mysql数据库优化(二)
1.sql防止注入
https://www.cnblogs.com/sevck/p/6733702.html
结果:
C:\Users\ASUS\kuaigong3.6.5\lib\site-packages\pymysql\cursors.py:165: Warning: (1292, 'Truncated incorrect DOUBLE value: \'1 and nickname="AAA1"\'')
(1, 'AAA', None, 1, 1, 0, 'c46529949246a43bb6692943dd82fdb00b62b5115761079d47c6a1dd0b826a1c', 28, None, '155383902971', '15538390298', None, None, 0, '2.0.dev', 0, datetime.datetime(2018, 5, 3, 17, 13, 37), None, 1) 1 and nickname="AAA1"
result = self._query(query)
--- None 1 and nickname="AAA1"
2.尽量批量操作数据库,比如用 事务,减少网络传输损失
3.全文索引
https://blog.csdn.net/zyz511919766/article/details/12780173
个人了解 好像只支持 单词的搜索
body = After you went through a ...
SELECT *
FROM articles WHERE MATCH (body)
AGAINST ('wen*' IN BOOLEAN MODE);
*代表占位符,只有在单词结尾才有用,也就是和like的 ‘serach%’ 一样。
不能在一个单词,比如database中搜索 taba,这样找不到数据,所以不能代替 like 模糊查询。
对于汉字区分词只能通过英文的 逗号,句号 进行区分词语 如: 我是汉字,你大爷的费劲,和你好 这样便有三个词语
对于后置模糊搜索:
1. select * from user where name like 'search%' 对于查询是否使用索引和 查询结果的数量(因为筛选结果过多会导致使用索引还没有全表扫描快)和select的字段有关,如果选择的字段都是有index的,则模糊查询的字段使用index,具体通过 explain查看。
2.SELECT * FROM user WHERE MATCH (name) AGAINST ('search*' IN BOOLEAN MODE); 对于此类一定使用全文索引。
所以对于后置模糊搜索有这两种好的方式,具体用哪一种 根据实际业务分析。
4.like使用
1. select的字段是否是索引字段为准。如果select字段全部是索引字段则模糊搜索字段绝对使用索引
2.在select字段含有非索引字段时,只有在后置模糊搜索时 根据查询结果数量少时才使用索引,其他情况绝不使用索引
5.in,between,or 尽量使用 union all代替,不要用between和 or ,他们都会使用全表搜索.
