StanFord ML 笔记 第三部分
第三部分:
1.指数分布族
2.高斯分布--->>>最小二乘法
3.泊松分布--->>>线性回归
4.Softmax回归
指数分布族:
结合Ng的课程,在看这篇博文:http://blog.csdn.net/acdreamers/article/details/44663091
泊松分布:
这里是一个扩展,看不看都可以:http://www.ruanyifeng.com/blog/2015/06/poisson-distribution.html
Softmax回归:
有点难度的,看了3个多小时才看懂。自己就不重复造轮子了,以下是在原文的基础上做的笔记,直接看真的很懵逼!
简介:
在本节中,我们介绍Softmax回归模型,该模型是logistic回归模型在多分类问题上的推广,在多分类问题中,类标签 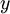 可以取两个以上的值。 Softmax回归模型对于诸如MNIST手写数字分类等问题是很有用的,该问题的目的是辨识10个不同的单个数字。Softmax回归是有监督的,不过后面也会介绍它与深度学习/无监督学习方法的结合。
可以取两个以上的值。 Softmax回归模型对于诸如MNIST手写数字分类等问题是很有用的,该问题的目的是辨识10个不同的单个数字。Softmax回归是有监督的,不过后面也会介绍它与深度学习/无监督学习方法的结合。
回想一下在 logistic 回归中,我们的训练集由 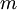 个已标记的样本构成:
个已标记的样本构成: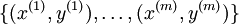 ,其中输入特征
,其中输入特征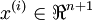 。(我们对符号的约定如下:特征向量
。(我们对符号的约定如下:特征向量  的维度为
的维度为 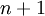 ,其中
,其中 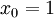 对应截距项 。) 由于 logistic 回归是针对二分类问题的,因此类标记
对应截距项 。) 由于 logistic 回归是针对二分类问题的,因此类标记 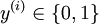 。假设函数(hypothesis function) 如下:
。假设函数(hypothesis function) 如下:
注释:这是已经利用泊松分布概率推到的函数。
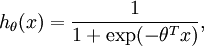
我们将训练模型参数 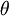 ,使其能够最小化代价函数 :
,使其能够最小化代价函数 :
注释:代价函数在这里的理解就是所有样本概率求和函数。
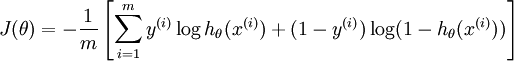
在 softmax回归中,我们解决的是多分类问题(相对于 logistic 回归解决的二分类问题),类标 可以取 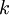 个不同的值(而不是 2 个)。因此,对于训练集 ,我们有
个不同的值(而不是 2 个)。因此,对于训练集 ,我们有 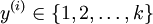 。(注意此处的类别下标从 1 开始,而不是 0)。例如,在 MNIST 数字识别任务中,我们有
。(注意此处的类别下标从 1 开始,而不是 0)。例如,在 MNIST 数字识别任务中,我们有 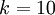 个不同的类别。
个不同的类别。
对于给定的测试输入 ,我们想用假设函数针对每一个类别j估算出概率值 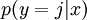 。也就是说,我们想估计 的每一种分类结果出现的概率。因此,我们的假设函数将要输出一个 维的向量(向量元素的和为1)来表示这 个估计的概率值。 具体地说,我们的假设函数
。也就是说,我们想估计 的每一种分类结果出现的概率。因此,我们的假设函数将要输出一个 维的向量(向量元素的和为1)来表示这 个估计的概率值。 具体地说,我们的假设函数 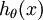 形式如下:
形式如下:
注释:此图是对下面表达式的说明。

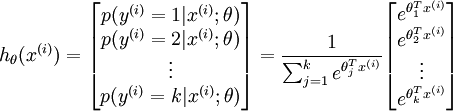
其中 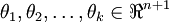 是模型的参数。请注意
是模型的参数。请注意 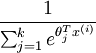 这一项对概率分布进行归一化,使得所有概率之和为 1 。
这一项对概率分布进行归一化,使得所有概率之和为 1 。
为了方便起见,我们同样使用符号 来表示全部的模型参数。在实现Softmax回归时,将 用一个 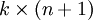 的矩阵来表示会很方便,该矩阵是将
