(先要启动sshd服务,启动hadoop进程),连接上的标志如图:
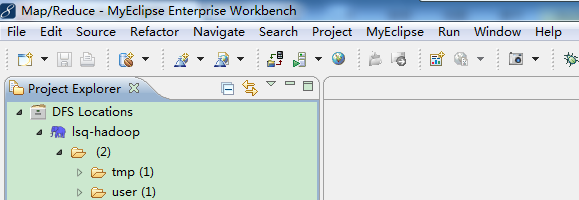
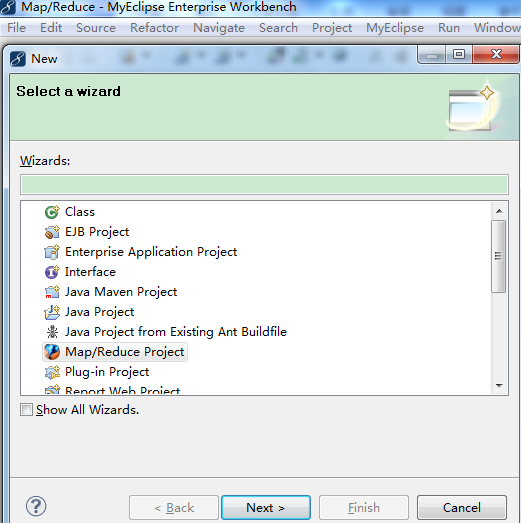
5、新建Map/Reduce Project:
【File】->【New】->【Project...】->【Map/Reduce】->【Map/Reduce Project】->【Project name: WordCount】->【Configure Hadoop install directory...】->【Hadoop installation directory: D:\cygwin\home\lsq\hadoop-0.20.2】->【Apply】->【OK】->【Next】->【Allow
output folders for source folders】->【Finish】
6、新建WordCount类:

添加/编写源代码:
D:\cygwin\home\lsq\hadoop-0.20.2/src/examples/org/apache/hadoop/examples/WordCount.java
package org.apache.hadoop.examples;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
7、上传模拟数据文件夹。
为了运行程序,需要一个输入的文件夹和输出的文件夹。输出文件夹,在程序运行完成后会自动生成。我们需要给程序一个输入文件夹。
(1)、在当前目录(如hadoop安装目录)下新建文件夹input,并在文件夹下新建两个文件file1、file2,这两个文件内容分别如下:
file1
- Hello World Bye World
file2
- Hello Hadoop Goodbye Hadoop
(2)、.将文件夹input上传到分布式文件系统中。
在已经启动Hadoop守护进程终端中cd 到hadoop安装目录,运行下面命令:
- bin/hadoop fs -put input in
8、 配置运行参数:
①在新建的项目WordCount,点击WordCount.java,右键-->Run As-->Run Configurations
②在弹出的Run Configurations对话框中,点Java Application,右键-->New,这时会新建一个application名为WordCount
③配置运行参数,点Arguments,在Program arguments中输入“你要传给程序的输入文件夹和你要求程序将计算结果保存的文件夹”,如:

(如果运行时报java.lang.OutOfMemoryError: Java heap space 配置VM arguments(在Program arguments下)
-Xms512m -Xmx1024m -XX:MaxPermSize=256m
)
8、点击Run,运行程序
点击Run,运行程序,过段时间将运行完成,等运行结束后,可以在终端中用命令如下,查看是否生成文件夹output:
bin/hadoop fs -ls
用下面命令查看生成的文件内容:
bin/hadoop
fs -cat output/*
如果显示如下,说明已经成功在myeclipse下运行第一个MapReduce程序了。
- Bye 1
- Goodbye 1
- Hadoop 2
- Hello 2
- World 2
myeclipse配置hadoop开发环境的更多相关文章
- 第五章 MyEclipse配置hadoop开发环境
1.首先要下载相应的hadoop版本的插件,我这里就给2个例子: hadoop-1.2.1插件:http://download.csdn.net/download/hanyongan300/62381 ...
- 搭建基于MyEclipse的Hadoop开发环境
不多说,直接上干货! 前面我们已经搭建了一个伪分布模式的Hadoop运行环境.请移步, hadoop-2.2.0.tar.gz的伪分布集群环境搭建(单节点) 我们绝大多数都习惯在Eclipse或MyE ...
