ElasticSearch 5学习(6)——分布式集群学习分享1
在使用中我们把文档存入ElasticSearch,但是如果能够了解ElasticSearch内部是如何存储的,将会对我们学习ElasticSearch有很清晰的认识。本文中的所使用的ElasticSearch集群环境,可以通过查看ElasticSearch 5学习(3)——单台服务器部署多个节点搭建学习。
ElasticSearch用于构建高可用和可扩展的系统。扩展的方式可以是购买更好的服务器(纵向扩展(vertical scale or scaling up))或者购买更多的服务器(横向扩展(horizontal scale or scaling out))。
Elasticsearch虽然能从更强大的硬件中获得更好的性能,但是纵向扩展有它的局限性。真正的扩展应该是横向的,它通过增加节点来均摊负载和增加可靠性。
对于大多数数据库而言,横向扩展意味着你的程序将做非常大的改动才能利用这些新添加的设备。对比来说,Elasticsearch天生就是分布式的:它知道如何管理节点来提供高扩展和高可用。这意味着你的程序不需要关心这些。
下面的例子主要围绕着集群(cluster)、节点(node)和分片(shard)讲解,相信学习以后,对于学习Elasticsearch会有很大收获。
空集群
如果我们启动一个单独的节点,它还没有数据和索引,这个集群看起来如下图:

只有一个空节点的集群。一个节点(node)就是一个Elasticsearch实例,而一个集群(cluster)由一个或多个节点组成,它们具有相同cluster.name,它们协同工作,分享数据和负载。当加入新的节点或者删除一个节点时,集群就会感知到并平衡数据。
集群中一个节点会被选举为主节点(master),它将临时管理集群级别的一些变更,例如新建或删除索引、增加或移除节点等。主节点不参与文档级别的变更或搜索,这意味着在流量增长的时候,该主节点不会成为集群的瓶颈。任何节点都可以成为主节点。我们例子中的集群只有一个节点,所以它会充当主节点的角色。
做为用户,我们能够与集群中的任何节点通信,包括主节点。每一个节点都知道文档存在于哪个节点上,它们可以转发请求到相应的节点上。我们访问的节点负责收集各节点返回的数据,最后一起返回给客户端。这一切都由Elasticsearch处理。
集群健康
在Elasticsearch集群中可以监控统计很多信息,但是只有一个是最重要的:集群健康(cluster health)。集群健康有三种状态:green、yellow或red,健康状况在后面会有很多体现。
GET /_cluster/health
在一个没有索引的空集群中运行如上查询,将返回这些信息:
{
"cluster_name": "elasticsearch",
"status": "green",
"timed_out": false,
"number_of_nodes": 1,
"number_of_data_nodes": 1,
"active_primary_shards": 0,
"active_shards": 0,
"relocating_shards": 0,
"initializing_shards": 0,
"unassigned_shards": 0
}
status 是我们最感兴趣的字段。
status字段提供一个综合的指标来表示集群的的服务状况。三种颜色各自的含义:
green:所有主要分片和复制分片都可用。
yellow:所有主要分片可用,但不是所有复制分片都可用。
red:不是所有的主要分片都可用。
添加索引
为了将数据添加到Elasticsearch,我们需要索引(index)——一个存储关联数据的地方。实际上,索引只是一个用来指向一个或多个分片(shards)的“逻辑命名空间(logical namespace)”.
一个分片(shard)是一个最小级别“工作单元(worker unit)”,它只是保存了索引中所有数据的一部分。并且先初步知道分片就是一个Lucene实例,它本身就是一个完整的搜索引擎。我们的文档存储在分片中,并且在分片中被索引,但是我们的应用程序不会直接与它们通信,取而代之的是,直接与索引通信。
分片是Elasticsearch在集群中分发数据的关键。把分片想象成数据的容器。文档存储在分片中,然后分片分配到你集群中的节点上。当你的集群扩容或缩小,Elasticsearch将会自动在你的节点间迁移分片,以使集群保持平衡。
分片可以是主分片(primary shard)或者是复制分片(replica shard)。你索引中的每个文档属于一个单独的主分片,所以主分片的数量决定了索引最多能存储多少数据(这句话可能不好理解,在以后学习文档具体在分片中如何存储的时候会学习)。当索引创建完成的时候,主分片的数量就固定了,但是复制分片的数量可以随时调整。
复制分片只是主分片的一个副本,它可以防止硬件故障导致的数据丢失,同时可以提供读请求,比如搜索或者从别的分片取回文档。
让我们在集群中唯一一个空节点上创建一个叫做blogs的索引。默认情况下,一个索引被分配5个主分片,但是为了演示的目的,我们只分配3个主分片和一个复制分片(每个主分片都有一个复制分片):
PUT /blogs
{
"settings" : {
"number_of_shards" : 3,
"number_of_replicas" : 1
}
}

