大数据(13) - Spark的安装部署与简单使用
一 、Spark概述
官网:http://spark.apache.org
1. 什么是spark

Spark是一种快速、通用、可扩展的大数据分析引擎,2009年诞生于加州大学伯克利分校AMPLab,2010年开源,2013年6月成为Apache孵化项目,2014年2月成为Apache顶级项目。项目是用Scala进行编写。
目前,Spark生态系统已经发展成为一个包含多个子项目的集合,其中包含SparkSQL、Spark Streaming、GraphX、MLib、SparkR等子项目,Spark是基于内存计算的大数据并行计算框架。除了扩展了广泛使用的 MapReduce 计算模型,而且高效地支持更多计算模式,包括交互式查询和流处理。Spark 适用于各种各样原先需要多种不同的分布式平台的场景,包括批处理、迭代算法、交互式查询、流处理。通过在一个统一的框架下支持这些不同的计算,Spark 使我们可以简单而低耗地把各种处理流程整合在一起。而这样的组合,在实际的数据分析 过程中是很有意义的。不仅如此,Spark 的这种特性还大大减轻了原先需要对各种平台分 别管理的负担。
大一统的软件栈,各个组件关系密切并且可以相互调用,这种设计有几个好处:1、软件栈中所有的程序库和高级组件 都可以从下层的改进中获益。2、运行整个软件栈的代价变小了。不需要运 行 5 到 10 套独立的软件系统了,一个机构只需要运行一套软件系统即可。系统的部署、维护、测试、支持等大大缩减。3、能够构建出无缝整合不同处理模型的应用。
Spark的内置项目如下:
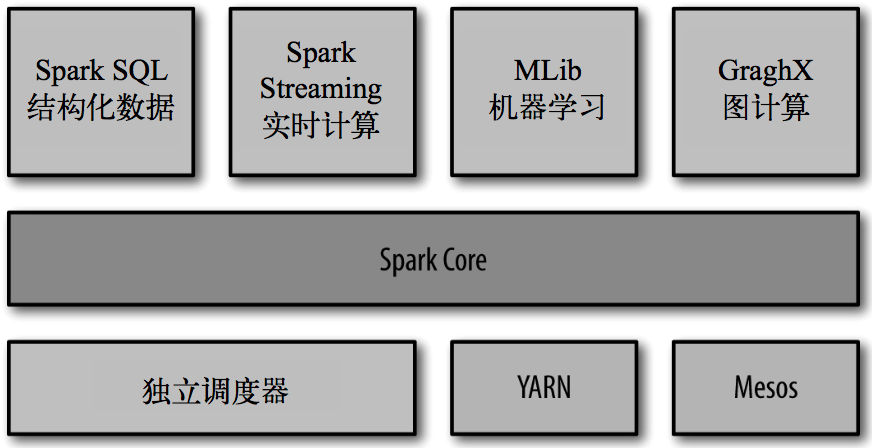
Spark Core:实现了 Spark 的基本功能,包含任务调度、内存管理、错误恢复、与存储系统 交互等模块。Spark Core 中还包含了对弹性分布式数据集(resilient distributed dataset,简称RDD)的 API 定义。
Spark SQL:是 Spark 用来操作结构化数据的程序包。通过 Spark SQL,我们可以使用 SQL 或者 Apache Hive 版本的 SQL 方言(HQL)来查询数据。Spark SQL 支持多种数据源,比 如 Hive 表、Parquet 以及 JSON 等。
Spark Streaming:是 Spark 提供的对实时数据进行流式计算的组件。提供了用来操作数据流的 API,并且与 Spark Core 中的 RDD API 高度对应。
Spark MLlib:提供常见的机器学习(ML)功能的程序库。包括分类、回归、聚类、协同过滤等,还提供了模型评估、数据 导入等额外的支持功能。
集群管理器:Spark 设计为可以高效地在一个计算节点到数千个计算节点之间伸缩计 算。为了实现这样的要求,同时获得最大灵活性,Spark 支持在各种集群管理器(cluster manager)上运行,包括 Hadoop YARN、Apache Mesos,以及 Spark 自带的一个简易调度 器,叫作独立调度器。
Spark得到了众多大数据公司的支持,这些公司包括Hortonworks、IBM、Intel、Cloudera、MapR、Pivotal、百度、阿里、腾讯、京东、携程、优酷土豆。当前百度的Spark已应用于凤巢、大搜索、直达号、百度大数据等业务;阿里利用GraphX构建了大规模的图计算和图挖掘系统,实现了很多生产系统的推荐算法;腾讯Spark集群达到8000台的规模,是当前已知的世界上最大的Spark集群。
2. Spark特点
快:
与Hadoop的MapReduce相比,Spark基于内存的运算要快100倍以上,基于硬盘的运算也要快10倍以上。Spark实现了高效的DAG执行引擎,可以通过基于内存来高效处理数据流。计算的中间结果是存在于内存中的。
易用:
Spark支持Java、Python和Scala的API,还支持超过80种高级算法,使用户可以快速构建不同的应用。而且Spark支持交互式的Python和Scala的shell,可以非常方便地在这些shell中使用Spark集群来验证解决问题的方法。
通用:
