第九篇:使用 AdaBoost 元算法提高分类器性能
前言
有人认为 AdaBoost 是最好的监督学习的方式。
某种程度上因为它是元算法,也就是说它会是几种分类器的组合。这就好比对于一个问题能够咨询多个 "专家" 的意见了。
组合的方式有多种,可能是不同分类算法的分类器,可能是同一算法在不同设置下的集成,还可以是数据集在不同部分分配给不同分类器之后的集成等等。
本文将给出的 AdaBoost 分类器实现基于第二种 (另外几种实现在此基础上稍作改动即可)。
一种原始的元算法 - bagging (自举汇聚法)
这个算法的意思有点像投票系统,其思路步骤大致如下:
1. 将数据按照一定的规则划分成 N 份,每份的大小和原数据集一样大 (因此里面肯定是有重复数据的)。
2. 将这 N 份数据集分发到多个分类器中。
3. 按照 "少数服从多数" 原则,从这 N 个分类器的分类结果中总结出最优结果。
boost (提高任意给定学习算法精确度算法) vs bagging (自举汇聚法)
boost 和 bagging 一个很大的不同是它会给那些分错的样本更高关注度(权重)。AdaBoost 是一种最为典型的 boost 元算法。
因此理论上它能在相对较少的迭代次数下得到更为精确的分类结果。
AdaBoost 元算法的基本原理
AdaBoost 的强大之处,在于它能够集成多个弱分类器,形成一个强分类器。
所谓弱分类器就是分类错误率大于五成的分类器,比随机分类还渣。(但是它的分类算法是确定的,这点和随机分类器不同。显然你无法通过集成随机分类器得到什么有价值的东西)
其具体步骤大致如下:
1. 对每个样本给定一个权重 d。
2. 基于权重向量 D 调用一次弱分类器并得出这次统计的分类器权重值 alpha (注意是分类器权重值,区别于上一步的权重d)
3. 基于分类器权重值 alpha 更新各个样本的权重向量
4. 循环 2 - 3 直到错误率为 0 或者循环到了指定的次数
5. 1-4 为训练部分算法,训练好了之后,便可带入样本进行分类。分类的方法是依次带入训练集中的各个分类器中求出分类结果,然后各部分结果乘以其对应的分类器权重值 alpha 再累加求和。
下图可用来帮助理解 (直方图中的矩形长度表示样本权重,三角形中的值表示分类器权重值 alpha):
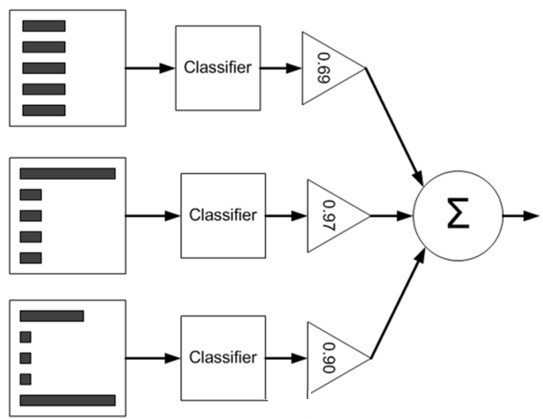
基于单层决策树的 AdaBoost 元算法分类器实现
首先,准备好单层决策树的数据结构。
在本文的 AdaBoost 实现中,元算法中的分类器组合模式是 "同一算法在不同设置下的集成",那么不同设置不同在哪里?
