oracle第一天笔记
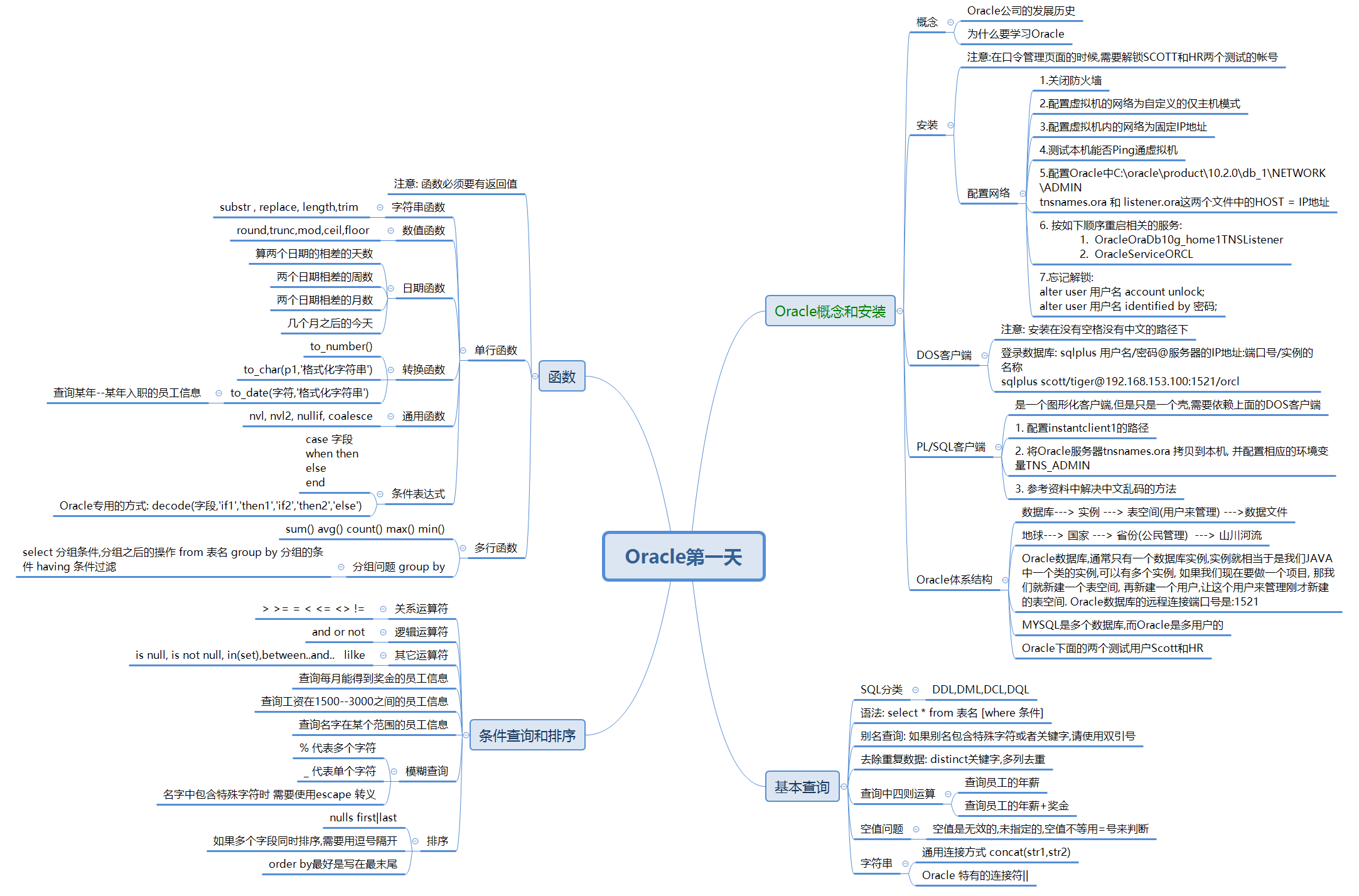
Oracle体系结构:
- 数据库 ----> 实例(orcl) ---> 表空间(逻辑单位)(用户) ---> 数据文件(物理单位)
- 地球 ----> 国家 ---> 省份(省长,公民) ---> 中粮,山川河流
Oracle和mysql区别:
收费, 不开源
Oracle特有的方言/特有的语法
安全级别高
假设要做一个项目:
mysql : 新建一个数据库
Oracle : 新建一个表空间,指定一个用户,让这个用去去创建相应的表
mysql : 多数据库
Oracle : 多用户操作 ,所有的表都是放在用户下面
Oracle是多用户的, MYSQL是多数据库的
1. 遵循SQL标准
2. 不同厂商,不同的数据库产品,但是有自己的方言
3. 使用自己的方言,也能够完成相同的功能
4. Oracle安全级别要高,MYSQL开源免费
基本查询操作
SQL分类:
DDL: 数据定义语言,定义的表的结构 , create , alter, drop ,truncate
DML: 数据操纵语言, 操纵表中数据 , insert , update, delete
DCL: 数据控制语言, 控制一些安全级别, 授权,取消授权 grant revoke
DQL: 数据查询语言, 查询数据 , select , from , where
查询语句的结构:
select [列名] [*] from 表名 [where 条件] [group by 分组条件] [having 过滤] [order by 排序]
select * from emp; select 1+1; --在Oracle等于报错 ,在MYSQL中输出结果是2 /*
dual : oracle中的虚表 ,伪表, 主要是用来补齐语法结构 */
select 1+1 from dual; select * from dual; select 1 from emp;
--直接写一个常量比写 * 要高效
select count(1) from emp;
select count(*) from emp; /*
别名查询: 使用as 关键字, 可以省略
别名中不能有特殊字符或者关键字, 如果有就加双引号 */
select ename 姓名, sal 工资 from emp; select ename "姓 名", sal 工资 from emp; /*
去除重复数据 distinct
多列去除重复: 每一列都一样才能够算作是重复
*/
--单列去除重复
select distinct job from emp; --多列去除重复的
select distinct job,deptno from emp;
四则运算: + - * /
select 1+1 from dual; --查询员工年薪 = 月薪* 12
select sal*12 from emp; --查询员工年薪+奖金
select sal*12 + comm from emp;
--nvl 函数 : 如果参数1为null 就返回参数2
select sal*12 + nvl(comm,0) from emp; /*
注意: null值 , 代表不确定的 不可预知的内容 , 不可以做四则运算
*/
字符串拼接
/*
字符串拼接:
java : + 号拼接
