模型的性能评估(二) 用sklearn进行模型评估
在sklearn当中,可以在三个地方进行模型的评估
1:各个模型的均有提供的score方法来进行评估。 这种方法对于每一种学习器来说都是根据学习器本身的特点定制的,不可改变,这种方法比较简单。这种方法受模型的影响,
2:用交叉验证cross_val_score,或者参数调试GridSearchCV,它们都依赖scoring参数传入一个性能度量函数。这种方法就是我们下面讨论的使用scoring进行模型的性能评估。
3:Metric方法,Metric有为各种问题提供的评估方法。这些问题包括分类、聚类、回归等。这是我们下面的使用metrics进行模型评估。
总之,在进行模型评估的时候,我们总是使用上面的三种方法。第一种方法由于比较固定,而且容易使用,所以这里并不介绍。下面介绍第二种方法和第三种。
使用scoring进行模型的性能评估
在进行模型选择和评估的时候我们要使用一些策略,这些策略帮助我们更好的进行模型评估,在使用这些策略的时候需要传入一个scoring参数。比如上面的cross_val_score(使用sklearn进行交叉验证中有介绍)是用交叉验证的方法来对模型评分。 还有GridSearchCV和RandomizedSearchCV是用来进行参数选择的,也需要传入一个scoring参数,这个参数决定了我们使用什么样的方法来进行评分。当需要传入scoring参数的时候,我们可以有以下几种做法:
直接指定评分函数的名称来进行评分
评分函数的选择是很多的,如我们熟知的f1, recall ,precision等。在用scoring进行模型性能评估的时候直接指定这些就可以完成评分任务。
输出结果如下:
from sklearn import svm, datasets
from sklearn.model_selection import cross_val_score
iris = datasets.load_iris() X, y = iris.data, iris.target
clf = svm.SVC(probability=True, random_state=0)
#这里传入的为neg_log_loss
# 观察y值,可以发现y有三个取值的范围,也就是说这是一个多分类问题,所以当scoring选precision,f1值的时候是不#可以的。 但是可以传入它们对于多分类问题的变形 如f1_micro, precison_macro等,更多详见官网
print(cross_val_score(clf, X, y, scoring='neg_log_loss')) model = svm.SVC()
#一旦模型传入一个错误的评分函数,会报错,并且系统会提示出哪些正确的评分函数可以选择
cross_val_score(model, X, y, scoring='wrong_choice')
[-0.0757138 -0.16816241 -0.07091847]、 ValueError: 'wrong_choice' is not a valid scoring value. Valid options are ['accuracy', 'adjusted_mutual_info_score', 'adjusted_rand_score', 'average_precision', 'completeness_score', 'explained_variance', 'f1', 'f1_macro', 'f1_micro', 'f1_samples', 'f1_weighted', 'fowlkes_mallows_score', 'homogeneity_score', 'mutual_info_score', 'neg_log_loss', 'neg_mean_absolute_error', 'neg_mean_squared_error', 'neg_mean_squared_log_error', 'neg_median_absolute_error', 'normalized_mutual_info_score', 'precision', 'precision_macro', 'precision_micro', 'precision_samples', 'precision_weighted', 'r2', 'recall', 'recall_macro', 'recall_micro', 'recall_samples', 'recall_weighted', 'roc_auc', 'v_measure_score']
使用metric函数来进行评分
sklearn.metrics里面提供了一些函数来帮助我们进行评分。其中里面以_score结尾的函数的返回值越大,模型的性能越好。而以_error或_loss结尾的函数,返回值越小,表示模型性能越好。从命名上来看,这一点不难理解。
metrics里面的很多函数名不直接传入scoring后面,因为有一些函数需要传入特定的参数才能够使用。比如在使用fbeta_score的时候需要传入bata参数等。 在这个时候,我们的做法是把函数名和参数封装一下,封装成为一个新的函数,然后传入scoring后面。封装的方法是使用metrics的make_scorer方法。
下面是一个小例子:
from sklearn.metrics import make_scorer, fbeta_score
#我们用make_scorer封装了fbeta_score,它需要传入一个参数