Spark提供了统一的解决方案。Spark可以用于批处理、交互式查询(Spark SQL)、实时流处理(Spark Streaming)、机器学习(Spark MLlib)和图计算(GraphX)。这些不同类型的处理都可以在同一个应用中无缝使用。Spark统一的解决方案非常具有吸引力,毕竟任何公司都想用统一的平台去处理遇到的问题,减少开发和维护的人力成本和部署平台的物力成本。
兼容性:
Spark可以非常方便地与其他的开源产品进行融合。比如,Spark可以使用Hadoop的YARN和Apache Mesos作为它的资源管理和调度器,器,并且可以处理所有Hadoop支持的数据,包括HDFS、HBase和Cassandra等。这对于已经部署Hadoop集群的用户特别重要,因为不需要做任何数据迁移就可以使用Spark的强大处理能力。Spark也可以不依赖于第三方的资源管理和调度器,它实现了Standalone作为其内置的资源管理和调度框架,这样进一步降低了Spark的使用门槛,使得所有人都可以非常容易地部署和使用Spark。此外,Spark还提供了在EC2上部署Standalone的Spark集群的工具。
1.3 Spark的用户和用途
我们大致把Spark的用例分为两类:数据科学应用和数据处理应用。也就对应的有两种人群:数据科学家和工程师。
数据科学任务:
主要是数据分析领域,数据科学家要负责分析数据并建模,具备 SQL、统计、预测建模(机器学习)等方面的经验,以及一定的使用 Python、 Matlab 或 R 语言进行编程的能力。
数据处理应用:
工程师定义为使用 Spark 开发 生产环境中的数据处理应用的软件开发者,通过对接Spark的API实现对处理的处理和转换等任务。
二、Spark部署
两种部署方式:
第一种:Standalone
1.解压
$ tar -zxf ~/softwares/installtions/spark-2.1.1-bin-hadoop2.7.tgz -C ~/modules/
2.修改配置文件,将所有以template结尾的文件拓展名去掉
cd /home/admin/modules/spark-2.1.1-bin-hadoop2.7/conf
vim salves linux01
linux02
linux03
vim spark-defaults.conf 配置历史服务 spark.eventLog.enabled true
spark.eventLog.dir hdfs://linux01:8020/directory
spark.eventLog.compress true
vim spark-env.sh SPARK_MASTER_HOST=linux01
SPARK_MASTER_PORT=7077 export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=4000
-Dspark.history.retainedApplications=3
-Dspark.history.fs.logDirectory=hdfs://linux01:8020/directory"
3.到hdfs中创建directory目录
$ cd ~/modules/hadoop-2.7.2/ $ bin/hdfs dfs -mkdir /directory
4.分发配置完成的Spark
$ scp -r ~/modules/spark-2.1.1-bin-hadoop2.7/ linux02:/home/admin/modules/
$ scp -r ~/modules/spark-2.1.1-bin-hadoop2.7/ linux03:/home/admin/modules/
第二种:YARN
1.修改配置
$ vim /home/admin/modules/hadoop-2.7.2/etc/hadoop/yarn-site.xml
添加下面配置
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
2.分发配置
$ scp -r /home/admin/modules/hadoop-2.7.2/etc linux02:/home/admin/modules/hadoop-2.7.2/