Oracle 特有的连接符: || 拼接 在Oracle 中 ,双引号主要是别名的时候使用, 单引号是使用的值, 是字符 concat(str1,str2) 函数, 在mysql和Oracle中都有
*/
--查询员工姓名 : 姓名:SCOTT
select ename from emp;
--使用拼接符
select '姓名:' || ename from emp; --使用函数拼接
select concat('姓名:',ename) from emp;
条件查询
/*
条件查询 : [where后面的写法]
关系运算符: > >= = < <= != <>
逻辑运算符: and or not
其它运算符:
like 模糊查询
in(set) 在某个集合内
not in :
like : 模糊查询
exists(查询语句) : 存在的意思
between..and.. 在某个区间内
is null 判断为空
is not null 判断不为空
*/
--查询每月能得到奖金的员工信息
select * from emp where comm is not null; --查询工资在1500--3000之间的员工信息
select * from emp where sal between 1500 and 3000; select * from emp where sal >= 1500 and sal <= 3000; --查询名字在某个范围的员工信息 ('JONES','SCOTT','FORD') in
select * from emp where ename in ('JONES','SCOTT','FORD'); _ 匹配单个字符 如果有特殊字符, 需要使用escape转义
*/
/*
模糊查询: like
% 匹配多个字符
--查询员工姓名第三个字符是O的员工信息
select * from emp where ename like '__O%'; 两个横线_ _ --查询员工姓名中,包含%的员工信息
select * from emp where ename like '%\%%' escape '\'; 转义 select * from emp where ename like '%#%%' escape '#'; 转义
排序操作
/*
排序 : order by
升序: asc ascend
降序: desc descend 排序注意null问题 : nulls first | last 同时排列多列, 用逗号隔开
*/
--查询员工信息,按照奖金由高到低排序
select * from emp order by comm desc nulls last; --查询部门编号和按照工资 按照部门升序排序, 工资降序排序
select deptno, sal from emp order by deptno asc, sal desc;
函数
/*
函数: 必须要有返回值 单行函数: 对某一行中的某个值进行处理
数值函数
字符函数
日期函数
转换函数
通用函数 多行函数: 对某一列的所有行进行处理
max() min count sum avg 1.直接忽略空值
*/
--统计员工工资总和
select sum(sal) from emp; --统计员工奖金总和 2200
select sum(comm) from emp; --统计员工人数 14
select count(1) from emp; --统计员工的平均奖金 550 错误 2200/14 =
select avg(comm) from emp; --统计员工的平均奖金 157.
