Spark笔记之累加器(Accumulator)
一、累加器简介
在Spark中如果想在Task计算的时候统计某些事件的数量,使用filter/reduce也可以,但是使用累加器是一种更方便的方式,累加器一个比较经典的应用场景是用来在Spark Streaming应用中记录某些事件的数量。
使用累加器时需要注意只有Driver能够取到累加器的值,Task端进行的是累加操作。
创建的Accumulator变量的值能够在Spark Web UI上看到,在创建时应该尽量为其命名,下面探讨如何在Spark Web UI上查看累加器的值。
示例代码:
package cc11001100.spark.sharedVariables.accumulators; import org.apache.spark.api.java.function.ForeachFunction;
import org.apache.spark.sql.Encoders;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.util.LongAccumulator; import java.util.Collections;
import java.util.concurrent.TimeUnit; /**
* @author CC11001100
*/
public class SparkWebUIShowAccumulatorDemo { public static void main(String[] args) { SparkSession spark = SparkSession.builder().master("local[*]").getOrCreate();
LongAccumulator fooCount = spark.sparkContext().longAccumulator("fooCount"); spark.createDataset(Collections.singletonList(1024), Encoders.INT())
.foreach((ForeachFunction<Integer>) fooCount::add); try {
TimeUnit.DAYS.sleep(365 * 10000);
} catch (InterruptedException e) {
e.printStackTrace();
} } }
启动的时候注意观察控制台上输出的Spark Web UI的地址:

打开此链接,点进去Jobs-->Stage,可以看到fooCount累加器的值已经被累加到了1024:
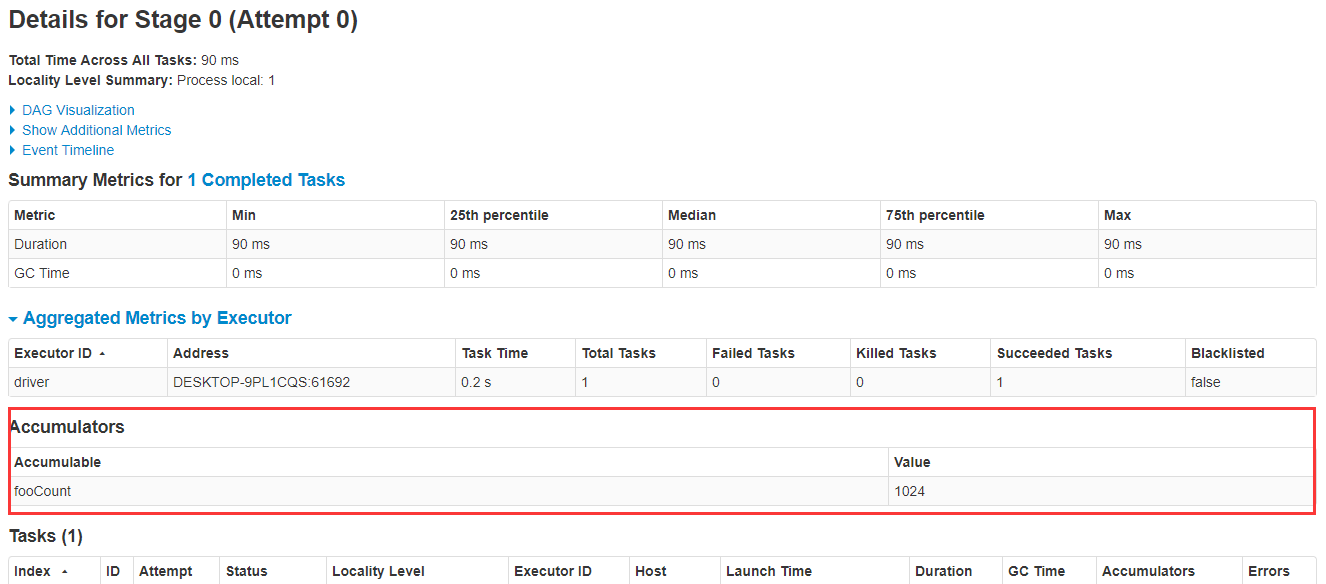
二、Accumulator的简单使用
Spark内置了三种类型的Accumulator,分别是LongAccumulator用来累加整数型,DoubleAccumulator用来累加浮点型,CollectionAccumulator用来累加集合元素。
package cc11001100.spark.sharedVariables.accumulators; import org.apache.spark.SparkContext;
import org.apache.spark.api.java.function.MapFunction;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Encoders;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.util.CollectionAccumulator;
import org.apache.spark.util.DoubleAccumulator;
import org.apache.spark.util.LongAccumulator; import java.util.Arrays; /**
* 累加器的基本使用
*
* @author CC11001100
*/
public class AccumulatorsSimpleUseDemo { public static void main(String[] args) { SparkSession spark = SparkSession.builder().master("local[*]").getOrCreate();
SparkContext sc = spark.sparkContext(); // 内置的累加器有三种,LongAccumulator、DoubleAccumulator、CollectionAccumulator
// LongAccumulator: 数值型累加
LongAccumulator longAccumulator = sc.longAccumulator("long-account");
// DoubleAccumulator: 小数型累加
DoubleAccumulator doubleAccumulator = sc.doubleAccumulator("double-account");
// CollectionAccumulator:集合累加
CollectionAccumulator<Integer> collectionAccumulator = sc.collectionAccumulator("double-account"); Dataset<Integer> num1 = spark.createDataset(Arrays.asList(1, 2, 3), Encoders.INT());
Dataset<Integer> num2 = num1.map((MapFunction<Integer, Integer>) x -> {
longAccumulator.add(x);
doubleAccumulator.add(x);
collectionAccumulator.add(x);
return x;
}, Encoders.INT()).cache(); num2.count(); System.out.println("longAccumulator: " + longAccumulator.value());
System.out.println("doubleAccumulator: " + doubleAccumulator.value());
// 注意,集合中元素的顺序是无法保证的,多运行几次发现每次元素的顺序都可能会变化
System.out.println("collectionAccumulator: " + collectionAccumulator.value()); } }
三、自定义Accumulator
当内置的Accumulator无法满足要求时,可以继承AccumulatorV2实现自定义的累加器。
实现自定义累加器的步骤:
1. 继承AccumulatorV2,实现相关方法
2. 创建自定义Accumulator的实例,然后在SparkContext上注册它