不同就不同在每次构建单层决策树都是选择划分正确率最高的划分方式。
因此在构建单层决策树函数中,必须有一个择优过程,具体可以参考下面的实现代码。
函数的功能应当是返回一个单层决策树信息结构(仅仅是划分信息就可以了不用数据)。
同时,函数应该返回一个错误信息值,这个错误值是和权重向量D相关的,用于计算分类器权重值 alpha。(当然也可以在该函数内部实现该字段)
最后,分类结果自然也要返回。
单层决策树代码实现如下:
#==========================================
# 输入:
# dataMatrix: 输入数据
# dimen: 划分特征下标
# threshVal: 划分阈值
# threshIneq: 划分方向(是左1右0分类还是左0右1分类)
# 输出:
# retArray: 分类结果
#==========================================
def stumpClassify(dataMatrix,dimen,threshVal,threshIneq):
'按照指定方式分类并返回结果' retArray = numpy.ones((numpy.shape(dataMatrix)[0],1))
if threshIneq == 'lt':
retArray[dataMatrix[:,dimen] <= threshVal] = -1.0
else:
retArray[dataMatrix[:,dimen] > threshVal] = -1.0 return retArray #==========================================
# 输入:
# dataArr: 输入数据
# classLabels: 分类标签集
# D: 权重向量
# 输出:
# bestStump: 决策树信息
# minError: 带权错误(用于生成分类器权重值 alpha)
# bestClasEst: 分类结果
#==========================================
def buildStump(dataArr,classLabels,D):
'创建单层最佳决策树' dataMatrix = numpy.mat(dataArr);
labelMat = numpy.mat(classLabels).T
m,n = numpy.shape(dataMatrix) # 特征值阈值步长
numSteps = 10.0;
# 当前最佳决策树信息集
bestStump = {};
# 分类结果
bestClasEst = numpy.mat(numpy.zeros((m,1)))
# 最小带权错误初始化为无穷大
minError = numpy.inf for i in range(n): # 遍历所有的特征选取最佳划分特征
rangeMin = dataMatrix[:,i].min();
rangeMax = dataMatrix[:,i].max();
stepSize = (rangeMax-rangeMin)/numSteps for j in range(-1,int(numSteps)+1): # 遍历所有的特征值选取最佳划分特征值 stepSize为探测步长 for inequal in ['lt', 'gt']: # 对于 左1右0 和 左0右1 两种分类方式 # 当前划分阈值
threshVal = (rangeMin + float(j) * stepSize)
# 分类
predictedVals = stumpClassify(dataMatrix,i,threshVal,inequal)
# 统计分类错误信息
errArr = numpy.mat(numpy.ones((m,1)))
errArr[predictedVals == labelMat] = 0
weightedError = D.T*errArr # 更新最佳决策树的信息
if weightedError < minError:
minError = weightedError
bestClasEst = predictedVals.copy()
bestStump['dim'] = i
bestStump['thresh'] = threshVal
bestStump['ineq'] = inequal return bestStump,minError,bestClasEst
在单层决策树之上,便是 AdaBoost 分类器的实现,下面先给出伪代码:
对每次迭代:
找到最佳单层决策树
将该树加入到最佳决策树数组
计算分类器权重 alpha
更新权重向量 D
更新累计类别估计值
PS: 如果错误率等于0.,则立马退出循环。
Python 代码实现如下:
#==========================================
# 输入:
# dataArr: 输入数据
# classLabels: 分类标签集
# numIt: 最大迭代次数
# 输出:
# bestStump: 决策树信息
# minError: 带权错误(用于生成分类器权重值 alpha)
# bestClasEst: 分类结果
#==========================================
def adaBoostTrainDS(dataArr,classLabels,numIt=40):
'AdaBoost 分类器' # 最佳决策树集合
weakClassArr = []
# 样本个数
m = numpy.shape(dataArr)[0]
# 权重向量
D = numpy.mat(numpy.ones((m,1))/m)
# 各个类别的估计累积值
aggClassEst = numpy.mat(numpy.zeros((m,1))) for i in range(numIt): # 迭代 numIt 次
# 构建最佳决策树
bestStump,error,classEst = buildStump(dataArr,classLabels,D)
# 计算该决策树的分类器权重值 alpha
alpha = float(0.5*numpy.log((1.0-error)/max(error,1e-16)))
bestStump['alpha'] = alpha
# 将该决策树加入到决策树数组中去
weakClassArr.append(bestStump) # 更新权重向量
expon = numpy.multiply(-1*alpha*numpy.mat(classLabels).T,classEst)
D = numpy.multiply(D,numpy.exp(expon))
D = D/D.sum() # 计算当前的总错误率。如果错误率为0则退出循环。
aggClassEst += alpha*classEst
aggErrors = numpy.multiply(numpy.sign(aggClassEst) != numpy.mat(classLabels).T,numpy.ones((m,1)))
errorRate = aggErrors.sum()/m
print "错误率: ",errorRate
if errorRate == 0.0: break return weakClassArr
至此,就可以用 AdaBoost 进行分类了。
首先训练出一个训练集,然后将训练集带入分类函数,如下:
# 获取训练集
classifierArr = adaBoostTrainDS(daaArr, labelArr, 30)
# 分类并打印结果
print adaClassify([0,0], classifierArr)
测试结果:

显然,可以看出 AdaBoost 分类器由三个决策树构成。样本最终分类结果为 -1。
小结
本文介绍了分类器中的元算法思想。通过这样的思想,能够将多种分类器组合起来,大大地加强了分类性能。
另外据可靠数据分析,较之逻辑回归,AdaBoost 分类器没有过度拟合(overfitting)现象。
Boost算法还有很多种,AdaBoost 只是其中最为经典的实现之一,还有更多高级实习需要在日后学习工作中进行研究。
第九篇:使用 AdaBoost 元算法提高分类器性能的更多相关文章
- 使用 AdaBoost 元算法提高分类器性能
前言 有人认为 AdaBoost 是最好的监督学习的方式. 某种程度上因为它是元算法,也就是说它会是几种分类器的组合.这就好比对于一个问题能够咨询多个 "专家" 的意见了. 组合的 ...
