一致性Hash算法说明
- 本文章比较好的说明了一致性Hash算法的概念
- Hash算法一般分为除模求余和一致性Hash
1、除模求余:当新增、删除机器时会导致大量key的移动
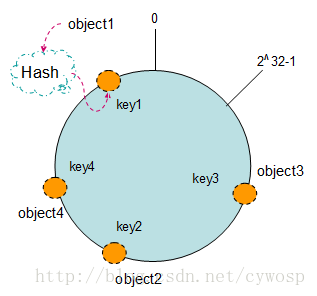
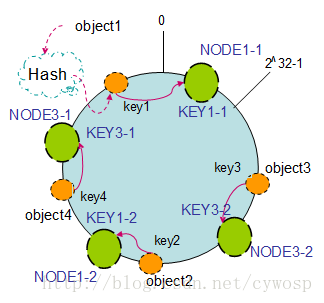
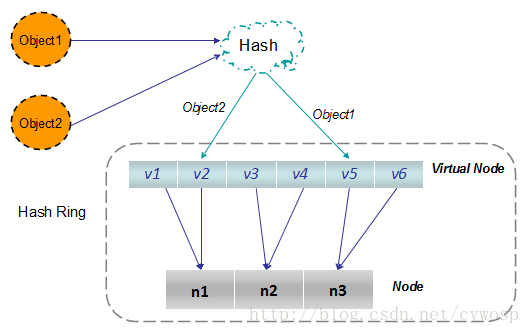
2、一致性Hash:当新增、删除机器时只会影响到附近的key,因为是环状结构
1、平衡性(Balance):平衡性是指哈希的结果能够尽可能分布到所有的缓冲中去,这样可以使得所有的缓冲空间都得到利用。很多哈希算法都能够满足这一条件。
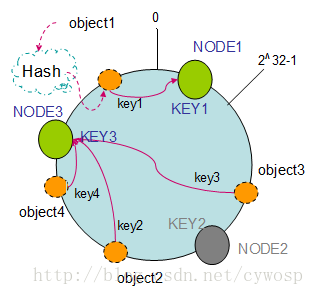
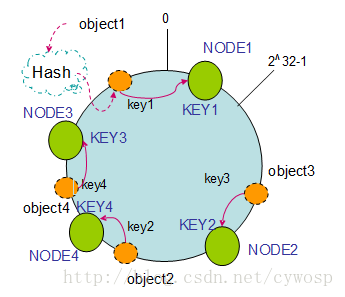
2、单调性(Monotonicity):单调性是指如果已经有一些内容通过哈希分派到了相应的缓冲中,又有新的缓冲加入到系统中。哈希的结果应能够保证原有已分配的内容可以被映射到原有的或者新的缓冲中去,而不会被映射到旧的缓冲集合中的其他缓冲区。
3、分散性(Spread):在分布式环境中,终端有可能看不到所有的缓冲,而是只能看到其中的一部分。当终端希望通过哈希过程将内容映射到缓冲上时,由于不同终端所见的缓冲范围有可能不同,从而导致哈希的结果不一致,最终的结果是相同的内容被不同的终端映射到不同的缓冲区中。这种情况显然是应该避免的,因为它导致相同内容被存储到不同缓冲中去,降低了系统存储的效率。分散性的定义就是上述情况发生的严重程度。好的哈希算法应能够尽量避免不一致的情况发生,也就是尽量降低分散性。
4、负载(Load):负载问题实际上是从另一个角度看待分散性问题。既然不同的终端可能将相同的内容映射到不同的缓冲区中,那么对于一个特定的缓冲区而言,也可能被不同的用户映射为不同 的内容。与分散性一样,这种情况也是应当避免的,因此好的哈希算法应能够尽量降低缓冲的负荷。

一致性Hash算法说明的更多相关文章
- 对一致性Hash算法,Java代码实现的深入研究
一致性Hash算法 关于一致性Hash算法,在我之前的博文中已经有多次提到了,MemCache超详细解读一文中"一致性Hash算法"部分,对于为什么要使用一致性Hash算法.一致性 ...
- 一致性hash算法详解
转载请说明出处:http://blog.csdn.net/cywosp/article/details/23397179 一致性哈希算法在1997年由麻省理工学院提出的一种分布式哈希(DHT) ...
- 一致性hash算法简介
一致性哈希算法在1997年由麻省理工学院提出的一种分布式哈希(DHT)实现算法,设计目标是为了解决因特网中的热点(Hot spot)问题,初衷和CARP十分类似.一致性哈希修正了CARP使用的简单哈希 ...