的矩阵来表示会很方便,该矩阵是将 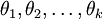 按行罗列起来得到的,如下所示:
按行罗列起来得到的,如下所示:
注释:每个thea都是n行向量,前面求解回归方程已经说明。
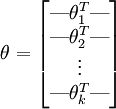
代价函数:
现在我们来介绍 softmax 回归算法的代价函数。在下面的公式中,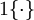 是示性函数,其取值规则为:
是示性函数,其取值规则为:
注释:这里是个判断函数,在数学表达式中很少,但是程序直接写 print_value = a==b ? 1 : 0;
1{值为真的表达式 }=1,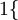 值为假的表达式
值为假的表达式 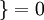 。
。
举例来说,表达式 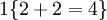 的值为1 ,
的值为1 ,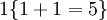 的值为 0。我们的代价函数为:
的值为 0。我们的代价函数为:
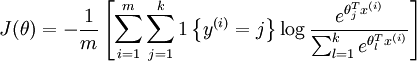
值得注意的是,上述公式是logistic回归代价函数的推广。logistic回归代价函数可以改为:
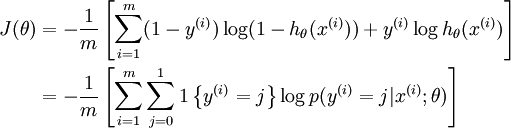
可以看到,Softmax代价函数与logistic 代价函数在形式上非常类似,只是在Softmax损失函数中对类标记的 个可能值进行了累加。注意在Softmax回归中将 分类为类别  的概率为:
的概率为:
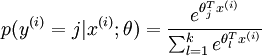
对于 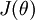 的最小化问题,目前还没有闭式解法。因此,我们使用迭代的优化算法(例如梯度下降法,或 L-BFGS)。经过求导,我们得到梯度公式如下:
的最小化问题,目前还没有闭式解法。因此,我们使用迭代的优化算法(例如梯度下降法,或 L-BFGS)。经过求导,我们得到梯度公式如下:
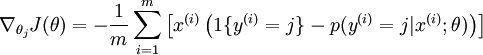
让我们来回顾一下符号 "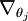 " 的含义。
" 的含义。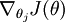 本身是一个向量,它的第
本身是一个向量,它的第 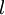 个元素
个元素 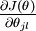 是 对
是 对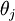 的第 个分量的偏导数。
的第 个分量的偏导数。
有了上面的偏导数公式以后,我们就可以将它代入到梯度下降法等算法中,来最小化 。 例如,在梯度下降法的标准实现中,每一次迭代需要进行如下更新: 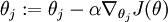 (
(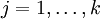 )。
)。
当实现 softmax 回归算法时, 我们通常会使用上述代价函数的一个改进版本。具体来说,就是和权重衰减(weight decay)一起使用。我们接下来介绍使用它的动机和细节。
Softmax回归模型参数化的特点:
Softmax 回归有一个不寻常的特点:它有一个“冗余”的参数集。为了便于阐述这一特点,假设我们从参数向量 中减去了向量 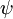 ,这时,每一个 都变成了
,这时,每一个 都变成了 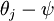 ()。此时假设函数变成了以下的式子:
()。此时假设函数变成了以下的式子:
注释:这个“冗余”的意思是参数太多,N方程解N个未知数,现在出现N个方程N+1个未知数,那么出现的结果就是未知数的解不唯一。
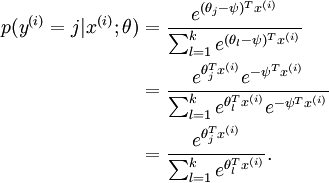
换句话说,从 中减去 完全不影响假设函数的预测结果!这表明前面的 softmax 回归模型中存在冗余的参数。更正式一点来说, Softmax 模型被过度参数化了。对于任意一个用于拟合数据的假设函数,可以求出多组参数值,这些参数得到的是完全相同的假设函数 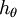 。
。
进一步而言,如果参数 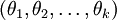 是代价函数 的极小值点,那么