select sum(comm)/count(1) from emp;
select ceil(sum(comm)/count(1)) from emp; update emp set ename = 'TUR%NER' where ename = 'TURNER'; select * from emp; --数值函数
select ceil(45.926) from dual; --
select floor(45.926) from dual; --
--四舍五入
select round(45.926,2) from dual; --45.93
select round(45.926,1) from dual; -- 45.9
select round(45.926,0) from dual; --
select round(45.926,-1) from dual; --
select round(45.926,-2) from dual; --
select round(65.926,-2) from dual; -- --截断
select trunc(45.926,2) from dual; --45.92
select trunc(45.926,1) from dual; -- 45.9
select trunc(45.926,0) from dual; --
select trunc(45.926,-1) from dual; --
select trunc(45.926,-2) from dual; --
select trunc(65.926,-2) from dual; -- --求余
select mod(9,3) from dual; --
select mod(9,4) from dual; -- --字符函数
-- substr(str1,起始索引,长度)
--注意: 起始索引不管写 0 还是 1 都是从第一个字符开始截取
select substr('abcdefg',0,3) from dual; --abc
select substr('abcdefg',1,3) from dual; --abc select substr('abcdefg',2,3) from dual; --bcd --获取字符串长度 24 28
select length('abcdefg') from dual; --去除字符左右两边的空格
select trim(' hello ') from dual; --替换字符串
Select replace('hello','l','a') from dual; --日期函数
--查询今天的日期
select sysdate from dual;
--查询3个月后的今天的日期
select add_months(sysdate,3) from dual;
--查询3天后的日期
select sysdate + 3 from dual; --查询员工入职的天数
select sysdate - hiredate from emp; select ceil(sysdate - hiredate) from emp; --查询员工入职的周数
select (sysdate - hiredate)/7 from emp; --查询员工入职的月数
select months_between(sysdate,hiredate) from emp; --查询员工入职的年份
select months_between(sysdate,hiredate)/12 from emp; --转换函数 数值转字符 字符转数值 日期
--字符转数值 to_number(str) 鸡肋
select 100+'' from dual; --110 默认已经帮我们转换
select 100 + to_number('') from dual; -- --数值转字符
select to_char(sal,'$9,999.99') from emp; select to_char(sal,'L9,999.99') from emp;
/*
to_char(1210.73, '9999.9') 返回 '1210.7'
to_char(1210.73, '9,999.99') 返回 '1,210.73'
to_char(1210.73, '$9,999.00') 返回 '$1,210.73'
to_char(21, '000099') 返回 '000021'
to_char(852,'xxxx') 返回' 354' */ --日期转字符 to_char() 不区分大小写 注意分钟是mi
select to_char(sysdate,'yyyy-mm-dd hh:mi:ss') from dual;
select to_char(sysdate,'yyyy-mm-dd hh24:mi:ss') from dual;
--只想要年
select to_char(sysdate,'yyyy') from dual; -- --只想要日
select to_char(sysdate,'d') from dual; --2 代表一个星期中第几天
select to_char(sysdate,'dd') from dual; --10 代表一个月中的第几天
select to_char(sysdate,'ddd') from dual; --100 代表一年中的第几天 select to_char(sysdate,'day') from dual; --monday
select to_char(sysdate,'dy') from dual; --mon 星期的简写 --字符转日期
select to_date('2017-04-10','yyyy-mm-dd') from dual; --查询1981年 -- 1985年入职的员工信息
select * from emp where hiredate between to_date('','yyyy') and to_date('','yyyy'); /*
通用函数:
nvl(参数1,参数2) 如果参数1 = null 就返回参数2
nvl2(参数1,参数2,参数3) 如果参数1 = null ,就返回参数3, 否则返回参数2 nullif(参数1,参数2) 如果参数1 = 参数2 那么就返回 null , 否则返回参数1 coalesce: 返回第一个不为null的值