ftwo_score = make_scorer(fbeta_score, beta=2)
from sklearn.model_selection import GridSearchCV
from sklearn.svm import LinearSVC
grid = GridSearchCV(LinearSVC(), param_grid={'C':[1, 10]}, scoring=ftwo_score)
使用metrics的make_score方法,我们可以制定出我们自己的方法,这个方法需要满足下面一些条件:
- 需要传入一个我们自定义的函数的名称
- 需说明greater_is_better的值是True还是False。 当值为正的时候,返回的是score的值,值越高性能越好。当为False的时候,返回的为score的负值,值越低越好。
- 是否是针对分类问题的。 传入needs_threshold=True来说明是针对分类问题的,默认情况为False。
- 其余的参数。如在f1_score中的bata,labels。
我们来看一段代码:
import numpy as np
from sklearn.metrics import make_scorer def my_custom_loss_func(ground_truth, predictions):
diff = np.abs(ground_truth - predictions).max()
return np.log(1 + diff) loss = make_scorer(my_custom_loss_func, greater_is_better=False)
score = make_scorer(my_custom_loss_func, greater_is_better=True)
ground_truth = [[1], [1]]
predictions = [0, 1]
from sklearn.dummy import DummyClassifier
clf = DummyClassifier(strategy='most_frequent', random_state=0)
clf = clf.fit(ground_truth, predictions)
#这段代码的原理是这样的,我们的clf使用ground_truth 和predictions进行训练
#使用clf.predict(ground_truth) 进行预测以后的结果为[0,0],
#my_custom_loss_func(np.array([0,0], np.array[0,1]) 最后得到log(2) = 0.69314
print(score(clf, ground_truth, predictions))
print(loss(clf, ground_truth, predictions))
输出结果如下:
0.6931471805599453
-0.6931471805599453
我们用make_score封装了我们自己的函数my_custom_loss_func 来进行模型的评分。 score和loss的结果输出相反。
我们还可以实现我们自己的评分对象
为了实现更高的自由度,我们可以不使用上述的make_scorer方法,完全定制出来我们自己的评分对象,这需要遵循两点
- 能够调用(estimater, X, y)参数,estimater是我们的模型,X为数据集, y为X数据集的真实结果。
- 需要返回一个分数作为评分的结果。该分数能够从某个方面反映出我们模型的好坏。
传入多个评分方法
在GridSearchCV, RandomizedSearchCV 和 cross_validate 的scoring参数当中还可以传入多个评分方法,来从不同的角度来进行评分。有两种方法,一种是传入一个列表,另外一个是传入一个字典。
传入列表:
scoring = ['accuracy', 'precision']
传入字典:
from sklearn.metrics import accuracy_score
from sklearn.metrics import make_scorer
scoring = {'accuracy' : make_scorer(accuracy_score), 'prec':'precision'}
传入字典中的方法既可以是一个字符串,也可以是一个封装的方法,这些方法需要返回一个值,返回多个值是是不允许的。
from sklearn.svm import LinearSVC
from sklearn import datasets
from sklearn.metrics import accuracy_score
from sklearn.metrics import make_scorer
from sklearn.metrics import confusion_matrix X, y = datasets.make_classification(n_classes=2, random_state=0)
'''
从混淆矩阵当中定义出tn,fp,fn,tp的值,混淆矩阵的值如下,(官网当中的例子疑似错误):
TN FP
FN TP
'''
def tp(y_true, y_pred): return confusion_matrix(y_true, y_pred)[1, 1]
def tn(y_true, y_pred): return confusion_matrix(y_true, y_pred)[0, 0]