- Hadoop_配置Hadoop开发环境(Eclipse)
通常我们可以用Eclipse作为Hadoop程序的开发平台. 1) 下载Eclipse 下载地址:http://www.eclipse.org/downloads/ 根据操作系统类型,选择合适的版本 ...
- Eclipse配置Hadoop开发环境
Step 1:选择Hadoop版本对应的Eclipse插件jar包(可自行编译),我的Hadoop版本是hadoop-0.20.2,对应的插件应该是:hadoop-0.20.2-eclipse-plu ...
- 配置Hadoop开发环境(Eclipse)
参考博文: http://blog.csdn.net/zythy/article/details/17397153 http://www.tuicool.com/articles/AjUZrq 注意事 ...
- IDEA配置Hadoop开发环境&编译运行WordCount程序
有关hadoop及java安装配置请见:https://www.cnblogs.com/lxc1910/p/11734477.html 1.新建Java project: 选择合适的jdk,如图所示: ...
- Eclipse安装Hadoop插件配置Hadoop开发环境
一.编译Hadoop插件 首先需要编译Hadoop 插件:hadoop-eclipse-plugin-2.6.0.jar,然后才可以安装使用. 第三方的编译教程:https://github.com/ ...
- 在Fedora18上配置个人的Hadoop开发环境
在Fedora18上配置个人的Hadoop开发环境 1. 背景 文章中讲述了类似于"personalcondor"的一种"personal hadoop" ...
- Mac OS X上搭建伪分布式CDH版本Hadoop开发环境
最近在研究数据挖掘相关的东西,在本地 Mac 环境搭建了一套伪分布式的 hadoop 开发环境,采用CDH发行版本,省时省心. 参考来源 How-to: Install CDH on Mac OSX ...
随机推荐
- python 文件操作(二) 替换性修改文件内容
正常情况我们想要仅对文件某一行的内容进行修改,而不改变其他内容,在原文件的基础上不能修改,因为当我们对原文件进行写操作时,如果原文件里面有内容,就会清空,在这种情况下,只能对文件进行替换性修改:即重新 ...
- windows操作笔记
使用服务或其他windows应用的过程中,可能会遇到莫名其妙的错误,这时候从控制面板中,找到管理工具,打开事件查看器,或者通过计算机管理,找到日志中的记录,如果是代码错误,会给出提示信息,比如之前在写 ...
- 儿子写日记 : " 夜深了,妈妈在打麻将,爸爸在上网……"
儿子写日记 : " 夜深了,妈妈在打麻将,爸爸在上网……" 爸爸检查时,很不满意地说 : " 日记源于生活,但要高于生活 !" ...
- 在java中获取Map集合中的key和value值
- 简单的发红包的PHP算法
假设有有10元钱 ,发给10个人.保证每个人都有钱拿,最少分得0.01.我们最先想到的肯定就是随机.0.01-10随机.但是会出现第一个人就分得9.99的情况.下面就没人可分了.然后就是我的错误思路 ...
- HDU1272 迷宫通路数
Problem Description 上次Gardon的迷宫城堡小希玩了很久(见Problem B),现在她也想设计一个迷宫让Gardon来走.但是她设计迷宫的思路不一样,首先她认为所有的通道都应该 ...
- [HDU3065]病毒持续侵袭中(AC自动机)
传送门 AC自动机的又一模板,统计每个字符串在文本中的次数. 所以就不需要vis数组了. ——代码 #include <cstdio> #include <cstring> # ...
- Linux Awk使用案例总结
知识点: 1)数组 数组是用来存储一系列值的变量,可通过索引来访问数组的值. Awk中数组称为关联数组,因为它的下标(索引)可以是数字也可以是字符串. 下标通常称为键,数组元素的键和值存储在Awk程序 ...
- [Usaco2007 Oct] Super Paintball超级弹珠
Time Limit: 5 Sec Memory Limit: 64 MBSubmit: 489 Solved: 384[Submit][Status][Discuss] Description ...
- CODEVS5565 二叉苹果树
n<=100个点的根为1的二叉树,树边上有苹果,求保留Q<=n条边的最多苹果数. 树形DP,f[i][j]--节点i为根的子树保留j条边最优方案,f[i][0]=0,f[i][j]=max ...