假设要累加的数非常大,内置的LongAccumulator已经无法满足需求,下面是一个简单的例子用来累加BigInteger:
package cc11001100.spark.sharedVariables.accumulators; import org.apache.spark.SparkContext;
import org.apache.spark.api.java.function.MapFunction;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Encoders;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.util.AccumulatorV2; import java.math.BigInteger;
import java.util.Arrays;
import java.util.List; /**
* 自定义累加器
*
* @author CC11001100
*/
public class CustomAccumulatorDemo { // 需要注意的是累加操作不能依赖顺序,比如类似于StringAccumulator这种则会得到错误的结果
public static class BigIntegerAccumulator extends AccumulatorV2<BigInteger, BigInteger> { private BigInteger num = BigInteger.ZERO; public BigIntegerAccumulator() {
} public BigIntegerAccumulator(BigInteger num) {
this.num = new BigInteger(num.toString());
} @Override
public boolean isZero() {
return num.compareTo(BigInteger.ZERO) == 0;
} @Override
public AccumulatorV2<BigInteger, BigInteger> copy() {
return new BigIntegerAccumulator(num);
} @Override
public void reset() {
num = BigInteger.ZERO;
} @Override
public void add(BigInteger num) {
this.num = this.num.add(num);
} @Override
public void merge(AccumulatorV2<BigInteger, BigInteger> other) {
num = num.add(other.value());
} @Override
public BigInteger value() {
return num;
}
} public static void main(String[] args) { SparkSession spark = SparkSession.builder().master("local[*]").getOrCreate();
SparkContext sc = spark.sparkContext(); // 直接new自定义的累加器
BigIntegerAccumulator bigIntegerAccumulator = new BigIntegerAccumulator();
// 然后在SparkContext上注册一下
sc.register(bigIntegerAccumulator, "bigIntegerAccumulator"); List<BigInteger> numList = Arrays.asList(new BigInteger("9999999999999999999999"), new BigInteger("9999999999999999999999"), new BigInteger("9999999999999999999999"));
Dataset<BigInteger> num = spark.createDataset(numList, Encoders.kryo(BigInteger.class));
Dataset<BigInteger> num2 = num.map((MapFunction<BigInteger, BigInteger>) x -> {
bigIntegerAccumulator.add(x);
return x;
}, Encoders.kryo(BigInteger.class)); num2.count();
System.out.println("bigIntegerAccumulator: " + bigIntegerAccumulator.value()); } }
思考:内置的累加器LongAccumulator、DoubleAccumulator、CollectionAccumulator和我上面的自定义BigIntegerAccumulator,它们都有一个共同的特点,就是最终的结果不受累加数据顺序的影响(对于CollectionAccumulator来说,可以简单的将结果集看做是一个无序Set),看到网上有博主举例子StringAccumulator,这个就是一个错误的例子,就相当于开了一百个线程,每个线程随机sleep若干毫秒然后往StringBuffer中追加字符,最后追加出来的字符串是无法被预测的。总结一下就是累加器的最终结果应该不受累加顺序的影响,否则就要重新审视一下这个累加器的设计是否合理。
四、使用Accumulator的陷阱
来讨论一下使用累加器的一些陷阱,累加器的累加是在Task中进行的,而这些Task就是我们在Dataset上调用的一些算子操作,这些算子操作有Transform的,也有Action的,来探讨一下不同类型的算子对Accumulator有什么影响。
package cc11001100.spark.sharedVariables.accumulators; import org.apache.spark.SparkContext;
import org.apache.spark.api.java.function.MapFunction;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Encoders;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.util.LongAccumulator; import java.util.Arrays; /**
* 累加器使用的陷阱
*
* @author CC11001100
*/
public class AccumulatorTrapDemo { public static void main(String[] args) { SparkSession spark = SparkSession.builder().master("local[*]").getOrCreate();