def fp(y_true, y_pred): return confusion_matrix(y_true, y_pred)[0, 1]
def fn(y_true, y_pred): return confusion_matrix(y_true, y_pred)[1, 0]
scoring = {'tp' : make_scorer(tp), 'tn' : make_scorer(tn),
'fp' : make_scorer(fp), 'fn' : make_scorer(fn)} svm = LinearSVC(random_state=0)
from sklearn.model_selection import cross_validate
#我们传入了一个字典来看这个模型的各种评分情况
cv_result = cross_validate(svm.fit( X,y), X, y, scoring=scoring)
print(cv_result['test_tp']) #test后面跟scoring的可以,就可以打得到测试的结果
print(cv_result['test_fp'])
输出结果如下:
[16 14 9]
[5 4 1]
使用metrics进行模型评估
在模型的性能评估 - 理论篇这篇文章中,我们介绍了accuracy、precision、混淆矩阵、F1参数、$F_{\beta}$参数、ROC和AUC,均方误差。下面我们用metrics中的方法来实现一些这些。
Accuracy score
metrics中的accuracy_score方法可以帮助我们计算accuracy(准确率),也就是$\frac{分类正确的样本个数}{所有的样本个数}$。 这个方法对于二分类问题、多分类问题、多标签分类问题都适合。例子如下:
import numpy as np
from sklearn.metrics import accuracy_score y_pred = [0, 2, 1, 3]
y_true = [0, 2, 2, 3]
print(accuracy_score(y_pred, y_true))
结果为: 0.75
Confusion matrix
confusion_matrix是计算出混淆矩阵,矩阵中的第i行,第j列的值为:实际上是第i类,但是却预测为第j类的样本的个数。
from sklearn.metrics import confusion_matrix
y_true = [2, 0, 2, 2, 0, 1]
y_pred = [0, 0, 2, 2, 0, 2]
print(confusion_matrix(y_true, y_pred))
结果如下:
[[2 0 0]
[0 0 1]
[1 0 2]]
对于二分类问题,混淆矩阵变为了
tn,fp
fn, tp
from sklearn.metrics import confusion_matrix
y_true = [0, 0, 0, 1, 1, 1, 1, 1]
y_pred = [0, 1, 0, 1, 0, 1, 0, 1]
tn, fp, fn, tp = confusion_matrix(y_true, y_pred).ravel()
print(tn, fp, fn, tp)
输出结果为 : 2 1 2 3
Precision,Recall 和F-matures
对于二分类问题,我们直接使用metrics里面的方法进行计算
from sklearn import metrics
y_pred = [0, 1, 0, 0]
y_true = [0, 1, 0, 1] print( metrics.precision_score(y_true, y_pred) )
print( metrics.recall_score(y_true, y_pred) )
print( metrics.f1_score(y_true, y_pred) )
print( metrics.fbeta_score(y_true, y_pred, beta=0.5) )
print( metrics.fbeta_score(y_true, y_pred, beta=1) )
print( metrics.fbeta_score(y_true, y_pred, beta=2) )
输出的结果如下:
1.0
0.5
0.6666666666666666
0.8333333333333334
0.6666666666666666
0.5555555555555556
这些函数用起来很简单,名称后面加上_score就可以了。
还有一个方法,precision_recall_fscore_support 直接把precision、recall、fscore和support的值都显示出来,其中support是每个标签在y_true中出现的次数。 这里的标签是y的取值情况,在二分类问题中,标签为0和1两种情况。
print( metrics.precision_recall_fscore_support(y_true, y_pred, beta=0.5) )
输出如下:第一列是0作为标签时候的四个值,第二列是1作为标签时候的四个值。
(array([0.66666667, 1. ]), array([1. , 0.5]), array([0.71428571, 0.83333333]), array([2, 2], dtype=int64))
另外 classification_report 可以打印出来precision、recall、f1-score、support的值
