(七)7.2 应用机器学习方法的技巧,准确率,召回率与 F值
建立模型
当使用机器学习的方法来解决问题时,比如垃圾邮件分类等,一般的步骤是这样的:
1)从一个简单的算法入手这样可以很快的实现这个算法,并且可以在交叉验证集上进行测试;
2)画学习曲线以决定是否更多的数据,更多的特征或者其他方式会有所帮助;
3)人工检查那些算法预测错误的例子(在交叉验证集上),看看能否找到一些产生错误的原因。
评估模型
首先,引入一个概念,非对称性分类。考虑癌症预测问题,y=1 代表癌症,y=0 代表没有癌症,对于一个数据集,我们建立logistic 回归模型,经过以上建模的步骤,得到一个优化的模型,错误率仅为1%,这貌似是一个很好的结果,但考虑数据集若仅有0.05%的正例(y=1),那么我们直接预测所有y=0,我们得到的模型的错误率仅为0.5%,这便是非对称分类的问题,这样的问题仅考虑错误率是有风险的。
下面引入一种标准的衡量方法:Precision/Recall(精确度和召回率),这种度量最早出现在信息检索问题中的,如下:
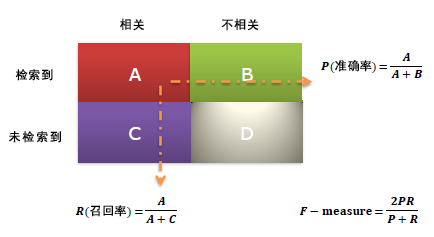
在机器学习的模型中,也可以用这种评估方法,具体如下:

其中:
True Positive (真正例, TP)被模型预测为正的正样本;可以称作判断为真的正确率
True Negative(真负例 , TN)被模型预测为负的负样本 ;可以称作判断为假的正确率
False Positive (假正例, FP)被模型预测为正的负样本;可以称作误报率
False Negative(假负例 , FN)被模型预测为负的正样本;可以称作漏报率
现在需要考虑权衡Precision/Recall:
以logistic 回归为例:
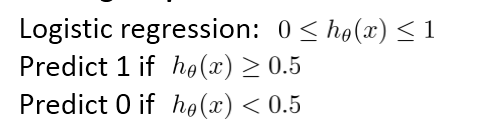
假设我们非常有把握时才预测病人得癌症(y=1), 这个时候,我们常常将阈值设置的很高,FP变小,FN增大,这会导致高精确度,低召回率(Higher precision, lower recall);
假设我们不希望将太多的癌症例子错分(避免假负例,本身得了癌症,确被分类为没有得癌症), 这个时候,阈值就可以设置的低一些,FP变大,FN变小,这又会导致高召回率,低精确度(Higher recall, lower precision);

以上的描述可以用如下的PR曲线来描述,一般准确率提高,召回率会下降:
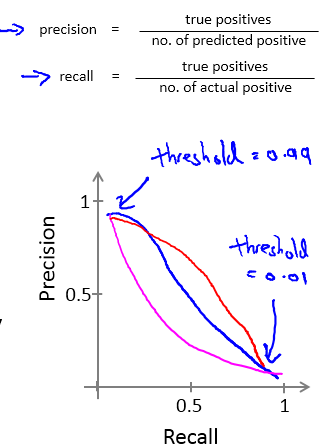
关于如何权衡准确率与召回率:
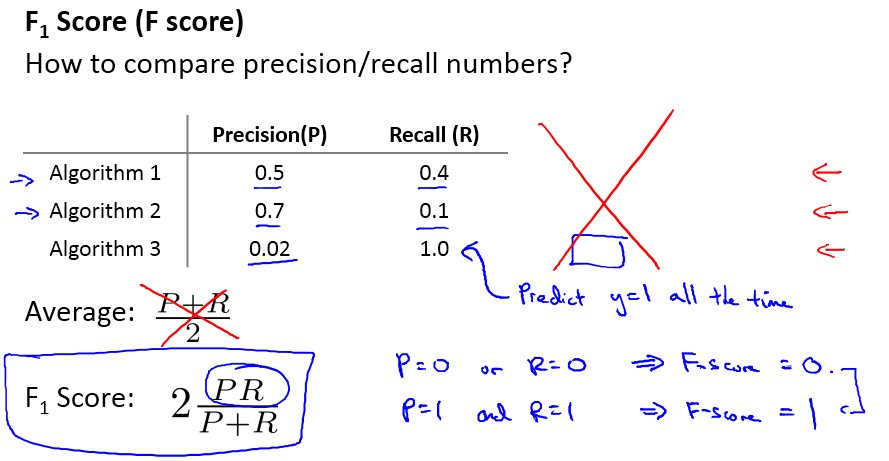
如果是做搜索,那就是保证召回的情况下提升准确率;如果做疾病监测、反垃圾,则是保准确率的条件下,提升召回。在两者都要求高的情况下,可以用F1来衡量。
(七)7.2 应用机器学习方法的技巧,准确率,召回率与 F值的更多相关文章
- CS229 7.2 应用机器学习方法的技巧,准确率,召回率与 F值
建立模型 当使用机器学习的方法来解决问题时,比如垃圾邮件分类等,一般的步骤是这样的: 1)从一个简单的算法入手这样可以很快的实现这个算法,并且可以在交叉验证集上进行测试: 2)画学习曲线以决定是否更多 ...