1.针对select字段含有非索引字段时,上面的情况有效。
2.如果select字段都是索引字段,则使用between或者or或者union都会使用搜索条件的索引

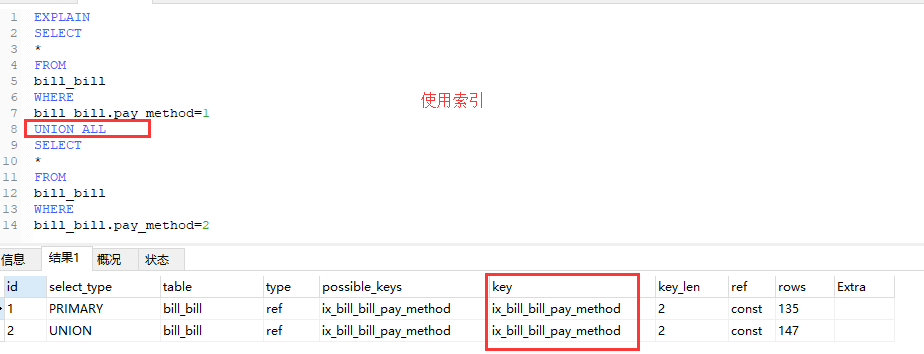
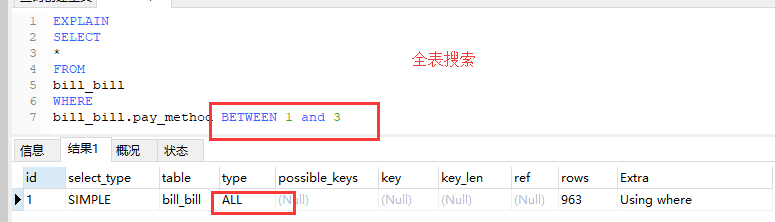
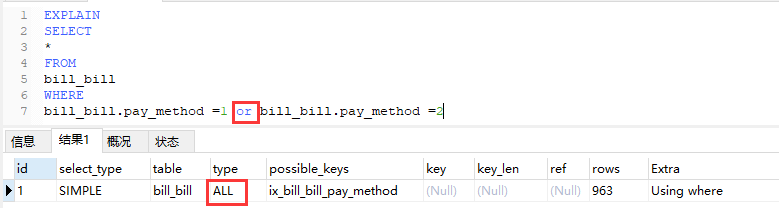
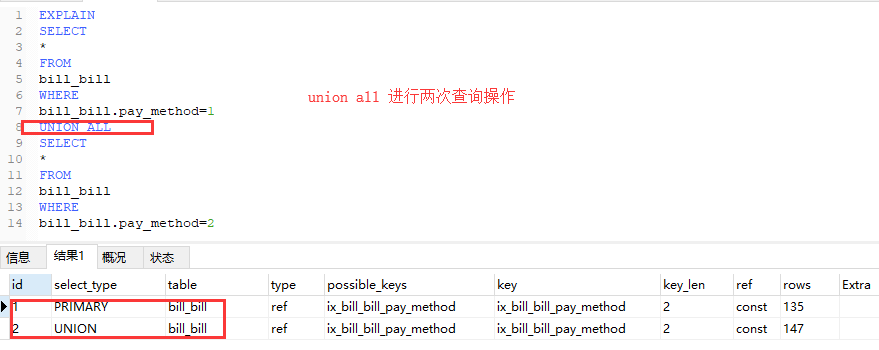
6.union all尽量代替union . 如果根据需求搜索结果不会重复或者不关心重复,则使用此union all方式.
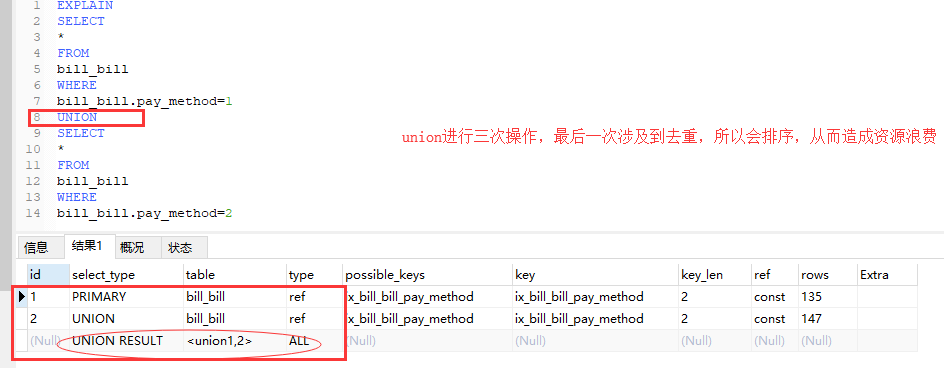
7.where字句尽量不要有运算或者函数,这样会导致不使用索引而使用全表扫描


8.对于数据列的类型在搜索时尽量不要改变,如 id 是int类型,不要 用 varchar类型搜索 where id = '3' 应该用 where id =3
减少mysql在内部转换的操作
9.order by 后面尽量使用索引列


10.sql语句尽量都用一样的格式书写,这样缓存认识,从而重复查询直接取缓存,而且减轻 sql编译的复杂度。
如尽量全部 用大写,并且 select的字段加表名及别名;SELECT bill_bill.id as id FROM bill_bill WHERE bill_bill.id = 1;
11.数据库访问数据是按照 页访问数据,一页大小比如是16k,一页可以存储多行数据,所以select 多个字段和一个字段 访问数据库的数据量都是一样的。
但是当只是select 索引列时,直接从索引中取数据,不会再去读表的 页。 这也是为什么 select * 比select id 慢的原因,因为需要从表的页中读取数据,而id直接读取索引并返回
12.order by中,如果select 中有索引,很有可能结果也是按照此索引排序的,如果业务符合 可以 不要再进行order by排序,因为已经通过索引排序了。当然 如果业务需要 倒叙desc的话order by不可省略,因为索引排序的是 正序排序。
explain 中 Extra 发生排序 的 标志是 Using Filesort(不是说进行磁盘文件排序,只是一个标志而已)
13.由于MySQL数据库是基于行(Row)存储的数据库,而数据库操作 IO 的时候是以 page(block)的方式,也就是说,如果我们每条记录所占用的空间量减小,就会使每个page中可存放的数据行数增大,那么每次 IO 可访问的行数也就增多了。反过来说,处理相同行数的数据,需要访问的 page 就会减少,也就是 IO 操作次数降低,直接提升性能。此外,由于我们的内存是有限的,增加每个page中存放的数据行数,就等于增加每个内存块的缓存数据量,同时还会提升内存换中数据命中的几率,也就是缓存命中率。