*/
select nvl2(null,5,6) from dual; --6; select nvl2(1,5,6) from dual; --5; select nullif(5,6) from dual; --
select nullif(6,6) from dual; --null select coalesce(null,null,3,5,6) from dual; -- select ceil(-12.5) from dual; --
select floor(12.5) from dual; --
分组查询
group by 分组条件
select 分组的条件,分组之后的操作 from 表名 group by 分组的条件 [having 条件过滤]
where | having
where 是在分组之前执行,不能接聚合函数,可以接单行函数
having 分组之后执行, 可以接聚合函数
SQL编写顺序:
select..from..where..group by ..having .. order by ..
SQL执行顺序:
from..where..group by..having..select..order by..
-- 查询部门的平均工资,并且过滤平均工资大于2000的部门
-- 1.统计所有部门的平均工资
select deptno,avg(sal) from emp group by deptno ;
--2 .条件过滤
select deptno,avg(sal) from emp group by deptno having avg(sal)>2000;
连接查询
*/
/*
笛卡尔积 :没有实际意义,两张表的乘积
*/
select * from emp;
select * from dept; select * from emp,dept;
/*
内连接 : 等值内连接/隐式内连接
不等值内连接
显式内连接 :
.. inner join.. on 连接的条件
*/
-- 隐式内连接
select * from emp e,dept d where e.deptno = d.deptno; select * from emp e,dept d where e.deptno != d.deptno; --显式内连接 , inner 可以省略
select * from emp e inner join dept d on e.deptno = d.deptno;
select * from emp e join dept d on e.deptno = d.deptno; -- on 执行顺序 比 where 靠前
-- emp , dept 生成的一张中间表,先生成的笛卡尔积,再使用 where 条件过滤
-- on 带着条件生成结果 /*
自连接: 自己连接自己
*/
-- 查询员工的编号,姓名,经理编号,经理姓名
select e1.empno,e1.ename "员工姓名",e1.mgr,m1.ename "经理姓名" from emp e1,emp m1 where e1.mgr=m1.empno; -- 查询员工的编号,员工姓名,员工的部门名称,经理编号,经理姓名,经理部门名称
select e1.empno,e1.ename ,d1.dname ,e1.mgr,m1.ename ,d2.dname
from emp e1,emp m1 ,dept d1,dept d2
where e1.mgr=m1.empno and e1.deptno = d1.deptno and m1.deptno = d2.deptno; -- 查询员工的编号,员工姓名,员工的部门名称,工资等级,经理编号,经理姓名,经理部门名称,经理的工资等级
select e1.empno,e1.ename ,d1.dname ,s1.grade ,e1.mgr,m1.ename ,d2.dname,s2.grade
from emp e1,emp m1 ,dept d1,dept d2,salgrade s1,salgrade s2
where
e1.mgr=m1.empno
and e1.deptno = d1.deptno
and m1.deptno = d2.deptno
and e1.sal between s1.losal and s1.hisal
and m1.sal between s2.losal and s2.hisal
; -- 查询员工的编号,员工姓名,员工的部门名称,工资等级(中文),经理编号,经理姓名,经理部门名称,经理的工资等级(中文)
select
e1.empno,
e1.ename "员工姓名",
d1.dname ,
case s1.grade
when 1 then '一级'
when 2 then '二级'
when 3 then '三级'
when 4 then '四级'
when 5 then '五级'
else
'超级'
end "员工工资等级",
e1.mgr,
m1.ename ,
d2.dname,
decode(s2.grade,1,'一级',2,'二级',3,'三级',4,'四级',5,'五级','超级') "经理工资等级" #decode函数解释from emp e1,emp m1 ,dept d1,dept d2,salgrade s1,salgrade s2
where
e1.mgr=m1.empno
and e1.deptno = d1.deptno
and m1.deptno = d2.deptno
and e1.sal between s1.losal and s1.hisal
and m1.sal between s2.losal and s2.hisal
; /*
外连接查询:
左外连接: 以左表为基础将,左表中所有的记录都查询出来,如果右表没有对应的记录,用null填充
右外连接: 以右表为基础将,右表中所有的记录都查询出来,如果左表没有对应的记录,用null填充
left outer join .. on
right outer join ..on
outer 可以省略 Oracle特有的写法 (+) + 的是null 如果没有对应的记录,就用null填充 */