$ scp -r /home/admin/modules/hadoop-2.7.2/etc linux03:/home/admin/modules/hadoop-2.7.2/
3.重启整个集群
$ sh /home/admin/tools/stop-cluster.sh
$ sh /home/admin/tools/start-cluster.sh
4.修改spark-evn.sh
vim /home/admin/modules/spark-2.1.1-bin-hadoop2.7/conf/spark-env.sh HADOOP_CONF_DIR=/home/admin/modules/hadoop-2.7.2/etc/hadoop
YARN_CONF_DIR=/home/admin/modules/hadoop-2.7.2/etc/hadoop
5.分发spark-evn.sh
$ scp -r ~/modules/spark-2.1.1-bin-hadoop2.7/ linux02:/home/admin/modules/
$ scp -r ~/modules/spark-2.1.1-bin-hadoop2.7/ linux03:/home/admin/modules/
6.重启spark
$ sbin/stop-all.sh
$ sbin/start-all.sh
7.启动Spark历史日志服务
$ sbin/start-history-server.sh
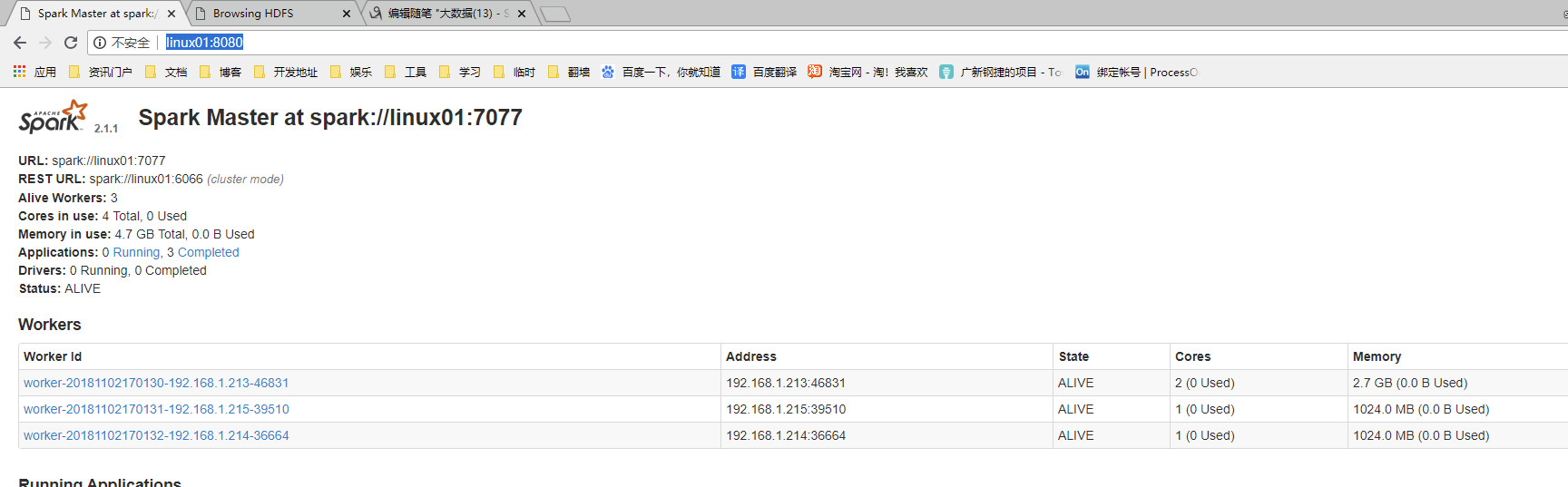
8.全部完成后确认,访问浏览器http://linux01:8080/
三、Spark简单使用
1.Spark-shell
$ bin/spark-shell \
--master spark://linux01:7077 \
--executor-memory 2g \
--total-executor-cores 2
2.Standalone提交jar包(任务:是一个使用蒙特卡洛算法,求圆周率)
$ /home/admin/modules/spark-2.1.1-bin-hadoop2.7/bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://linux01:7077 \
--executor-memory 1G \
--total-executor-cores 2 \
/home/admin/modules/spark-2.1.1-bin-hadoop2.7/examples/jars/spark-examples_2.11-2.1.1.jar \
100
3.Local模式运行
$ /home/admin/modules/spark-2.1.1-bin-hadoop2.7/bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master local[*] \
--executor-memory 1G \
--total-executor-cores 2 \
/home/admin/modules/spark-2.1.1-bin-hadoop2.7/examples/jars/spark-examples_2.11-2.1.1.jar \
100
4.YARN模式运行
$ /home/admin/modules/spark-2.1.1-bin-hadoop2.7/bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
/home/admin/modules/spark-2.1.1-bin-hadoop2.7/examples/jars/spark-examples_2.11-2.1.1.jar \
100
大数据(13) - Spark的安装部署与简单使用的更多相关文章
- 【大数据之数据仓库】安装部署GreenPlum集群
本篇将向大家介绍如何快捷的安装部署GreenPlum测试集群,大家可以跟着我一块儿实践一把^_^ 1.主机资源 申请2台网易云主机,操作系统必须是RedHat或者CentOS,配置尽量高一点.如果是s ...