有些时候,我们可能会希望将一个完整的对象对应于一张数据库表,这对于应用程序开发来说是很有好的,但是有些时候可能会在性能上带来较大的问题。当我们的表中存在类似于 TEXT 或者是很大的 VARCHAR类型的大字段的时候,如果我们大部分访问这张表的时候都不需要这个字段,我们就该义无反顾的将其拆分到另外的独立表中,以减少常用数据所占用的存储空间。这样做的一个明显好处就是每个数据块中可以存储的数据条数可以大大增加,既减少物理 IO 次数,也能大大提高内存中的缓存命中率。
14.mysql5.7开启慢查询日志,能够记录下响应时间超过一定阈值的SQL查询,以便于我们定位糟糕的查询语句。
默认关闭慢查询,开启方法有两种
一:先在 sql 中查询 show variables like '%quer%';
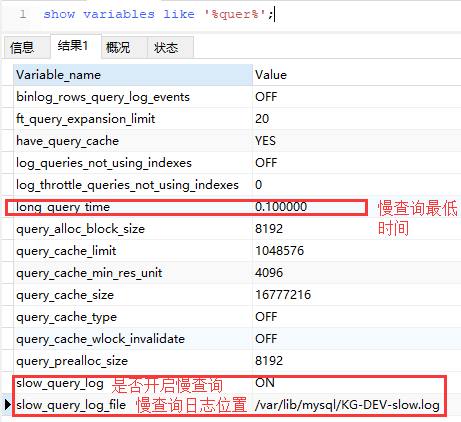
再 通过set global 动态设置慢查询命令,效果只保持到下次重启数据库
set GLOBAL slow_query_log=ON
set GLOBAL long_query_time = 1
set global long_query_time =0.1
set global slow_query_log_file = /var/log/mysql/slow_query.log
然后验证 输入: select SLEEP(2),查看 对应日志是否记录。
结果: 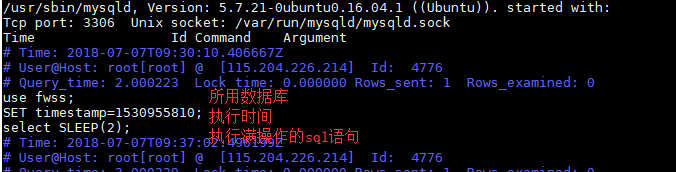
注意:在设置后慢查询命令后要新开窗口查看 show variables like '%quer%'; 及 select SLEEP(2) 命令执行结果,因为之前的窗口不会更新查询结果
二:通过 my.conf文件设置常量
1.通过 find / | grep my.conf 查看文件所在位置
2.在[mysqld]下面添加:
slow_query_log = ON
slow_query_log_file = /var/log/mysql/mysql-slow.log
long_query_time = 0.1
3.通过 mysqld restart 重启数据库 (但是自己重启后仍然没有配置成功)
配置慢查询方法: https://blog.csdn.net/huoyuanshen/article/details/52699569
重启数据库方法: https://blog.csdn.net/cx136295988/article/details/76690722
15.mysql常量含义
用于配置数据库 https://blog.csdn.net/longxibendi/article/details/6704969
16.数据库优化规则。
1.利用limit分页
2.数据库查询时返回更少的数据,避免返回不必要的数据
3.对于不经常select的大数据量字段,比如request的值等,通过拆分表格,放到新表中,达到减少查询数据量的目的
4.进行批量操作
5.优化业务逻辑,根据实际业务数据情况进行优化sql查询方式等。
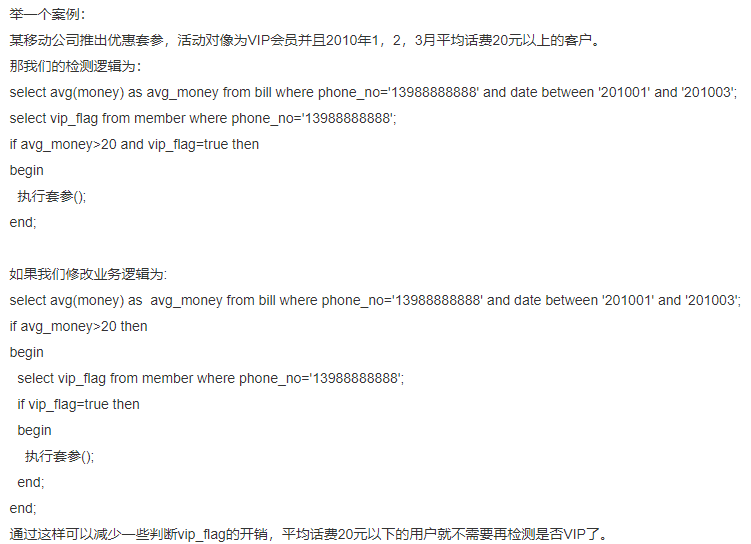

5.用 >=代替 >;如>=3取出3及以上进行比较,但是>2会取出2及以上进行比较,所以 > 比 >=多比较了一次