-- 左外连接
select * from emp e left outer join dept d on e.deptno = d.deptno; select * from emp e,dept d where e.deptno = d.deptno(+); -- 右外连接
select * from emp e right outer join dept d on e.deptno = d.deptno; select * from emp e,dept d where e.deptno(+) = d.deptno; insert into emp(empno,ename) values(9527,'huaan');
delete from emp where empno=9527; select * from salgrade; /*
子查询: 查询语句中嵌套查询语句
解决一些复杂的查询需求 按照行列划分:
单行子查询: 查询出来结果只有一行
操作符:
> >= = < <= != <> 多行子查询: 查询出来的结果有多行
操作符:
in
not in
any 任何/任意
all 所有
exists 存在的意思 按照出现的位置:
select
from
where
having
*/
-- 查询工资最高的员工信息
-- 1.查询最高工资是多少 5000
select max(sal) from emp;
-- 2. 看谁的工资等于最高工资
select * from emp where sal = 5000;
select * from emp where sal = (select max(sal) from emp); -- 查询出比雇员7654的工资高,同时 和7788从事相同工作的员工信息
-- 1.雇员7654的工资 1250
select sal from emp where empno=7654;
-- 2. 7788从事的工作 ANALYST
select job from emp where empno = 7788;
-- 3. 结果:
select * from emp where sal > (select sal from emp where empno=7654) and job=(select job from emp where empno = 7788); -- 查询每个部门最低工资的员工信息和他所在的部门信息
-- 1. 每个部门最低工资
select deptno,min(sal) minsal from emp group by deptno; select *
from
emp e1,
(select deptno,min(sal) minsal from emp group by deptno) t1
where e1.deptno = t1.deptno and e1.sal = t1.minsal; -- 2.连接部门表,查询信息
select *
from
emp e1,
(select deptno,min(sal) minsal from emp group by deptno) t1,
dept d1
where
e1.deptno = t1.deptno
and e1.sal = t1.minsal
and e1.deptno = d1.deptno; -- 查询是领导的员工信息
-- 1. 得到所有经理的编号 int i=3 int j =4 i = j
select distinct mgr from emp where mgr is not null; -- (7839,7782,7698)
-- 2. 结果:
select * from emp where empno in(select distinct mgr from emp); -- 查询不是领导的员工信息
select * from emp where empno not in(select distinct mgr from emp where mgr is not null );
select * from emp where empno <>all(select distinct mgr from emp where mgr is not null ); /*
exists(查询语句) : 存在的意思
如果查询语句,有结果,则返回true
否则返回false exists 和 in 通常可以替换使用
建议使用exists 效率高, 数据量很大的时候
*/
select * from emp where exists(select * from emp where empno = 1234567);
select * from emp where 1=2; select * from emp where exists(select * from emp where empno=7369);
select * from emp where 1=1; -- 查询有员工的部门信息
select * from dept d1 where exists(select * from emp e1 where e1.deptno = d1.deptno); -- Select接子查询
-- 获取员工的名字和部门的名字
select ename,deptno from emp; select ename,(select dname from dept d1 where e1.deptno = d1.deptno) from emp e1;
-- from后面接子查询
-- 查询emp表中经理信息
--1. 查询经理的编号
select distinct mgr from emp where mgr is not null; -- 2.结果
select * from ( select distinct mgr from emp where mgr is not null) m1, emp e1 where m1.mgr = e1.empno; -- where 接子查询
-- 薪资高于10号部门平均工资的所有员工信息
-- 1. 10号部门平均工资 2916
select avg(sal) from emp where deptno = 10;
-- 2.结果