是代价函数 的极小值点,那么 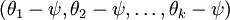 同样也是它的极小值点,其中 可以为任意向量。因此使 最小化的解不是唯一的。(有趣的是,由于 仍然是一个凸函数,因此梯度下降时不会遇到局部最优解的问题。但是 Hessian 矩阵是奇异的/不可逆的,这会直接导致采用牛顿法优化就遇到数值计算的问题)
同样也是它的极小值点,其中 可以为任意向量。因此使 最小化的解不是唯一的。(有趣的是,由于 仍然是一个凸函数,因此梯度下降时不会遇到局部最优解的问题。但是 Hessian 矩阵是奇异的/不可逆的,这会直接导致采用牛顿法优化就遇到数值计算的问题)
注释:上面已经说明解不唯一,那么就等于这个函数的最大似然函数不收敛-->>不存在局部最优解-->>Hessian矩阵是不存在的-->>那么最大似然函数就是无解的。。。
注意,当 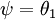 时,我们总是可以将
时,我们总是可以将 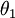 替换为
替换为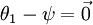 (即替换为全零向量),并且这种变换不会影响假设函数。因此我们可以去掉参数向量 (或者其他 中的任意一个)而不影响假设函数的表达能力。实际上,与其优化全部的 个参数 (其中
(即替换为全零向量),并且这种变换不会影响假设函数。因此我们可以去掉参数向量 (或者其他 中的任意一个)而不影响假设函数的表达能力。实际上,与其优化全部的 个参数 (其中 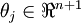 ),我们可以令
),我们可以令 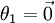 ,只优化剩余的
,只优化剩余的 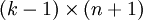 个参数,这样算法依然能够正常工作。
个参数,这样算法依然能够正常工作。
在实际应用中,为了使算法实现更简单清楚,往往保留所有参数 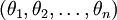 ,而不任意地将某一参数设置为 0。但此时我们需要对代价函数做一个改动:加入权重衰减。权重衰减可以解决 softmax 回归的参数冗余所带来的数值问题。
,而不任意地将某一参数设置为 0。但此时我们需要对代价函数做一个改动:加入权重衰减。权重衰减可以解决 softmax 回归的参数冗余所带来的数值问题。
权重衰减:

我们通过添加一个权重衰减项 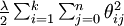 来修改代价函数,这个衰减项会惩罚过大的参数值,现在我们的代价函数变为:
来修改代价函数,这个衰减项会惩罚过大的参数值,现在我们的代价函数变为:
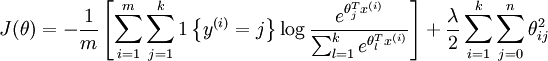
有了这个权重衰减项以后 (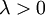 ),代价函数就变成了严格的凸函数,这样就可以保证得到唯一的解了。 此时的 Hessian矩阵变为可逆矩阵,并且因为是凸函数,梯度下降法和 L-BFGS 等算法可以保证收敛到全局最优解。
),代价函数就变成了严格的凸函数,这样就可以保证得到唯一的解了。 此时的 Hessian矩阵变为可逆矩阵,并且因为是凸函数,梯度下降法和 L-BFGS 等算法可以保证收敛到全局最优解。
为了使用优化算法,我们需要求得这个新函数 的导数,如下:
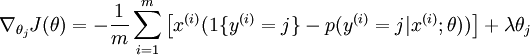
通过最小化 ,我们就能实现一个可用的 softmax 回归模型。
Softmax回归与Logistic 回归的关系:
当类别数 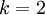 时,softmax 回归退化为 logistic 回归。这表明 softmax 回归是 logistic 回归的一般形式。具体地说,当 时,softmax 回归的假设函数为:
时,softmax 回归退化为 logistic 回归。这表明 softmax 回归是 logistic 回归的一般形式。具体地说,当 时,softmax 回归的假设函数为:
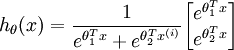
利用softmax回归参数冗余的特点,我们令 ,并且从两个参数向量中都减去向量 ,得到:
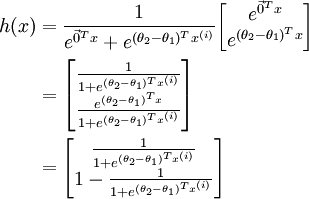
因此,用  来表示
来表示 ,我们就会发现 softmax 回归器预测其中一个类别的概率为
,我们就会发现 softmax 回归器预测其中一个类别的概率为 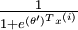 ,另一个类别概率的为
,另一个类别概率的为 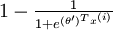 ,这与 logistic回归是一致的。
,这与 logistic回归是一致的。
Softmax 回归 vs. k 个二元分类器:
注释:这里好理解了,唯一性用SoftMax,不唯一用K个二分类器。
如果你在开发一个音乐分类的应用,需要对k种类型的音乐进行识别,那么是选择使用 softmax 分类器呢,还是使用 logistic 回归算法建立 k 个独立的二元分类器呢?