SparkContext sc = spark.sparkContext();
LongAccumulator longAccumulator = sc.longAccumulator("long-account"); // ------------------------------- 在transform算子中的错误使用 ------------------------------------------- Dataset<Integer> num1 = spark.createDataset(Arrays.asList(1, 2, 3), Encoders.INT());
Dataset<Integer> nums2 = num1.map((MapFunction<Integer, Integer>) x -> {
longAccumulator.add(1);
return x;
}, Encoders.INT()); // 因为没有Action操作,nums.map并没有被执行,因此此时广播变量的值还是0
System.out.println("num2 1: " + longAccumulator.value()); // 0 // 调用一次action操作,num.map得到执行,广播变量被改变
nums2.count();
System.out.println("num2 2: " + longAccumulator.value()); // 3 // 又调用了一次Action操作,广播变量所在的map又被执行了一次,所以累加器又被累加了一遍,就悲剧了
nums2.count();
System.out.println("num2 3: " + longAccumulator.value()); // 6 // ------------------------------- 在transform算子中的正确使用 ------------------------------------------- // 累加器不应该被重复使用,或者在合适的时候进行cache断开与之前Dataset的血缘关系,因为cache了就不必重复计算了
longAccumulator.setValue(0);
Dataset<Integer> nums3 = num1.map((MapFunction<Integer, Integer>) x -> {
longAccumulator.add(1);
return x;
}, Encoders.INT()).cache(); // 注意这个地方进行了cache // 因为没有Action操作,nums.map并没有被执行,因此此时广播变量的值还是0
System.out.println("num3 1: " + longAccumulator.value()); // 0 // 调用一次action操作,广播变量被改变
nums3.count();
System.out.println("num3 2: " + longAccumulator.value()); // 3 // 又调用了一次Action操作,因为前一次调用count时num3已经被cache,num2.map不会被再执行一遍,所以这里的值还是3
nums3.count();
System.out.println("num3 3: " + longAccumulator.value()); // 3 // ------------------------------- 在action算子中的使用 -------------------------------------------
longAccumulator.setValue(0);
num1.foreach(x -> {
longAccumulator.add(1);
});
// 因为是Action操作,会被立即执行所以打印的结果是符合预期的
System.out.println("num4: " + longAccumulator.value()); // 3 } }
五、Accumulator使用的奇淫技巧
累加器并不是只能用来实现加法,也可以用来实现减法,直接把要累加的数值改成负数就可以了:
package cc11001100.spark.sharedVariables.accumulators; import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Encoders;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.util.LongAccumulator; import java.util.Arrays; /**
* 使用累加器实现减法
*
* @author CC11001100
*/
public class AccumulatorSubtraction { public static void main(String[] args) { SparkSession spark = SparkSession.builder().master("local[*]").getOrCreate();
Dataset<Integer> nums = spark.createDataset(Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8), Encoders.INT());
LongAccumulator longAccumulator = spark.sparkContext().longAccumulator("AccumulatorSubtraction"); nums.foreach(x -> {
if (x % 3 == 0) {
longAccumulator.add(-2);
} else {
longAccumulator.add(1);
}
});
System.out.println("longAccumulator: " + longAccumulator.value()); // 2 } }
相关资料:
1. Accumulators
2. When are accumulators truly reliable?
.
Spark笔记之累加器(Accumulator)的更多相关文章
- Spark中自定义累加器Accumulator
1. 自定义累加器 自定义累加器需要继承AccumulatorParam,实现addInPlace和zero方法. 例1:实现Long类型的累加器 object LongAccumulatorPara ...
- spark笔记 环境配置
spark笔记 spark简介 saprk 有六个核心组件: SparkCore.SparkSQL.SparkStreaming.StructedStreaming.MLlib,Graphx Spar ...