select * from emp where sal > (select avg(sal) from emp where deptno = 10);
-- having后面接子查询
-- 有哪些部门的平均工资高于30号部门的平均工资
-- 1.30号部门的平均工资 1566
select avg(sal) from emp where deptno = 30;
-- 2. 分组统计每个部门的平均工资
select deptno,avg(sal) from emp group by deptno;
--3. 结果:
select deptno,avg(sal) from emp group by deptno having avg(sal) > (select avg(sal) from emp where deptno = 30); -- 找到员工表中工资最高的前三名
/*
rownum : 伪列 , 是Oracle提供一个代表每行记录的序号
rownum 默认值从1 开始, 每查询出一条记录, 就加 1 SQL执行顺序:
from..where..group by..having..select.. rownum ..order by..
*/ select rownum,emp.* from emp; select rownum,emp.* from emp order by sal; select rownum,emp.* from emp where rownum >4; --没有任何记录 select rownum,emp.* from emp where rownum >=1; --14条记录 select rownum,emp.* from emp where rownum <4; --排序 sal
select emp.* from emp order by sal desc; select rownum,t1.* from (select emp.* from emp order by sal desc) t1; select rownum,t1.* from (select emp.* from emp order by sal desc) t1 where rownum < 4; --找到员工表中薪水大于本部门平均薪水的员工
-- 1. 分组统计每个部门的平均工资
select deptno , avg(sal) avgsal from emp group by deptno; -- 2. 结果:
select *
from
emp e1,
(select deptno , avg(sal) avgsal from emp group by deptno) t1
where e1.deptno = t1.deptno and e1.sal > t1.avgsal; --统计每年入职员工的个数
select hiredate from emp; select to_char(hiredate,'yyyy') from emp; select to_char(hiredate,'yyyy'),count(1) from emp group by to_char(hiredate,'yyyy'); select to_char(hiredate,'yyyy') aa,count(1) cc from emp group by to_char(hiredate,'yyyy'); -- 1. 将1987竖起来 case when end
select case aa when '' then cc end "1987"
from
(select to_char(hiredate,'yyyy') aa,count(1) cc from emp group by to_char(hiredate,'yyyy')) tt; -- 2. 去除所有的null
select sum(case aa when '' then cc end) "1987"
from
(select to_char(hiredate,'yyyy') aa,count(1) cc from emp group by to_char(hiredate,'yyyy')) tt; -- 3. 计算total
select sum(cc) "Total"
from
(select to_char(hiredate,'yyyy') aa,count(1) cc from emp group by to_char(hiredate,'yyyy')) tt; --4. Total 和 1987 拼接起来
select
sum(cc) "Total",
sum(case aa when '' then cc end) "1987"
from
(select to_char(hiredate,'yyyy') aa,count(1) cc from emp group by to_char(hiredate,'yyyy')) tt; --5. 所有的结果
select
sum(cc) "Total",
sum(case aa when '' then cc end) "1980",
sum(case aa when '' then cc end) "1981",
sum(case aa when '' then cc end) "1982",
sum(case aa when '' then cc end) "1987"
from
(select to_char(hiredate,'yyyy') aa,count(1) cc from emp group by to_char(hiredate,'yyyy')) tt; /*
rowid : 伪列, 代表的是每条记录在磁盘上所存放的真实的位置/物理地址
运用在索引查询的时候 rownum : 伪列, 代表的是行号
主要是在Oracle分页操作的时候使用
*/
select rownum,emp.* from emp; select rowid,emp.* from emp; -- 0x1001 select rowid,emp.* from emp order by sal desc; -- 查询表中第5-10条记录
-- 1.查询前10条记录
select rownum hanghao,e1.* from emp e1 where rownum <=10; select rownum hanghao,e1.* from emp e1; -- 2. 查询第5-10的记录
