第3节 hive高级用法:15、hive的数据存储格式介绍
hive当中的数据存储格式:
行式存储:textFile sequenceFile 都是行式存储
列式存储:orc parquet 可以使我们的数据压缩的更小,压缩的更快
数据查询的时候尽量不要用select * 只选取我们需要的字段即可
hive的数据存储格式:用的比较多的一种行式存储 : textfile
用的比较多的列式存储: orc parquet
其中orc底层有自带的一种压缩算法,会对数据进行压缩的比较厉害
实际工作当中,很多时候,列式存储的数据格式都是选择orc或者parquet 压缩方式都是选择snappy。
七、hive的数据存储格式
Hive支持的存储数的格式主要有:TEXTFILE(行式存储) 、SEQUENCEFILE(行式存储)、ORC(列式存储)、PARQUET(列式存储)。
7.1 列式存储和行式存储
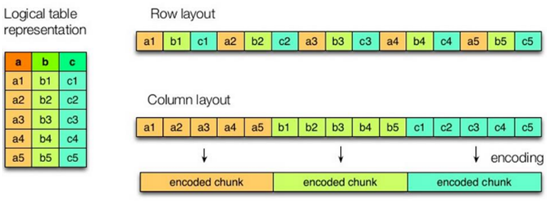
上图左边为逻辑表,右边第一个为行式存储,第二个为列式存储。
行存储的特点: 查询满足条件的一整行数据的时候,列存储则需要去每个聚集的字段找到对应的每个列的值,行存储只需要找到其中一个值,其余的值都在相邻地方,所以此时行存储查询的速度更快。
列存储的特点: 因为每个字段的数据聚集存储,在查询只需要少数几个字段的时候,能大大减少读取的数据量;每个字段的数据类型一定是相同的,列式存储可以针对性的设计更好的设计压缩算法。
TEXTFILE和SEQUENCEFILE的存储格式都是基于行存储的;
ORC和PARQUET是基于列式存储的。
7.2 TEXTFILE格式
默认格式,数据不做压缩,磁盘开销大,数据解析开销大。可结合Gzip、Bzip2使用(系统自动检查,执行查询时自动解压),但使用这种方式,hive不会对数据进行切分,从而无法对数据进行并行操作。
7.3 ORC格式
Orc (Optimized Row Columnar)是hive 0.11版里引入的新的存储格式。
可以看到每个Orc文件由1个或多个stripe组成,每个stripe250MB大小,这个Stripe实际相当于RowGroup概念,不过大小由4MB->250MB,这样能提升顺序读的吞吐率。每个Stripe里有三部分组成,分别是Index Data,Row Data,Stripe Footer:
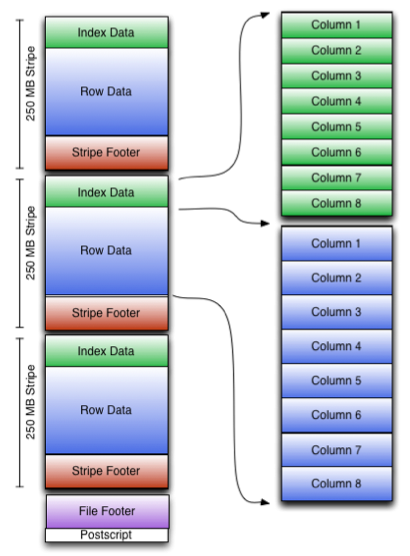
一个orc文件可以分为若干个Stripe
一个stripe可以分为三个部分
indexData:某些列的索引数据
rowData :真正的数据存储
StripFooter:stripe的元数据信息
1)Index Data:一个轻量级的index,默认是每隔1W行做一个索引。这里做的索引只是记录某行的各字段在Row Data中的offset。
2)Row Data:存的是具体的数据,先取部分行,然后对这些行按列进行存储。对每个列进行了编码,分成多个Stream来存储。
3)Stripe Footer:存的是各个stripe的元数据信息
每个文件有一个File Footer,这里面存的是每个Stripe的行数,每个Column的数据类型信息等;每个文件的尾部是一个PostScript,这里面记录了整个文件的压缩类型以及FileFooter的长度信息等。在读取文件时,会seek到文件尾部读PostScript,从里面解析到File Footer长度,再读FileFooter,从里面解析到各个Stripe信息,再读各个Stripe,即从后往前读。