from sklearn.metrics import classification_report
y_true = [0, 1, 2, 2, 0]
y_pred = [0, 0, 2, 1, 0]
target_names = ['class 0', 'class 1', ' class_2']
print(classification_report(y_true, y_pred, target_names=target_names))
结果如下:
precision recall f1-score support
class 0 0.67 1.00 0.80 2
class 1 0.00 0.00 0.00 1
class_2 1.00 0.50 0.67 2
avg / total 0.67 0.60 0.59 5
P-R曲线
可以使用precision_recall_curve来计算出来在不同的阈值下P和R的值,
import numpy as np
from sklearn.metrics import precision_recall_curve
from sklearn.metrics import average_precision_score y_true = np.array([0, 0, 1, 1])
y_scores = np.array([0.1, 0.4, 0.34, 0.8])
precision, recall , threshold = precision_recall_curve(y_true, y_scores)
print(precision)
print(recall)
print(threshold) print(average_precision_score(y_true, y_scores))
输出结果如下:
[0.66666667 0.5 1. 1. ]
[1. 0.5 0.5 0. ]
[0.34 0.4 0.8 ]
0.8333333333333333
当然,可以根据这个结果画出图形,
import matplotlib.pyplot as plt
plt.scatter(recall, precision)
plt.ylim([0, 1.1])
plt.show()
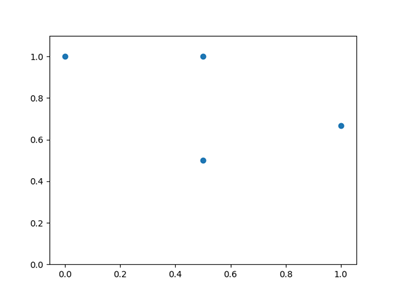
P-R图形
ROC和AUC
受试者工作特征曲线,可以使用roc_curve来实现
import numpy as np
from sklearn.metrics import roc_curve
y = np.array([1, 1, 2, 2])
scores = np.array([0.1, 0.4, 0.35, 0.8])
fpr, tpr, thresholds = roc_curve(y, scores, pos_label=2) print(fpr)
print(tpr)
print(thresholds)
输入结果如下:
[0. 0.5 0.5 1. ]
[0.5 0.5 1. 1. ]
[0.8 0.4 0.35 0.1 ]
同样,也可以画一张图
import matplotlib.pyplot as plt
plt.scatter(fpr, tpr)
plt.ylim([0,1.1])
plt.show()
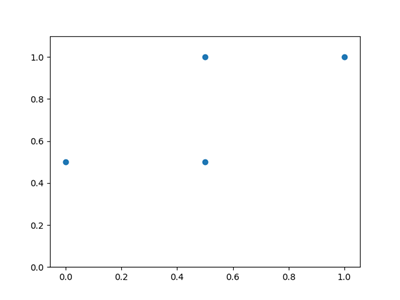
ROC图形
使用roc_auc_score可以计算AUC的值
import numpy as np
from sklearn.metrics import roc_auc_score
y_true = np.array([0, 0, 1, 1])
y_scores = np.array([0.1, 0.4, 0.35, 0.8])
print(roc_auc_score(y_true, y_scores))
计算得到的结果为: 0.75
mean square error
这是评估回归问题所使用的方法:
from sklearn.metrics import mean_squared_error
y_true = [3, -0.5, 2, 7]
y_pred = [2.5, 0.0, 2, 8]
print(mean_squared_error(y_true, y_pred))
结果是0.375
总结
sklearn有三个地方可以实现模型性能度量,我们介绍了两个。一个是交叉验证策略和参数选择策略中的scoring方法,传入我们的方法即可。另外一个是metrics里面的方法,我们需要的方法都可以在这里面找到。
参考:
Model evaluation: quantifying the quality of predictions
模型的性能评估(二) 用sklearn进行模型评估的更多相关文章
- 【分类问题中模型的性能度量(二)】超强整理,超详细解析,一文彻底搞懂ROC、AUC
文章目录 1.背景 2.ROC曲线 2.1 ROC名称溯源(选看) 2.2 ROC曲线的绘制 3.AUC(Area Under ROC Curve) 3.1 AUC来历 3.2 AUC几何意义 3.3 ...
- sklearn中模型评估和预测
一.模型验证方法如下: 通过交叉验证得分:model_sleection.cross_val_score(estimator,X) 对每个输入数据点产生交叉验证估计:model_selection.c ...