我们的集群现在看起来就像上图——三个主分片都被分配到Node 1。如果我们现在检查集群健康(cluster-health),我们将见到以下信息:
{
"cluster_name": "elasticsearch",
"status": "yellow", <1>
"timed_out": false,
"number_of_nodes": 1,
"number_of_data_nodes": 1,
"active_primary_shards": 3,
"active_shards": 3,
"relocating_shards": 0,
"initializing_shards": 0,
"unassigned_shards": 3 <2>
}
- 集群的状态现在是
yellow - 我们的三个复制分片还没有被分配到节点上
下面我们可以看下,在Kibana监控工具中查看具体情况,如下图:

和上面分析的内容是一致的。
集群的健康状态yellow表示所有的主分片(primary shards)启动并且正常运行了——集群已经可以正常处理任何请求——但是复制分片(replica shards)还没有全部可用。事实上所有的三个复制分片现在都是unassigned状态——它们还未被分配给节点。在同一个节点上保存相同的数据副本是没有必要的,如果这个节点故障了,那所有的数据副本也会丢失。
现在我们的集群已经功能完备,但是依旧存在因硬件故障而导致数据丢失的风险。
添加故障转移
在单一节点上运行意味着有单点故障的风险——没有数据备份。幸运的是,要防止单点故障,我们唯一需要做的就是启动另一个节点。
具体启动方式可以查看ElasticSearch 5学习(3)——单台服务器部署多个节点。
如果我们启动了第二个节点,这个集群看起来就像下图。双节点集群——所有的主分片和复制分片都已分配:

第二个节点已经加入集群,三个复制分片(replica shards)也已经被分配了——分别对应三个主分片,这意味着在丢失任意一个节点的情况下依旧可以保证数据的完整性。
文档的索引将首先被存储在主分片中,然后并发复制到对应的复制节点上。这可以确保我们的数据在主节点和复制节点上都可以被检索。
cluster-health现在的状态是green,这意味着所有的6个分片(三个主分片和三个复制分片)都已可用:
{
"cluster_name": "elasticsearch",
"status": "green",
"timed_out": false,
"number_of_nodes": 2,
"number_of_data_nodes": 2,
"active_primary_shards": 3,
"active_shards": 6,
"relocating_shards": 0,
"initializing_shards": 0,
"unassigned_shards": 0
}
集群的状态是green,我们的集群不仅是功能完备的,而且是高可用的。
同样我们可以看下实际的操作结果:

横向扩展
随着应用需求的增长,我们该如何扩展?如果我们启动第三个节点,我们的集群会重新组织自己,包含3个节点的集群——分片已经被重新分配以平衡负载:
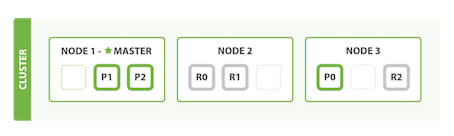
Node 3包含了分别来自Node 1和Node 2的一个分片,这样每个节点就有两个分片,和之前相比少了一个,这意味着每个节点上的分片将获得更多的硬件资源(CPU、RAM、I/O)。
分片本身就是一个完整的搜索引擎,它可以使用单一节点的所有资源。我们拥有6个分片(3个主分片和三个复制分片),最多可以扩展到6个节点,每个节点上有一个分片,每个分片可以100%使用这个节点的资源。
同样我们可以看下实际的操作结果:

继续扩展
如果我们要扩展到6个以上的节点,要怎么做?
主分片的数量在创建索引时已经确定。实际上,这个数量定义了能存储到索引里数据的最大数量(实际的数量取决于你的数据、硬件和应用场景)。然而,主分片或者复制分片都可以处理读请求——搜索或文档检索,所以数据的冗余越多,我们能处理的搜索吞吐量就越大。
复制分片的数量可以在运行中的集群中动态地变更,这允许我们可以根据需求扩大或者缩小规模。让我们把复制分片的数量从原来的1增加到2:
PUT /blogs/_settings
{
"number_of_replicas" : 2
}
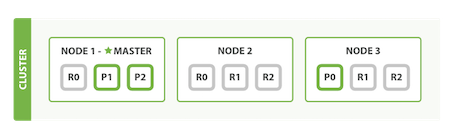
从图中可以看出,blogs索引现在有9个分片:3个主分片和6个复制分片。这意味着我们能够扩展到9个节点,再次变成每个节点一个分片。这样使我们的搜索性能相比原始的三节点集群增加“三倍”。
实际操作也是同样的效果:

