什么是spark(六)Spark中的对象
Spark中的对象
Spark的Conf,极简化的场景,可以设置一个空conf给sparkContext,在执行spark-submit的时候,系统会默认给sparkContext赋一个SparkConf;
Application是顶级的,每个spark-submit就是一个application;官网说明:User program built on Spark. Consists of a driver program and executors on the cluster.
每个action(函数)是一个job,action是两个job的分界点;官网说明:A parallel computation consisting of multiple tasks that gets spawned in response to a Spark action (e.g. save, collect); you'll see this term used in the driver's logs.
job是由stage组成,stage其实是和transformation对应;Stage的划分是是否产生了shuffle(shuffle就是一次跨节点IO,详细介绍看“分区”),一个shuffle两个stage的分界点。所以stage是一个说明描述,说明了要处理什么数据;stage其实是一个或者多个链式 transformation组成;每个transformation在执行的时候,将会下放到每个分区中,每个分区创建一个task,这个task将会通过本地的executor(一个worker部署在一台机器,一个worker有一个executor,每个worker下面管理多个partition;官网说明:Each job gets divided into smaller sets of tasks called stages that depend on each other (similar to the map and reduce stages in MapReduce); you'll see this term used in the driver's logs.
Job和stage都是全局概念,task是一个局部概念,他的产生是为了执行stage,因为数据是分布在每个分区里面,所以在执行stage,需要读取分区数据并进行处理的时候(执行map,执行filter),task产生了:数据处理就是由task通过Executor跑出来的;官网说明:A unit of work that will be sent to one executor
 从sc.textFile到action调用,整个过程都是一个DAG下来,下放到所有的worker节点,然后图中所有的transformation都会被倒叙执行;注意textFile执行其实是spark读取当前节点的的文件,无论是常规文件系统还是Hdfs,都只是workernode自己的数据,所以transformation也是当前节点的数据;这个也是为什么建议worker节点和datanode节点一致的原因;为什么会shuffle?就是因为本地的数据都是局部的,需要将局部数据进行汇总处理,一汇总,就发生了shuffle。
从sc.textFile到action调用,整个过程都是一个DAG下来,下放到所有的worker节点,然后图中所有的transformation都会被倒叙执行;注意textFile执行其实是spark读取当前节点的的文件,无论是常规文件系统还是Hdfs,都只是workernode自己的数据,所以transformation也是当前节点的数据;这个也是为什么建议worker节点和datanode节点一致的原因;为什么会shuffle?就是因为本地的数据都是局部的,需要将局部数据进行汇总处理,一汇总,就发生了shuffle。
这里还有一个点,就是sc.txtFile之后如果还有partitionBy的话,将会导致数据重排。
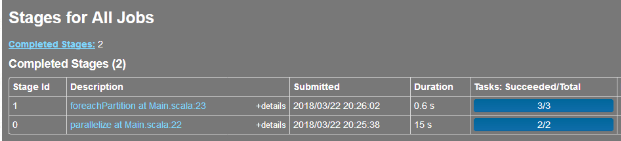
对于job下面的每个stage,并不是一次性把DAG下放到各个分区;而是分批提交给YARN的;因为stage的划分点是shuffle,所以stage是有顺序的;这一点可以通过spark的历史服务页面中的Stages可以看到,每个 stage的提交时间是不一样;这个解释了为什么有的stage是2个task,有的是3个task。第一个stage是执行获取数据,不需要所有的分区参与;第二个stage是foreachpartition,所有的分区都需要参与,所以task数量和分区数一致(3个)
关键性能调优
1. 并行数,本质就是设置分区数,每个分区将会对应一个线程在跑,无论是partitionBy,repatition还是在reduceBy等action函数中指定分区数,亦或是在sparkConf中指定spark.sql.shuffle.partitions,都是可以通过改变分区数来实现并行;强调一点,是该改变,而不是增多;因为并不是分区越多性能越大,关键是利用率;很多时候经过filter之后数据量变小了,分区数减少了反而会提升性能。不用担心分区减少后数据重组导致的损害;在由多变少的场景下,系统开销其实很小的。
2. 序列化,通过:
sparkConf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
来实现传输过程中对于数据进行序列化传输;KryoSerializer现在已经是spark的标配了(比spark/java原生的序列压缩比率更高,效率更高。
3. 内存管理:
1)RDD的存储,通过persis、cache进行内存存储;可以通过设置memory,disk以及serilize组合来实现减少对内存实现;spark.storage.memoryFraction
2)shuffle and aggregation缓冲区,主要用存放shuffle以及aggregation的临时数据;可以通过调整spark.shuffle.memoryFraction来调整占用内存比例;
3)用户代码
默认60%的JVM堆栈分给RDD,缓冲区和用户代码各占20%;可以根据场景需要来调整分配比例;
对于RDD存储的优化可以通过memory+disk+serial组合来对减少内存的使用;序列化(serialize,将多个对象进行合并)可以有效减少GC的次数,因为JVM在回收的时候看的是堆栈对象的数量,而不是大小;缺点是因为存在序列化和反序列化,损失一些性能。
4. 硬件
1)增加内存,执行的时候通过增加--executor-memory以及--executor-cores来提升性能;但是不能超过64G,否则GC的回收会导致长时间停机;
2)增加硬盘,配置spark的存储路径分散在各个硬盘上面呢,这样可以实现多个硬盘并发读取硬盘数据供应用处理,提升吞吐率;
spark官网介绍调优:http://spark.apache.org/docs/latest/tuning.html#data-locality
什么是spark(六)Spark中的对象的更多相关文章
- 【转载】Spark学习——spark中的几个概念的理解及参数配置
首先是一张Spark的部署图: 节点类型有: 1. master 节点: 常驻master进程,负责管理全部worker节点.2. worker 节点: 常驻worker进程,负责管理executor ...