- 分布式缓存技术memcached学习(四)—— 一致性hash算法原理
分布式一致性hash算法简介 当你看到“分布式一致性hash算法”这个词时,第一时间可能会问,什么是分布式,什么是一致性,hash又是什么.在分析分布式一致性hash算法原理之前,我们先来了解一下这几 ...
- 一致性 hash 算法( consistent hashing )a
一致性 hash 算法( consistent hashing ) 张亮 consistent hashing 算法早在 1997 年就在论文 Consistent hashing and rando ...
- 一致性hash算法简介与代码实现
一.简介: 一致性hash算法提出了在动态变化的Cache环境中,判定哈希算法好坏的四个定义: 1.平衡性(Balance) 2.单调性(Monotonicity) 3.分散性(Spread) 4.负 ...
- memcache的一致性hash算法使用
一.概述 1.我们的memcache客户端(这里我看的spymemcache的源码),使用了一致性hash算法ketama进行数据存储节点的选择.与常规的hash算法思路不同,只是对我们要存储数据的k ...
- 一致性Hash算法在Redis分布式中的使用
由于redis是单点,但是项目中不可避免的会使用多台Redis缓存服务器,那么怎么把缓存的Key均匀的映射到多台Redis服务器上,且随着缓存服务器的增加或减少时做到最小化的减少缓存Key的命中率呢? ...
- 【转载】一致性hash算法释义
http://www.cnblogs.com/haippy/archive/2011/12/10/2282943.html 一致性Hash算法背景 一致性哈希算法在1997年由麻省理工学院的Karge ...
- 一致性Hash算法在Memcached中的应用
前言 大家应该都知道Memcached要想实现分布式只能在客户端来完成,目前比较流行的是通过一致性hash算法来实现.常规的方法是将server的hash值与server的总台数进行求余,即hash% ...
随机推荐
- Java基础84 javaBean规范
1.javaBean的概述 1.javaBeam(咖啡豆)是一种开发规范,也可以说是一种技术. 2.JavaBean就是一个普通java类,只要符合以下规定才能称作为javaBean: ...
- CentOS6下Jenkins连接Git服务器出错的问题
今天研究GitLab+Jenkins自动集成时,出现Failed to connect to repository : Command "git config --local credent ...
- 如何使用 Java 删除 ArrayList 中的重复元素
如何使用 Java 删除 ArrayList 中的重复元素 (How to Remove Duplicates from ArrayList in Java) Given an ArrayList w ...
- node.js之nodemon 代码热更新 修改代码后服务器自动重启
1.安装nodemon: npm install -g nodemon //全局安装 npm install nodemon --save //局部安装 2.在项目根目录下创建 nodemon.jso ...
- Qt判断网络是否在
我们已知的网络连接有3种:拨号.使用局域网以及代理上网. 无论哪一种上网方式都可以判断网络是否畅通,借此,我们来做一个判断网络是否畅通(存在)的程序,新建一个基类为QWidget的工程,不要UI. 添 ...
- 链表用途&&数组效率&&链表效率&&链表优缺点
三大数据结构的实现方式 数据结构 实现方式 栈 数组/单链表 队列 数组/双端链表 优先级队列 数组/堆/有序链表 双端队列 双向链表 数组与链表实现方式的比较 数组与链表都很快 如果能精确预测栈 ...
- Android-Binder原理浅析
Android-Binder原理浅析 学习自 <Android开发艺术探索> 写在前头 在上一章,我们简单的了解了一下Binder并且通过 AIDL完成了一个IPC的DEMO.你可能会好奇 ...
- UOJ.26.[IOI2014]Game(交互 思路)
题目链接 \(Description\) 有一张\(n\)个点的图.M每次询问\((u,v)\),你需要回答图中\((u,v)\)间是否有边.如果M可以用\(<n(n-1)/2\)次询问确定图中 ...
- BZOJ.2595.[WC2008]游览计划(DP 斯坦纳树)
题目链接 f[i][s]表示以i为根节点,当前关键点的连通状态为s(每个点是否已与i连通)时的最优解.i是枚举得到的根节点,有了根节点就容易DP了. 那么i为根节点时,其状态s的更新为 \(f[i][ ...
- 吴恩达-coursera-机器学习-week9
十五.异常检测(Anomaly Detection) 15.1 问题的动机 15.2 高斯分布 15.3 算法 15.4 开发和评价一个异常检测系统 15.5 异常检测与监督学习对比 15.6 选择特 ...