- 【互动问答分享】第13期决胜云计算大数据时代Spark亚太研究院公益大讲堂
“决胜云计算大数据时代” Spark亚太研究院100期公益大讲堂 [第13期互动问答分享] Q1:tachyon+spark框架现在有很多大公司在使用吧? Yahoo!已经在长期大规模使用: 国内也有 ...
- 【互动问答分享】第6期决胜云计算大数据时代Spark亚太研究院公益大讲堂
“决胜云计算大数据时代” Spark亚太研究院100期公益大讲堂 [第6期互动问答分享] Q1:spark streaming 可以不同数据流 join吗? Spark Streaming不同的数据流 ...
- 2020/4/26 大数据的zookeeper分布式安装
大数据的zookeeper分布式安装 **** 前面的文章已经提到Hadoop的伪分布式安装.现在就在原有的基础上安装zookeeper. 首先启动Hadoop平台 [root@master ~]# ...
- 【互动问答分享】第10期决胜云计算大数据时代Spark亚太研究院公益大讲堂
“决胜云计算大数据时代” Spark亚太研究院100期公益大讲堂 [第10期互动问答分享] Q1:Spark on Yarn的运行方式是什么? Spark on Yarn的运行方式有两种:Client ...
- 【互动问答分享】第8期决胜云计算大数据时代Spark亚太研究院公益大讲堂
“决胜云计算大数据时代” Spark亚太研究院100期公益大讲堂 [第8期互动问答分享] Q1:spark线上用什么版本好? 建议从最低使用的Spark 1.0.0版本,Spark在1.0.0开始核心 ...
- 【互动问答分享】第7期决胜云计算大数据时代Spark亚太研究院公益大讲堂
“决胜云计算大数据时代” Spark亚太研究院100期公益大讲堂 [第7期互动问答分享] Q1:Spark中的RDD到底是什么? RDD是Spark的核心抽象,可以把RDD看做“分布式函数编程语言”. ...
- CDH构建大数据平台-Kerberos高可用部署【完结篇】
CDH构建大数据平台-Kerberos高可用部署[完结篇] 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.安装Kerberos相关的软件包并同步配置文件 1>.实验环境 ...
- 【互动问答分享】第15期决胜云计算大数据时代Spark亚太研究院公益大讲堂
"决胜云计算大数据时代" Spark亚太研究院100期公益大讲堂 [第15期互动问答分享] Q1:AppClient和worker.master之间的关系是什么? AppClien ...
随机推荐
- 导入exce表格中的数据l到数据库
因为我的项目是JavaWeb的,所有是通过浏览器导入数据库到服务器端的数据库,这里我们采用struts来帮助我们完成. 1:首先定义一个文件上传的jsp页面.把我们的数据先上传到服务器端. <f ...
- Hbase总结(八)Hbase中的Coprocessor
1.起因(Why HBase Coprocessor) HBase作为列族数据库最常常被人诟病的特性包含:无法轻易建立"二级索引",难以运行求和.计数.排序等操作.比方,在旧版本 ...
- 【Oracle】查看死锁与解除死锁
1.查询死锁的进程(下面2条语句均可用) 语句1: select sess.sid, sess.serial#, lo.oracle_username, lo.os_user_name, ao.obj ...
- 基于UML的面向对象分析与设计
前言 经常听到有朋友抱怨,说学了UML不知该怎么用,或者画了UML却觉得没什么作用.其实,就UML本身来说,它只是一种交流工具,它作为一种标准化交流符号,在OOA&D过程 ...
- python 的集合 set()操作
Python 的集合 set(),是一个无序不重复元素集,可以用于关系测试和消除重复元素. 有以下运算: 1.创建一个set ()集合: 2.add:增加集合元素 3.clea ...
- pandas contact 之后,若要用到index列,要记得用reset_index去处理index
# -*- coding: utf-8 -*- import pandas as pd import sys df1 = pd.DataFrame({ 'A': ['A0', 'A1', 'A2', ...
- nodejs 的好基友:pm2
安装:npm install pm2 -g #全局安装pm2 查看版本:pm2 -v 自动重启: pm2 start hello.js --watch 查看列表:pm2 list 查看日志: pm2 ...
- C++ 基类指针和子类指针相互赋值
首先,给出基类animal和子类fish [cpp] view plaincopy //======================================================== ...
- XVAG音频文件格式提取
索尼的一种游戏音频格式,通过vgmstream工具可以提取 工具已经下载好:(包含dll包) http://files.cnblogs.com/files/hont/vgmstream-r1040-t ...
- NGUI和UGUI动画不能设置alpha值的问题
动画播放alpha参数改变但无实际画面效果,原因是要挂一个脚本,设置实时更新数据. NGUI void Update() { widget.SetDirty(); } UGUI void Update ...