7.4 PARQUET格式
Parquet是面向分析型业务的列式存储格式,由Twitter和Cloudera合作开发,2015年5月从Apache的孵化器里毕业成为Apache顶级项目。
Parquet文件是以二进制方式存储的,所以是不可以直接读取的,文件中包括该文件的数据和元数据,因此Parquet格式文件是自解析的。
通常情况下,在存储Parquet数据的时候会按照Block大小设置行组的大小,由于一般情况下每一个Mapper任务处理数据的最小单位是一个Block,这样可以把每一个行组由一个Mapper任务处理,增大任务执行并行度。Parquet文件的格式如下图所示。
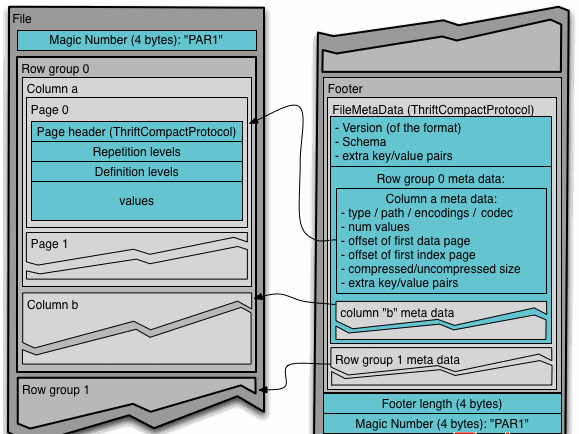
上图展示了一个Parquet文件的内容,一个文件中可以存储多个行组,文件的首位都是该文件的Magic Code,用于校验它是否是一个Parquet文件,Footer length记录了文件元数据的大小,通过该值和文件长度可以计算出元数据的偏移量,文件的元数据中包括每一个行组的元数据信息和该文件存储数据的Schema信息。除了文件中每一个行组的元数据,每一页的开始都会存储该页的元数据,在Parquet中,有三种类型的页:数据页、字典页和索引页。数据页用于存储当前行组中该列的值,字典页存储该列值的编码字典,每一个列块中最多包含一个字典页,索引页用来存储当前行组下该列的索引,目前Parquet中还不支持索引页。
第3节 hive高级用法:15、hive的数据存储格式介绍的更多相关文章
- 第3节 hive高级用法:16、17、18
第3节 hive高级用法:16.hive当中常用的几种数据存储格式对比:17.存储方式与压缩格式相结合:18.总结 hive当中的数据存储格式: 行式存储:textFile sequenceFile ...
- 第3节 hive高级用法:13、hive的函数
4.2.Hive参数配置方式 Hive参数大全: https://cwiki.apache.org/confluence/display/Hive/Configuration+Properties 开 ...
- 第3节 hive高级用法:14、hive的数据压缩
六.hive的数据压缩 在实际工作当中,hive当中处理的数据,一般都需要经过压缩,前期我们在学习hadoop的时候,已经配置过hadoop的压缩,我们这里的hive也是一样的可以使用压缩来节省我们的 ...
- Web Scraper 高级用法——使用 CouchDB 存储数据 | 简易数据分析 18
这是简易数据分析系列的第 18 篇文章. 利用 web scraper 抓取数据的时候,大家一定会遇到一个问题:数据是乱序的.在之前的教程里,我建议大家利用 Excel 等工具对数据二次加工排序,但还 ...
- Newtonsoft.Json高级用法(转)
手机端应用讲究速度快,体验好.刚好手头上的一个项目服务端接口有性能问题,需要进行优化.在接口多次修改中,实体添加了很多字段用于中间计算或者存储,然后最终用Newtonsoft.Json进行序列化返回数 ...