- 目标检测模型的性能评估--MAP(Mean Average Precision)
目标检测模型中性能评估的几个重要参数有精确度,精确度和召回率.本文中我们将讨论一个常用的度量指标:均值平均精度,即MAP. 在二元分类中,精确度和召回率是一个简单直观的统计量,但是在目标检测中有所不同 ...
- 【机器学习与R语言】12- 如何评估模型的性能?
目录 1.评估分类方法的性能 1.1 混淆矩阵 1.2 其他评价指标 1)Kappa统计量 2)灵敏度与特异性 3)精确度与回溯精确度 4)F度量 1.3 性能权衡可视化(ROC曲线) 2.评估未来的 ...
- Python 3 利用 Dlib 19.7 和 sklearn机器学习模型 实现人脸微笑检测
0.引言 利用机器学习的方法训练微笑检测模型,给一张人脸照片,判断是否微笑: 使用的数据集中69张没笑脸,65张有笑脸,训练结果识别精度在95%附近: 效果: 图1 示例效果 工程利用pytho ...
- 【机器学习与R语言】13- 如何提高模型的性能?
目录 1.调整模型参数来提高性能 1.1 创建简单的调整模型 2.2 定制调整参数 2.使用元学习来提高性能 2.1 集成学习(元学习)概述 2.2 bagging 2.3 boosting 2.4 ...
- 推广TrustAI可信分析:通过提升数据质量来增强在ERNIE模型下性能
项目链接:https://aistudio.baidu.com/aistudio/projectdetail/4622139?contributionType=1 fork一下,由于内容过多这里就不全 ...
- NS2仿真:公交车移动周期模型及性能分析
NS2仿真实验报告3 实验名称:公交车移动周期模型及性能分析 实验日期:2015年3月16日~2015年3月21日 实验报告日期:2015年3月22日 一.实验环境(网络平台,操作系统,网络拓扑图) ...
- sklearn保存模型-【老鱼学sklearn】
训练好了一个Model 以后总需要保存和再次预测, 所以保存和读取我们的sklearn model也是同样重要的一步. 比如,我们根据房源样本数据训练了一下房价模型,当用户输入自己的房子后,我们就需要 ...
随机推荐
- redis的备份恢复
说明:默认rdb方式保存,redis支持主从和哨兵等,但是在某些情况下我们会单机跑,所以有时候我们就会需要设计到备份恢复 环境:原始redis:192.168.1.200 新redis:192.168 ...
- 002_让你的linux虚拟终端五彩缤纷(1)——LS颜色设置
- HTTP 请求 的方法Util
HTTP请求 的一系列方法总结 /** * *******************************传统请求--开始************************************** ...
- angular项目文件概览
在Mac上打开终端,输入ng new b-app 如下: 然后在webstorm中打开 src文件夹 你的应用代码位于src文件夹中. 所有的Angular组件.模板.样式.图片以及你的应用所需的任 ...
- 详细介绍Linux finger命令的使用
Linux 允许多个用户使用不同的终端同时登陆,Linux finger命令为系统管理员提供知道某个时候到底有多少用户在使用这台Linux主机的方法,对于这个简单的命令我们还是先介绍一下再举例吧. L ...
- 认识hasLayout——IE浏览器css bug的一大罪恶根源 (转)
认识hasLayout--IE浏览器css bug的一大罪恶根源 转 什么是hasLayout?hasLayout是IE特有的一个属性.很多的ie下的css bug都与其息息相关.在ie中,一个元素要 ...
- CircleIndicator
dependencies { compile 'com.nineoldandroids:library:2.4.+' compile 'me.relex:circleindicator:1.0.0@a ...
- Java学习(构造方法、this关键字、super应用)
构 造 方 法 定义:对象创建时使用的方法,即在new一个新对象时,对应构造方法,直接对属性赋值. 语句格式: 修饰符(public 等) 构造方法名(必须跟当前类名一样,否则报错)(参数列表) ...
- Validating a Model
- import xxx from 和 import {xxx} from的区别
1.vue import FunName from ‘../xxx’ 1.js export defualt function FunName() { return fetch({ url: '/ar ...