- 机器学习实战 - 读书笔记(07) - 利用AdaBoost元算法提高分类性能
前言 最近在看Peter Harrington写的"机器学习实战",这是我的学习笔记,这次是第7章 - 利用AdaBoost元算法提高分类性能. 核心思想 在使用某个特定的算法是, ...
- 【转载】 机器学习实战 - 读书笔记(07) - 利用AdaBoost元算法提高分类性能
原文地址: https://www.cnblogs.com/steven-yang/p/5686473.html ------------------------------------------- ...
- 《机器学习实战第7章:利用AdaBoost元算法提高分类性能》
import numpy as np import matplotlib.pyplot as plt def loadSimpData(): dataMat = np.matrix([[1., 2.1 ...
- 利用AdaBoost元算法提高分类性能
当做重要决定时,大家可能都会吸取多个专家而不只是一个人的意见.机器学习处理问题时又何尝不是如此?这就是元算法背后的思路.元算法是对其他算法进行组合的一种方式. 自举汇聚法(bootstrap aggr ...
- 监督学习——AdaBoost元算法提高分类性能
基于数据的多重抽样的分类器 可以将不通的分类器组合起来,这种组合结果被称为集成方法(ensemble method)或者元算法(meta-algorithom) bagging : 基于数据随机抽样的 ...
- 第七章:利用AdaBoost元算法提高分类性能
本章内容□ 组合相似的分类器来提髙分类性能□应用AdaBoost算法□ 处理非均衡分类问题
- 机器学习技法-AdaBoost元算法
课程地址:https://class.coursera.org/ntumltwo-002/lecture 重要!重要!重要~ 一.Adaptive Boosting 的动机 通过组合多个弱分类器(hy ...
- 在Titanic数据集上应用AdaBoost元算法
一.AdaBoost 元算法的基本原理 AdaBoost是adaptive boosting的缩写,就是自适应boosting.元算法是对于其他算法进行组合的一种方式. 而boosting是在从原始数 ...
随机推荐
- ubuntu建立软ap共享无线网络
建立ad-hoc模式共享网络 viewtopic.php?f=116&t=387194 有些android手机可能不支持ad-hoc模式,要第三方rom才行. 首先安装这些工具 代码: apt ...
- LaTeX 中文段首空格问题
一般用 “\\”或者回车可以使得下一段段首空两格,但是对于第一段就不行了. 解决办法: 加一个\usepackage{indentfirst}就可以
- unity, destroy gameObject & destroy all children
一,destroy gameObject 删除名为xxx的gameObject 错误方法1: Destroy(xxx); 以上方法之所以错误,是因为Destroy在下一帧才生效,而在本帧之内xxx还存 ...
- Murano环境搭建、使用介绍和思考
murano是OpenStack的Application Catalog服务.推崇AaaS(Anything-as-a-Service)的概念.通过统一的框架和API实现应用程序高速部署和应用程序 ...
- 【转】Appium_API(翻译+用法说明)
转自:https://testerhome.com/topics/3711 1.contextscontexts(self): Returns the contexts within the curr ...
- Python 列表的操作
list基本操作 #coding=utf-8 #列表 string = 'list' #字符串->列表 list1 = list(string) # ['l', 'i', 's', 't'] # ...
- ldap temp
#http://www.openldap.org/software/man.cgi?query=slapcat&apropos=0&sektion=0&manpath=Open ...
- SQLite的连接字符串
SQLite的连接字符串 Basic(基本的) Data Source=filename;Version=3;Using UTF16(使用UTF16编码) Data Source=fil ...
- 最新PHPcms9.6.0 任意文件上传漏洞
在用户注册处抓包: 然后发送到repeater POC: siteid=&modelid=&username=z1aaaac121&password=aasaewee311as ...
- 5分钟用Spring4 搭建一个REST WebService(转)
章节目录 前置技能 新建项目,配置依赖文件 编写Model和Controller 启动服务&访问 但是 其他 前置技能 ① 使用maven来管理java项目 这个技能必须点一级,以便快速配置项 ...