- 【转】 Newtonsoft.Json高级用法
手机端应用讲究速度快,体验好.刚好手头上的一个项目服务端接口有性能问题,需要进行优化.在接口多次修改中,实体添加了很多字段用于中间计算或者存储,然后最终用Newtonsoft.Json进行序列化返回数 ...
- Newtonsoft.Json高级用法 1.忽略某些属性 2.默认值的处理 3.空值的处理 4.支持非公共成员 5.日期处理 6.自定义序列化的字段名称
手机端应用讲究速度快,体验好.刚好手头上的一个项目服务端接口有性能问题,需要进行优化.在接口多次修改中,实体添加了很多字段用于中间计算或者存储,然后最终用Newtonsoft.Json进行序列化返回数 ...
- 转:Newtonsoft.Json高级用法
原文地址:http://www.cnblogs.com/yanweidie/p/4605212.html 手机端应用讲究速度快,体验好.刚好手头上的一个项目服务端接口有性能问题,需要进行优化.在接口多 ...
- Newtonsoft.Json高级用法,json序列号,model反序列化,支持序列化和反序列化DataTable,DataSet,Entity Framework和Entity,字符串
原文地址:https://www.cnblogs.com/yanweidie/p/4605212.html 手机端应用讲究速度快,体验好.刚好手头上的一个项目服务端接口有性能问题,需要进行优化.在接口 ...
随机推荐
- bzoj3995
线段树 额 计蒜客竟然把这个出成noip模拟题... 这个东西很像1018,只不过维护的东西不太一样 然后我参考了fuxey大神的代码,盗一波图 具体有这五种情况,合并请看代码,自己写了一个结果wa了 ...
- ChartCtrl源码剖析之——CChartAxisLabel类
CChartAxisLabel类用来绘制轴标签,上.下.左.右都可以根据实际需要设置对应的轴标签.它处于该控件的区域,如下图所示: CChartAxisLabel类的头文件. #if !defined ...
- Maven的-pl -am -amd参数学习
昨天maven的deploy任务需要只选择单个模块并且把它依赖的模块一起打包,第一时间便想到了-pl参数,然后就开始处理,但是因为之前只看了一下命令的介绍,竟然花了近半小时才完全跑通,故记录此文. 假 ...
- Sleep示例分析
sleep让"当前线程"由“运行状态”进入到“休眠(阻塞)状态”,sleep结束,线程重新被唤醒时,它会由“阻塞状态”变成“就绪状态”,从而等待cpu的调度执行. 示例分析: pu ...
- 洛谷P3211 [HNOI2011]XOR和路径(期望dp+高斯消元)
传送门 高斯消元还是一如既往的难打……板子都背不来……Kelin大佬太强啦 不知道大佬们是怎么发现可以按位考虑贡献,求出每一位是$1$的概率 然后设$f[u]$表示$u->n$的路径上这一位为$ ...
- 洛谷P2572 [SCOI2010]序列操作(珂朵莉树)
传送门 珂朵莉树是个吼东西啊 这题线段树代码4k起步……珂朵莉树只要2k…… 虽然因为这题数据不随机所以珂朵莉树的复杂度实际上是错的…… 然而能过就行对不对…… (不过要是到时候noip我还真不敢打… ...
- 标准字符cp功能
#include<stdio.h> #include<fcntl.h> int main(int argc,char *argv[]) { FILE *src_fp,*des_ ...
- TRACE Method 网站漏洞,你关闭了吗[转]
危险:该漏洞可能篡改网页HTML 源码 最近采用360 web scan 对服务器进行扫描.发现漏洞.TRACE Method Enabled 安全打分98分.前一阵有网页JS被人篡改,可能就是从这个 ...
- Dexposed:android免Root无侵入Aop框架
在网上看到了阿里推出的一个android开源项目,名为Dexposed, 是一个Android平台下的无侵入运行期AOP框架.旨在解决像性能监控.在线热补丁等移动开发常见难题,典型使用场景为: AOP ...
- 51Nod 1315 合法整数集
1315 合法整数集 题目来源: TopCoder 基准时间限制:1 秒 空间限制:131072 KB 分值: 10 难度:2级算法题 收藏 关注 一个整数集合S是合法的,指S的任意子集subS有Fu ...