- 美团网基于机器学习方法的POI品类推荐算法
美团网基于机器学习方法的POI品类推荐算法 前言 在美团商家数据中心(MDC),有超过100w的已校准审核的POI数据(我们一般将商家标示为POI,POI基础信息包括:门店名称.品类.电话.地址.坐标 ...
- Stanford机器学习---第六讲. 怎样选择机器学习方法、系统
原文:http://blog.csdn.net/abcjennifer/article/details/7797502 本栏目(Machine learning)包括单参数的线性回归.多参数的线性回归 ...
- Android群英传》读书笔记 (3) 第六章 Android绘图机制与处理技巧 + 第七章 Android动画机制与使用技巧
第六章 Android绘图机制与处理技巧 1.屏幕尺寸信息屏幕大小:屏幕对角线长度,单位“寸”:分辨率:手机屏幕像素点个数,例如720x1280分辨率:PPI(Pixels Per Inch):即DP ...
- 关于”机器学习方法“,"深度学习方法"系列
"机器学习/深度学习方法"系列,我本着开放与共享(open and share)的精神撰写,目的是让很多其它的人了解机器学习的概念,理解其原理,学会应用.如今网上各种技术类文章非常 ...
- R语言进行机器学习方法及实例(一)
版权声明:本文为博主原创文章,转载请注明出处 机器学习的研究领域是发明计算机算法,把数据转变为智能行为.机器学习和数据挖掘的区别可能是机器学习侧重于执行一个已知的任务,而数据发掘是在大数据中寻找有 ...
- 机器学习方法、距离度量、K_Means
特征向量 1.特征向量:以人为例,每个元素可能就对应这人的某些方面,这就是特征,例如:身高.年龄.性别.国际....2.特征工程:目的就是将现有数据中可作为信号的特征与那些仅是噪声的特征区分开来:当数 ...
- 不平衡数据下的机器学习方法简介 imbalanced time series classification
imbalanced time series classification http://www.vipzhuanli.com/pat/books/201510229367.5/2.html?page ...
- 基于CRF工具的机器学习方法命名实体识别的过
[转自百度文库] 基于CRF工具的机器学习方法命名实体识别的过程 | 浏览:226 | 更新:2014-04-11 09:32 这里只讲基本过程,不涉及具体实现,我也是初学者,想给其他初学者一些帮助, ...
随机推荐
- .net web程序发布之后,出现编译错误
.net web程序发布之后,在IIS上浏览的时候出现编译错误. CS0016: 未能写入输出文件“c:\Windows\Microsoft.NET\Framework\v4.0.30319\Temp ...
- Win32应用程序中文支持
Settings--Editor---Encoding改为Windows 936 main.cpp中#include "locale.h" winmain中增加一行: setloc ...
- 如何提高SQL的执行效率
一.因情制宜,建立“适当”的索引 建立“适当”的索引是实现查询优化的首要前提. 索引(index)是除表之外另一重要的.用户定义的存储在物理介质上的数据结构.当根据索引码的值搜索数据时,索引提供了对数 ...
- eclipse调试web项目
Eclipse上的Web项目调试 在Eclipse中开发Web项目的首要难题就是如何进行代码调试.本文简要说明一下在Eclipse中使用Tomcat和Jetty调试Java Web项目的方法. Tom ...
- WordPress主题制作教程2:导航菜单制作
实现自定义菜单,需要用到的函数是wp_nav_menu(); 在主题目录下的functions.php的 <?php ….. ?> 之间,添加以下菜单注册代码,这样你就可以在主题文件中使用 ...
- Gray code---hdu5375(格雷码与二进制码,普通dp)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=5375 题意就是:给你一串二进制码,里面可能含有'?'这个既可以表示0又可以表示1, 让我们把这个二进制 ...
- 【转】RESTful Web Services初探
近几年,RESTful Web Services渐渐开始流行,大量用于解决异构系统间的通信问题.很多网站和应用提供的API,都是基于RESTful风格的Web Services,比较著名的包括Twit ...
- Jenkins Master/Slave架构
原文:http://www.cnblogs.com/itech/archive/2011/11/11/2245849.html 一 Jenkins Master/Slave架构 Master/Slav ...
- usb协议分析-设备描述符配置包-描述符
/* usb协议分析仅供大家参考---设备描述符配置包,设备描述符, 地址设置, 配置描述符, 字符串描述符 */ /* -1- usb设备描述符配置包 */ typedef struct _USB_ ...
- MySQL工具:管理员必备的10款MySQL工具
MySQL是一个复杂的的系统,需要许多工具来修复,诊断和优化它.幸运的是,对于管理员,MySQL已经吸引了很多软件开发商推出高品质的开源工具来解决MySQL的系统的复杂性,性能和稳定性,其中大部分是免 ...