注意:可以看到上面的“三倍”我们用加了引号,因为在同样数量的节点上增加更多的复制分片并不一定提高性能,因为这样做的话平均每个分片的所占有的硬件资源就减少了(大部分请求都聚集到了分片少的节点,导致一个节点吞吐量太大,反而降低性能),你需要增加硬件来提高吞吐量。所以说添加复制分片和添加节点,在保证成本的情况下,需要有一个平衡点。
不过这些额外的复制节点还是有另外一个好处,使我们有更多的冗余:通过以上对节点的设置,我们能够承受两个节点故障而不丢失数据。
总结
对于ES分布式集群如果对节点、分片的处理基本学习完毕,可以感受到ES分布式集群的自动化,对于用户来说几乎完全透明化。但是,一个分布式集群主要看它的高性能、高并发和高可用。上面的内容虽然体现了一些,但是还包括对故障的处理能力,在ElasticSearch 5学习(7)——分布式集群学习分享2和大家分享。
转载请注明出处。
作者:wuxiwei
出处:http://www.cnblogs.com/wxw16/p/6188044.html
ElasticSearch 5学习(6)——分布式集群学习分享1的更多相关文章
- ElasticSearch 5学习(7)——分布式集群学习分享2
前面主要学习了ElasticSearch分布式集群的存储过程中集群.节点和分片的知识(ElasticSearch 5学习(6)--分布式集群学习分享1),下面主要分享应对故障的一些实践. 应对故障 前 ...
- 一脸懵逼学习Hadoop分布式集群HA模式部署(七台机器跑集群)
1)集群规划:主机名 IP 安装的软件 运行的进程master 192.168.199.130 jdk.hadoop ...
- ElasticSearch权威指南学习(分布式集群)
空集群 只有一个空节点的集群 一个节点(node)就是一个Elasticsearch实例,而一个集群(cluster)由一个或多个节点组成,它们具有相同的cluster.name,它们协同工作,分享数 ...
- mac 下搭建Elasticsearch 5.4.3分布式集群
一.集群角色 多机集群中的节点可以分为master nodes和data nodes,在配置文件中使用Zen发现(Zen discovery)机制来管理不同节点.Zen发现是ES自带的默认发现机制,使 ...
- 【Database】Mysql分布式集群学习笔记
一.sql 的基本操作 (2018年11月29日,笔记) (1)数据库相关操作 创建数据库.查看数据库.删除数据库 #. 创建数据库 create database mytest default ch ...
- 超快速使用docker在本地搭建hadoop分布式集群
超快速使用docker在本地搭建hadoop分布式集群 超快速使用docker在本地搭建hadoop分布式集群 学习hadoop集群环境搭建是hadoop入门的必经之路.搭建分布式集群通常有两个办法: ...
- Elasticsearch学习系列七(Es分布式集群)
核心概念 集群(Cluster) 一个Es集群由多个节点(Node)组成,每个集群都有一个共同的集群名称作为标识 节点(Node) 一个Es实例就是一个Node.Es的配置文件中可以通过node.ma ...
- hadoop学习之hadoop完全分布式集群安装
注:本文的主要目的是为了记录自己的学习过程,也方便与大家做交流.转载请注明来自: http://blog.csdn.net/ab198604/article/details/8250461 要想深入的 ...
- hadoop学习通过虚拟机安装hadoop完全分布式集群
要想深入的学习hadoop数据分析技术,首要的任务是必须要将hadoop集群环境搭建起来,可以将hadoop简化地想象成一个小软件,通过在各个物理节点上安装这个小软件,然后将其运行起来,就是一个had ...
随机推荐
- 旺财速啃H5框架之Bootstrap(五)
在上一篇<<旺财速啃H5框架之Bootstrap(四)>>做了基本的框架,<<旺财速啃H5框架之Bootstrap(二)>>篇里也大体认识了bootst ...
- SQL Server 常用内置函数(built-in)持续整理
本文用于收集在运维中经常使用的系统内置函数,持续整理中 一,常用Metadata函数 1,查看数据库的ID和Name db_id(‘DB Name’),db_name('DB ID') 2,查看对象的 ...
- Minor【 PHP框架】1.简介
1.1 Minor是什么 Minor是一个简单但是优秀的符合PSR4的PHP框架,It just did what a framework should do. 只做一个框架应该做的,简单而又强大! ...
- Angular企业级开发(4)-ngResource和REST介绍
一.RESTful介绍 RESTful维基百科 REST(表征性状态传输,Representational State Transfer)是Roy Fielding博士在2000年他的博士论文中提出来 ...
- [C#] 简单的 Helper 封装 -- RandomHelper
using System; namespace Wen.Helpers { /// <summary> /// 随机数助手 /// </summary> public seal ...
- Nginx如何处理一个请求
看了下nginx的官方文档,其中nginx如何处理一个请求讲解的很好,现在贴出来分享下.Nginx首先选定由哪一个虚拟主机来处理请求.让我们从一个简单的配置(其中全部3个虚拟主机都在端口*:80上监听 ...
- PHP之购物车的代码
该文章记录了购物车的实现代码,仅供参考 book_sc_fns.php <?php include_once('output_fns.php'); include_once('book_fns. ...
- bzoj1901--树状数组套主席树
树状数组套主席树模板题... 题目大意: 给定一个含有n个数的序列a[1],a[2],a[3]--a[n],程序必须回答这样的询问:对于给定的i,j,k,在a[i],a[i+1],a[i+2]--a[ ...
- JavaScript作用域
JavaScript作用域 JavaScript作用域一直是前端开发的难题,现在只要用五句话就可解决. 一.“JavaScript中无块级作用域” 在Java或C#中存在块级作用域,即:大括号也是一个 ...
- 一条Sql语句分组排序并且限制显示的数据条数
如果我想得到这样一个结果集:分组排序,并且每组限定记录集的数量,用一条SQL语句能办到吗? 比如说,我想找出学生期末考试中,每科的前3名,并按成绩排序,只用一条SQL语句,该怎么写? 表[TScore ...