- 大数据技术之_27_电商平台数据分析项目_02_预备知识 + Scala + Spark Core + Spark SQL + Spark Streaming + Java 对象池
第0章 预备知识0.1 Scala0.1.1 Scala 操作符0.1.2 拉链操作0.2 Spark Core0.2.1 Spark RDD 持久化0.2.2 Spark 共享变量0.3 Spark ...
- spark 源码分析之十六 -- Spark内存存储剖析
上篇spark 源码分析之十五 -- Spark内存管理剖析 讲解了Spark的内存管理机制,主要是MemoryManager的内容.跟Spark的内存管理机制最密切相关的就是内存存储,本篇文章主要介 ...
- Spark读取HDFS中的Zip文件
1. 任务背景 近日有个项目任务,要求读取压缩在Zip中的百科HTML文件,经分析发现,提供的Zip文件有如下特点(=>指代对应解决方案): (1) 压缩为分卷文件 => 只需将解压缩在同 ...
- 如果Apache Spark集群中没有分布式系统,则会?
若当连接到Spark的master之后,若集群中没有分布式文件系统,Spark会在集群中每一台机器上加载数据,所以要确保Spark集群中每个节点上都有完整数据. 通常可以选择把数据放到HDFS.S3或 ...
- Spark(Hive) SQL中UDF的使用(Python)
相对于使用MapReduce或者Spark Application的方式进行数据分析,使用Hive SQL或Spark SQL能为我们省去不少的代码工作量,而Hive SQL或Spark SQL本身内 ...
- SPARK在linux中的部署,以及SPARK中聚类算法的使用
眼下,SPARK在大数据处理领域十分流行.尤其是对于大规模数据集上的机器学习算法.SPARK更具有优势.一下初步介绍SPARK在linux中的部署与使用,以及当中聚类算法的实现. 在官网http:// ...
- spark在idea中本地如何运行?(处理问题NoSuchFieldException: SHUTDOWN_HOOK_PRIORITY)
spark在idea中本地如何运行? 前几天尝试使用idea在本地运行spark+scala的程序,出现了问题,http://www.cnblogs.com/yjf512/p/7662105.html ...
- [Spark][Python]DataFrame中取出有限个记录的例子
[Spark][Python]DataFrame中取出有限个记录的例子: sqlContext = HiveContext(sc) peopleDF = sqlContext.read.json(&q ...
随机推荐
- flask学习(五):使用配置文件
1. 新建一个config.py文件 2. 在主app文件中导入这个文件,并且配置到app中,示例代码如下: import config app.config.from_object(config) ...
- Java 里的异常(Exception)详解
作为一位初学者, 本屌也没有能力对异常谈得很深入. 只不过Java里关于Exception的东西实在是很多. 所以这篇文章很长就是了.. 一, 什么是java里的异常 由于java是c\c++ ...
- 二十三 Python分布式爬虫打造搜索引擎Scrapy精讲—craw母版l创建自动爬虫文件—以及 scrapy item loader机制
用命令创建自动爬虫文件 创建爬虫文件是根据scrapy的母版来创建爬虫文件的 scrapy genspider -l 查看scrapy创建爬虫文件可用的母版 Available templates: ...
- Nginx禁止域名恶意解析
今天打开网站发现访客人数突增啊,不对啊,小站哪来这么多的访问量呢?打开百度统计,看到有其他的域名解析到我的IP,心中很不爽啊.遂搜索之,才有了此篇文章. 打开Nginx配置文件/etc/nginx/s ...
- ['1','2','3'].map(parseInt) 返回的是什么?
返回的是:[1,NaN,NaN] 首先我们先分析一下 parseInt 函数: parseInt()函数解析一个字符串参数,并返回指定基数的整数(数学系统中的基数). 它可以有两个参数,用法:pa ...
- Linux:split命令详解
split 可以将一个大文件分割成很多个小文件,有时需要将文件分割成更小的片段,比如为提高可读性,生成日志 语法 split(选项)(file)PREFIX 选项 -b:值为每一输出档案的大小,单位为 ...
- (转) MapReduce Design Patterns(chapter 2 (part 1))(二)
CHAPTER 2 .Summarization Patterns 随着每天都有更多的数据加载进系统,数据量变得很庞大.这一章专注于对你的数据顶层的,概括性意见的设计模式,从而使你能扩展思路,但可能 ...
- React之状态(state)与生命周期
很多时候,我们的页面数据是动态的.所以,我们需要实时渲染页面: 一.用定时函数setInterval() 组件(输出当前时间): index.js: 这样每隔1秒页面就会重新渲染一次,这样传进去的时间 ...
- [Python] dict字典的浅复制与深复制
Python中针对dict字典有两种复制: (1)浅复制:利用 copy() 或者 dict() :复制后对原dict的内部子对象(方括号[]内元素)进行操作时,由浅复制得到的dict会受该操作影响 ...
- BDD测试框架Spock概要
前言 为了找到一个适合自己的.更具操作性的.以DDD为核心的开发方法,我最近一直在摸索如何揉合BDD与DDD.围绕这个目标,我找到了Impact Mapping → Cucumber → Spock ...