[Spark Core] Spark 核心组件
0. 说明
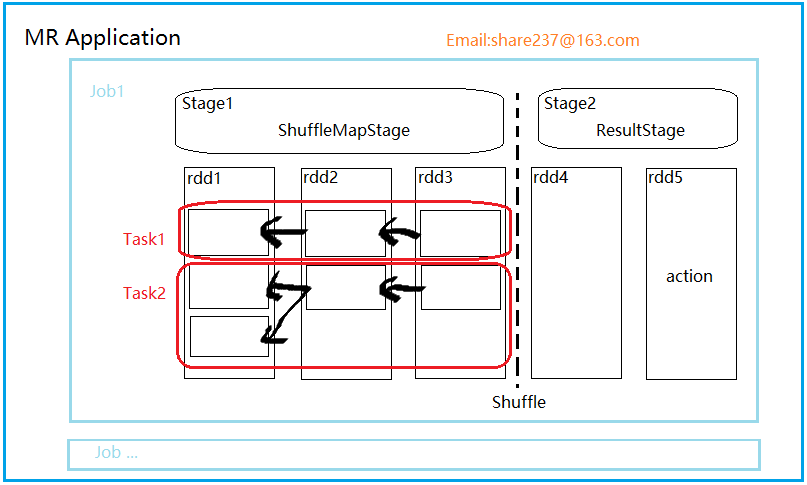
【Spark 核心组件示意图】
1. RDD
resilient distributed dataset , 弹性数据集
轻量级的数据集合,逻辑上的集合。等价于 list
没有携带数据。
2. 依赖
RDD 的依赖是 子 RDD 上的每个分区和父 RDD 分区数量上的对应关系
Dependency
|----ShuffleDependency (宽依赖)
|----NarrowDependency (窄依赖:子 RDD 的每个分区依赖少量的父 RDD 分区)
|-----One2OneDependency (一对一依赖)
|-----RangeDependency(范围依赖)
|-----PruneDependency(Prune 依赖)
3. Stage(阶段)
并行的 task 集合,同一 Stage 的所有任务有着相同的 Shuffle 依赖。
阶段,一组RDD构成的链条。
阶段的划分按照 Shuffle 标记来进行的。
阶段类型有两种,ShuffleMapStage 和ResultStage。
【ShuffleMapStage】
该阶段任务的结果是下一个阶段任务的输入。需要跟踪每个分区所在的节点。
任务执行期间的中间过程,保存task的输出数据供下一个 reduce 进行 fetch(抓取) 。
该阶段可以单独提交。
【 ResultStage】
结果结果直接执行 RDD 的 action 操作。
对一些分区应用计算函数(不一定需要在所有分区进行计算,比如说first())。
最后一个阶段,执行task后的结果回传给driver
4. Task
task 是 Spark 执行单位,有两种类型。
【ShuffelMapTask】
在 ShuffleMapStage 由多个 ShuffleMapTask 组成。
【ResultTask】
ResultStage 由多个 ResultTask 组成,结果任务直接 task 后,将结果回传给 driver。
driver:
5. job
一个 action 就是一个 job
6. Application
一个应用可以包含多个 job
7. Spark Context
Spark 上下文是 Spark 程序的主入口点,表示到 Spark 集群的连接。可以创建 RDD 、累加器和广播变量。
每个 JVM 只能有一个 active 的上下文,如果要创建新的上下文,必须将原来的上下文 stop。
sc.textFile("");
sc.parallelize(1 to 10);
sc.makeRDD(1 to 10) ; //通过parallelize实现。
[Spark Core] Spark 核心组件的更多相关文章
- 大数据技术之_27_电商平台数据分析项目_02_预备知识 + Scala + Spark Core + Spark SQL + Spark Streaming + Java 对象池
第0章 预备知识0.1 Scala0.1.1 Scala 操作符0.1.2 拉链操作0.2 Spark Core0.2.1 Spark RDD 持久化0.2.2 Spark 共享变量0.3 Spark ...
- [Spark Core] Spark Client Job 提交三级调度框架
0. 说明 官方文档 Job Scheduling Spark 调度核心组件: DagScheduler TaskScheduler BackendScheduler 1. DagSchedule ...