select *
from
(select rownum hanghao,e1.* from emp e1 where rownum <=10) t1
where hanghao >=5; -- rowid -- 华为的笔试题 : 去除表中重复的记录
create table tt(
tname varchar2(10)
); insert into tt values('aa');
insert into tt values('bb');
insert into tt values('cc'); select rowid,tt.* from tt;
-- 查询的时候去除重复
select distinct tname from tt; -- 删除表中重复的记录,保留rowid最小的记录
delete from tt t1 where rowid >(select min(rowid) from tt t2 where t1.tname = t2.tname ); select * from tt; select * from emp;
select * from dept; /*
集合运算: 将多个查询合并,差集, 交集
数据有可能来自于不同表 员工表, 经理表 姓名, 婚否 查询本公司所有人的婚姻状况 */
-- 并集运算: 将两个查询结果合并在一起
-- 工资大于1500,或者20号部门下的员工
select * from emp where sal > 1500 or deptno =20; -- 工资大于1500
select * from emp where sal > 1500; -- 20号部门下的员工
select * from emp where deptno = 20; select * from emp where sal > 1500
union
select * from emp where deptno = 20; select * from emp where sal > 1500
union all
select * from emp where deptno = 20; -- 交集运算 : 两个集合相交的部分, 共有的部分
-- 工资大于1500,或者20号部门下的员工
select * from emp where sal > 1500
intersect
select * from emp where deptno = 20; -- 差集运算 : 一个集合减去另外一个集合
-- 工资大于1500,不是20号部门下的员工
select * from emp where sal > 1500
minus
select * from emp where deptno = 20; /*
集合运算的注意事项:
1. 列的出现顺序要一致
2. 列的数量要一致
3. 如果列数不够,null来凑或者使用相同类型的数来凑
*/
select ename,sal from emp where sal > 1500
union
select ename,sal from emp where deptno = 20; -- 出现的顺序要一致 错误
select ename,sal from emp where sal > 1500
union
select sal,ename from emp where deptno = 20; --
select ename,sal from emp where sal > 1500
union
select ename,0 from emp where deptno = 20; select ename,sal from emp where sal > 1500
union
select ename,null from emp where deptno = 20; -- 统计 薪资 大于 薪资最高的员工 所在部门 的平均工资 和 薪资最低的员工 所在部门 的平均工资 的平均工资 的员工信息。
-- sal > 10 100 20 50 75
-- sal > 75 的员工信息 -- 有两个及以上直接下属的员工信息
-- 1.统计mgr的出现的次数
select mgr from emp; select mgr,count(1) from emp where mgr is not null group by mgr; select mgr,count(1) from emp where mgr is not null group by mgr having count(1)>=2; select mgr from emp where mgr is not null group by mgr having count(1)>=2; select * from emp where empno in(select mgr from emp where mgr is not null group by mgr having count(1)>=2)
oracle第一天笔记的更多相关文章
- Oracle RAC学习笔记:基本概念及入门
Oracle RAC学习笔记:基本概念及入门 2010年04月19日 10:39 来源:书童的博客 作者:书童 编辑:晓熊 [技术开发 技术文章] oracle 10g real applica ...
- Oracle EBS应用笔记整理 (转自IT++ flyingkite)
***************************************************** Author: Flyingkite Blog: http://space.itpub. ...
- Oracle基础学习笔记
Oracle基础学习笔记 最近找到一份实习工作,有点头疼的是,有阶段性考核,这...,实际想想看,大学期间只学过数据库原理,并没有针对某一数据库管理系统而系统的学习,这正好是一个机会,于是乎用了三天时 ...
- Oracle 第一天
Oracle 第一天 1.oracle数据库下载.安装和配置 1.1 下载压缩包后解压并将压缩包2里面的文件覆盖至压缩包1中 1.2 按照步骤逐步安装 1.3 设置管理员密码时,默认情况下四个管理员是 ...