- Spark累加器(Accumulator)陷阱及解决办法
累加器(accumulator)是Spark中提供的一种分布式的变量机制,其原理类似于mapreduce,即分布式的改变,然后聚合这些改变.累加器的一个常见用途是在调试时对作业执行过程中的事件进行计数 ...
- Spark笔记——技术点汇总
目录 概况 手工搭建集群 引言 安装Scala 配置文件 启动与测试 应用部署 部署架构 应用程序部署 核心原理 RDD概念 RDD核心组成 RDD依赖关系 DAG图 RDD故障恢复机制 Standa ...
- pyspark中使用累加器Accumulator统计指标
评价分类模型的性能时需要用到以下四个指标 最开始使用以下代码计算,发现代码需要跑近一个小时,而且这一个小时都花在这四行代码上 # evaluate model TP = labelAndPreds.f ...
- spark 笔记 5: SparkContext,SparkConf
SparkContext 是spark的程序入口,相当于熟悉的'main'函数.它负责链接spark集群.创建RDD.创建累加计数器.创建广播变量. ) scheduler.initialize(ba ...
- 大数据学习——spark笔记
变量的定义 val a: Int = 1 var b = 2 方法和函数 区别:函数可以作为参数传递给方法 方法: def test(arg: Int): Int=>Int ={ 方法体 } v ...
- spark 笔记 16: BlockManager
先看一下原理性的文章:http://jerryshao.me/architecture/2013/10/08/spark-storage-module-analysis/ ,http://jerrys ...
- spark 笔记 15: ShuffleManager,shuffle map两端的stage/task的桥梁
无论是Hadoop还是spark,shuffle操作都是决定其性能的重要因素.在不能减少shuffle的情况下,使用一个好的shuffle管理器也是优化性能的重要手段. ShuffleManager的 ...
随机推荐
- 桌面输入法评测报告 之 搜狗拼音输入法vs必应拼音输入法
输入法是电脑用户不可或缺的软件,它几乎无时无刻不陪伴在使用者的身旁.一个优秀的输入法,应该满足客户对使用体验以及效率的需求.我们小队的任务便是对当今最为常用的两种输入法: 搜狗拼音输入法和必应拼音输入 ...
- 2013337朱荟潼 Linux&深入理解计算机系统第七章读书笔记——链接
第七章--链接 0.总结 链接编译时可以采用静态链接或动态链接. 连接器主要任务:符号解析和重定位. 多个目标文件可定义相同的符号,可以被连接到一个单独的静态库. 链接器可以生成部分链接的可执行文件 ...
- 关于Win10系统下VC2013安装Unit test出现问题的解决办法
话不多说,先上图~~~ 很多同学在Vs2013安装Unit test组件时会弹出这样的对话框,极其极其让人崩溃. 当我看到这个对话框时,首先中规中矩的去官网下载.NET(但是我怎么可能没有!游戏环境包 ...
- KindEditor:Ajax提交表单时获取不到HTML内容
当用Ajax提交表单时,KindEditor的内容获取不到,HTML数据获取不了 原因:当ajax提交时,KindEdito的HTML数据还没有同步到表单中来,那怎么去获取HTML数据呢? ----- ...
- NServiceBus官方文档翻译(二)NServiceBus 入门
在这篇教程中我们将学习如何创建一个非常简单的由客户端向服务端发送消息的订单系统.该系统包括三个项目:Client.Server 和 Messages,我们将按照以下步骤来完成这个任务. 创建 Clie ...
- js用currentStyle和getComputedStyle获取css样式(非行间) 兼容ie与火狐
用js的style属性可以获得html标签的样式,但是不能获取非行间样式.那么怎么用js获取css的非行间样式呢?在IE下可以用currentStyle,而在火狐下面我们需要用到getComputed ...
- Mybatis 从入门到精通一:mybatis的入门
1.Mybatis简介 MyBatis 本是apache的一个开源项目iBatis, 2010年这个项目由apache software foundation(阿帕奇软件基金会) 迁移到了google ...
- psql -- PostgreSQL 交互终端
psql -- PostgreSQL 交互终端 用法:psql [option...] [dbname [username]] 描述:psql 是一个以终端为基础的 PostgreSQL 前端.它允 ...
- 还在手动给css加前缀?no!几种自动处理css前缀的方法简介
原文首发于个人博客:还在手动给css加前缀?no!几种自动处理css前缀的方法简介 我们知道在写css的时候由于要兼容不同厂商浏览器,一些比较新的属性需要给它们添加厂商前缀来兼容.移动端还好,基本只要 ...
- #pragma once 与 #ifndef 的使用
为了防止头文件被重复包含,主要有两种方式: 方式一:使用 #ifndef #ifndef OPTIONAL_TEST_H #define OPTIONAL_TEST_H //............. ...