6.不用在索引列中使用 not,is null, is not null
7.时间存储类型存储空间长短: DATE(精确到某一天)<TIMESTAMP<DATETIME
17.查询数据库各种sql执行频率。
通过SHOW [session|global] STATUS LIKE 'Com_%';查看各种sql的执行频率。
默认使用session级别,针对的是当前会话,而如果使用 show global status like 'Com_%'; 统计的结果是从数据库上次启动至今的范围。
18.mysql设置缓存,提高性能,不用担心数据是否及时更新,因为表改变时,缓存失效


19.分析数据库的四个方法:
使用explain https://www.cnblogs.com/butterfly100/archive/2018/01/15/8287569.html
开启慢查询功能,记录查询时间较长的sql;并通过 mysqldumpslow程序 分析 慢查询日志文件;https://blog.csdn.net/sunyuhua_keyboard/article/details/81204020
使用MySQL profile 分析 :https://blog.csdn.net/ty_hf/article/details/54895026?utm_source=blogxgwz0
通过SHOW [session|global] STATUS LIKE 'Com_%';查看各种sql的执行频率。
相关网址:http://blog.jobbole.com/100349/
https://blog.csdn.net/yzllz001/article/details/54848513
https://www.cnblogs.com/hanzhao1987/p/6100096.html
https://blog.csdn.net/ty_hf/article/details/54895026
mysql数据库优化(二)的更多相关文章
- MySQL性能优化(二):优化数据库的设计
原文:MySQL性能优化(二):优化数据库的设计 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog.csdn.n ...
- 50多条mysql数据库优化建议
1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引. 缺省情况下建立的索引是非群集索引,但有时它并不是最佳的.在非群集索引下,数据在物理上随机存 ...
- 解开发者之痛:中国移动MySQL数据库优化最佳实践(转)
开源数据库MySQL比较容易碰到性能瓶颈,为此经常需要对MySQL数据库进行优化,而MySQL数据库优化需要运维DBA与相关开发共同参与,其中MySQL参数及服务器配置优化主要由运维DBA完成,开发则 ...
- 关于mysql数据库优化
关于mysql数据库优化 以我之愚见,数据库的优化在于优化存储和查询速度 目前主要的优化我认为是优化查询速度,查询速度快了,提高了用户的体验 我认为优化主要从两方面进行考虑, 优化数据库对象, 优化s ...