- EntityFramework CodeFirst SQLServer转Oracle踩坑笔记
接着在Oracle中使用Entity Framework 6 CodeFirst这篇博文,正在将项目从SQLServer 2012转至Oracle 11g,目前为止遇到的问题在此记录下. SQL Se ...
- Oracle第一天
Oracle第一天 v3.1 整体安排(3天) 第一天:Oracle的安装配置(服务端和客户端),SQL增强(单表查询). 第二天:SQL增强(多表查询.子查询.伪列-分页),数据库对象(表.约束.序 ...
- Oracle RAC学习笔记01-集群理论
Oracle RAC学习笔记01-集群理论 1.集群相关理论概述 2.Oracle Clusterware 3.Oracle RAC 原理 写在前面: 最近一直在看张晓明的大话Oracle RAC,真 ...
- Oracle RAC学习笔记02-RAC维护工具集
Oracle RAC学习笔记02-RAC维护工具集 RAC维护工具集 1.节点层 2.网络层 3.集群层 4.应用层 本文实验环境: 10.2.0.5 Clusterware + RAC 11.2.0 ...
- [Oracle]OWI学习笔记--001
[Oracle]OWI学习笔记--001 在 OWI 的概念里面,最为重要的是 等待事件 和 等待时间. 等待事件发生时,需要通过 P1,P2,P3 查看具体的资源. 可以通过 v$session_w ...
随机推荐
- Jmeter(三)Test-Plan、Thread-Group
思量再三,还是再记一会,看到技术群里边的讨论,真的是压力山大,学习一刻也不能耽搁.继续来回顾Jmeter的知识吧. Test-Plan,是所有Jmeter脚本的根节点,Test-Plan中包含名称.注 ...
- [UE4]使用C++重写蓝图,SpawnObject根据类型动态创建UObject
先大量使用蓝图制作项目,后续再用C++把复杂的蓝图重写一遍,用C++代码按照蓝图依葫芦画瓢就可以了,很简单,但需要遵守一些原则: 第一种方法:使用继承 一.创建一个C++类作为蓝图的父类(C++类继承 ...
- [UE4]子弹穿透多个机器人
一.将机器人的碰撞类型改成“OverLap” 二.使用“MultiLineTraceByChannel”这个是可以穿透检测,可以检测到多个物体(前提是被检测物体的碰撞类型是“OverLap”).“Li ...
- linux系统安装SNMP(可用)
一般我们监控Linux都是通过SSH或Telnet方式,有时候我们不方便通过这两种方式,比如遇到监控端口因为安全原因被封禁.以及SSH需要密钥登录,这都会让监控工具很难直接远程连接.而通过SNMP的方 ...
- linux驱动开发—基于Device tree机制的驱动编写
前言Device Tree是一种用来描述硬件的数据结构,类似板级描述语言,起源于OpenFirmware(OF).在目前广泛使用的Linux kernel 2.6.x版本中,对于不同平台.不同硬件,往 ...
- Python的dict与set
一.dict 其他语言中也称为map,使用键-值(key-value)存储 特点: 具有极快的查找速度:可以直接由key计算出value所在的内存地址,而list采用搜索的方式:dict付出的代价是内 ...
- mysql下有符号数和无符号数的相关问题
最近自己的程序在调用mysql的存储过程传参给smallint类型变量的时候,总是出现out of range value的错误,刚开始用C数值转换方式的二进制位转换思路来思考时,总是觉得没什么问题, ...
- 让MySql支持表情符号(MySQL中4字节utf8字符保存方法)
UTF-8编码有可能是两个.三个.四个字节.Emoji表情是4个字节,而MySQL的utf8编码最多3个字节,所以数据插不进去. 解决方案:将编码从utf8转换成utf8mb4. 1. 修改my.in ...
- python开发学习(元组、字符串、列表、字典深入)
https://www.cnblogs.com/songqingbo/p/5129116.html(转载学习)
- es6(10)--Set,Map(2)
//Map与Array的对比 { let map=new Map(); let array=[]; //增 map.set('t',1); array.push({t:1}); console.inf ...