- [Spark Core] Spark 使用第三方 Jar 包的方式
0. 说明 Spark 下运行job,使用第三方 Jar 包的 3 种方式. 1. 方式一 将第三方 Jar 包分发到所有的 spark/jars 目录下 2. 方式二 将第三方 Jar 打散,和我们 ...
- 【待补充】[Spark Core] Spark 实现标签生成
0. 说明 在 IDEA 中编写 Spark 代码实现将 JSON 数据转换成标签,分别用 Scala & Java 两种代码实现. 1. 准备 1.1 pom.xml <depend ...
- [Spark Core] Spark 在 IDEA 下编程
0. 说明 Spark 在 IDEA 下使用 Scala & Spark 在 IDEA 下使用 Java 编写 WordCount 程序 1. 准备 在项目中新建模块,为模块添加 Maven ...
- [Spark Core] Spark 实现气温统计
0. 说明 聚合气温数据,聚合出 MAX . MIN . AVG 1. Spark Shell 实现 1.1 MAX 分步实现 # 加载文档 val rdd1 = sc.textFile(" ...
- [Spark Core] Spark Shell 实现 Word Count
0. 说明 在 Spark Shell 实现 Word Count RDD (Resilient Distributed dataset), 弹性分布式数据集. 示意图 1. 实现 1.1 分步实现 ...
- Spark 3.x Spark Core详解 & 性能优化
Spark Core 1. 概述 Spark 是一种基于内存的快速.通用.可扩展的大数据分析计算引擎 1.1 Hadoop vs Spark 上面流程对应Hadoop的处理流程,下面对应着Spark的 ...
- Spark Streaming揭秘 Day35 Spark core思考
Spark Streaming揭秘 Day35 Spark core思考 Spark上的子框架,都是后来加上去的.都是在Spark core上完成的,所有框架一切的实现最终还是由Spark core来 ...
随机推荐
- PHP算法------排序
<?php/** * Created by PhpStorm. * User: 63448 * Date: 2018/5/5 * Time: 22:42 */$arr = [3,1,13,5,7 ...
- 状态压缩·一(状态压缩DP)
描述 小Hi和小Ho在兑换到了喜欢的奖品之后,便继续起了他们的美国之行,思来想去,他们决定乘坐火车前往下一座城市——那座城市即将举行美食节! 但是不幸的是,小Hi和小Ho并没有能够买到很好的火车票—— ...
- 基于spring boot的定时器
首先,搭建好一个springboot项目 方法一:通过springboot自带入口来开启定时器. 首先我们都知道,springboot有一个自己的入口,也就是@SpringBootApplicatio ...
- C# - 企业框架下的存储过程输出参数
output 输出参数 在C# 中的获取方法 新建存储过程 create proc Test @ID int, @maxnum int output as begin declare @num int ...
- Java基础知识你知道多少?
Java虚拟机基础知识你知道多少? Java并发基础知识你知道多少? Java数据结构基础知识你知道多少? java序列化与反序列化 https://github.com/zhantong/inter ...
- 理解JVM之垃圾收集器详解
前言 垃圾收集器作为内存回收的具体表现,Java虚拟机规范并未对垃圾收集器的实现做规定,因而不同版本的虚拟机有很大区别,因而我们在这里主要讨论基于Sun HotSpot虚拟机1.6版本Update22 ...
- Code Signal_练习题_chessBoardCellColor
Given two cells on the standard chess board, determine whether they have the same color or not. Exam ...
- CSS十大选择器
CSS十大选择器: 1.id选择器 # 2.class选择器 句号 . 3.标签选择器 标签名称 4.相邻选择器 加号 + 5.后代选择器 空格 6.子元素选择器 大于号 > 7.多元素 ...
- 更改Outlook 2013中Exchange数据文件存放路径
昨天新入职目前所在的公司,在原公司一直都是直接使用Outlook设置用户名和密码后,然后将*.pst邮件的数据文件保存在其他盘符,以防止在更新操作系统时出现邮件丢失的情况:但是目前公司使用的是Exch ...
- openCV 扩图
1.扩图 import cv2 import numpy as np img=cv2.imread('Test2.jpg',1) width=img.shape[0] height=img.shape ...