- mysql 数据库优化第一篇(基础)
Mysql数据库优化 1. 优化概述 存储层:存储引擎.字段类型选择.范式设计 设计层:索引.缓存.分区(分表) 架构层:多个mysql服务器设置,读写分离(主从模式) sql语句层:多个sql语句都 ...
- mysql数据库优化课程---18、mysql服务器优化
mysql数据库优化课程---18.mysql服务器优化 一.总结 一句话总结: 1.四种字符集问题:字符集都设置为utf-82.slow log慢查询日志问题3.root密码丢失 1.mysql存在 ...
- mysql数据库优化课程---17、mysql索引优化
mysql数据库优化课程---17.mysql索引优化 一.总结 一句话总结:一些字段可能会使索引失效,比如like,or等 1.check表监测的使用场景是什么? 视图 视图建立在两个表上, 删除了 ...
- mysql数据库优化课程---16、mysql慢查询和优化表空间
mysql数据库优化课程---16.mysql慢查询和优化表空间 一.总结 一句话总结: a.慢查询的话找到存储慢查询的那个日志文件 b.优化表空间的话可以用optimize table sales; ...
- mysql数据库优化课程---15、mysql优化步骤
mysql数据库优化课程---15.mysql优化步骤 一.总结 一句话总结:索引优化最立竿见影 1.mysql中最常用最立竿见影的优化是什么? 索引优化 索引优化,不然有多少行要扫描多少次,1亿行大 ...
- mysql数据库优化课程---14、常用的sql技巧
mysql数据库优化课程---14.常用的sql技巧 一.总结 一句话总结:其实就是sql中那些函数的使用 1.mysql中函数如何使用? 选择字段 其实就是作用域select的选择字段 3.转大写: ...
随机推荐
- JavaScript 隐式类型转换之:加号+
加号+,有些情况下,它是算术加号,有些情况下,是字符串连接符号 如果字符串和数字相加,JavaScript会自动把数字转换成字符,不管数字在前还是字符串在前 "2" + 3; // ...
- malloc的使用、用malloc动态分配内存以适应用户的需求的源代码实例
int len; ; printf("please enter the size that you want: "); scanf("%d", &len ...
- Linux fdisk普通分区扩容
买了一个orangepi 然后用7.4GB的内存卡,写入了一个lubuntu镜像,用去3.6GB还有3.8GB没有用,因为要编译mt7601u进ubuntu中,需要用到内核文件 但是内核压缩包1.2G ...
- 5、Linux-Mac配置环境变量
1.安装jdk1.6,1.7,1.8 2.查看jdk安装目录 /usr/libexec/java_home -v 1.6 /usr/libexec/java_home -v 1.7 /usr/libe ...
- Linux 安装MySql启动Can't locate Data/Dumper.pm in @INC
通过RPM包CentOS7 安装MySQL的时候提示“Can't locate Data/Dumper.pm in @INC (@INC contains: /usr/local/lib64/perl ...
- 2019.4.11 一题 XSY 1551 ——广义后缀数组(trie上后缀数组)
参考:http://www.mamicode.com/info-detail-1949898.html (log2) https://blog.csdn.net/geotcbrl/article/de ...
- 公式推导:【CFNet】
[CFNet]: Valmadre J, Bertinetto L, Henriques J F, et al. End-to-end representation learning for Corr ...
- Java变量的初始值
Java中的变量如果没有赋值,成员变量默认被初始化,局部变量则不会. 对于成员变量 int a; // a的初始值为0 如下例中的成员变量a,b,c,d public class Va ...
- DataFlow编程模型与Spark Structured streaming
流式(streaming)和批量( batch):流式数据,实际上更准确的说法应该是unbounded data(processing),也就是无边界的连续的数据的处理:对应的批量计算,更准确的说法是 ...
- influxDB硬件配置指南
原地址:https://docs.influxdata.com/influxdb/v1.6/guides/hardware_sizing/ 警告!此页面记录了不再积极开发的InfluxDB的早期版本. ...