这一选择取决于你的类别之间是否互斥,例如,如果你有四个类别的音乐,分别为:古典音乐、乡村音乐、摇滚乐和爵士乐,那么你可以假设每个训练样本只会被打上一个标签(即:一首歌只能属于这四种音乐类型的其中一种),此时你应该使用类别数 k = 4 的softmax回归。(如果在你的数据集中,有的歌曲不属于以上四类的其中任何一类,那么你可以添加一个“其他类”,并将类别数 k 设为5。)
如果你的四个类别如下:人声音乐、舞曲、影视原声、流行歌曲,那么这些类别之间并不是互斥的。例如:一首歌曲可以来源于影视原声,同时也包含人声 。这种情况下,使用4个二分类的 logistic 回归分类器更为合适。这样,对于每个新的音乐作品 ,我们的算法可以分别判断它是否属于各个类别。
现在我们来看一个计算视觉领域的例子,你的任务是将图像分到三个不同类别中。(i) 假设这三个类别分别是:室内场景、户外城区场景、户外荒野场景。你会使用sofmax回归还是 3个logistic 回归分类器呢? (ii) 现在假设这三个类别分别是室内场景、黑白图片、包含人物的图片,你又会选择 softmax 回归还是多个 logistic 回归分类器呢?
在第一个例子中,三个类别是互斥的,因此更适于选择softmax回归分类器 。而在第二个例子中,建立三个独立的 logistic回归分类器更加合适。
原文地址:http://deeplearning.stanford.edu/wiki/index.php/Softmax%E5%9B%9E%E5%BD%92
StanFord ML 笔记 第三部分的更多相关文章
- StanFord ML 笔记 第五部分
1.朴素贝叶斯的多项式事件模型: 趁热打铁,直接看图理解模型的意思:具体求解可见下面大神给的例子,我这个是流程图. 在上篇笔记中,那个最基本的NB模型被称为多元伯努利事件模型(Multivariate ...
- StanFord ML 笔记 第九部分
第九部分: 1.高斯混合模型 2.EM算法的认知 1.高斯混合模型 之前博文已经说明:http://www.cnblogs.com/wjy-lulu/p/7009038.html 2.EM算法的认知 ...
- StanFord ML 笔记 第八部分
第八部分内容: 1.正则化Regularization 2.在线学习(Online Learning) 3.ML 经验 1.正则化Regularization 1.1通俗解释 引用知乎作者:刑无刀 ...
- StanFord ML 笔记 第一部分
本章节内容: 1.学习的种类及举例 2.线性回归,拟合一次函数 3.线性回归的方法: A.梯度下降法--->>>批量梯度下降.随机梯度下降 B.局部线性回归 C.用概率证明损失函数( ...
- StanFord ML 笔记 第十部分
第十部分: 1.PCA降维 2.LDA 注释:一直看理论感觉坚持不了,现在进行<机器学习实战>的边写代码边看理论
- StanFord ML 笔记 第六部分&&第七部分
第六部分内容: 1.偏差/方差(Bias/variance) 2.经验风险最小化(Empirical Risk Minization,ERM) 3.联合界(Union bound) 4.一致收敛(Un ...
- StanFord ML 笔记 第四部分
第四部分: 1.生成学习法 generate learning algorithm 2.高斯判别分析 Gaussian Discriminant Analysis 3.朴素贝叶斯 Navie Baye ...
- StanFord ML 笔记 第二部分
本章内容: 1.逻辑分类与回归 sigmoid函数概率证明---->>>回归 2.感知机的学习策略 3.牛顿法优化 4.Hessian矩阵 牛顿法优化求解: 这个我就不记录了,看到一 ...
- PyQt4入门学习笔记(三)
# PyQt4入门学习笔记(三) PyQt4内的布局 布局方式是我们控制我们的GUI页面内各个控件的排放位置的.我们可以通过两种基本方式来控制: 1.绝对位置 2.layout类 绝对位置 这种方式要 ...
随机推荐
- Webstorm/IntelliJ Idea 过期破解方法
一.Webstorm过期破解方法 如下图,WebStorm过期了,每次都是用30分钟,重新打开. 解决方法: 注册时,在打开的License Activation窗口中选择“License serve ...
- Ionic 使用karma进行单元测试
1. 创建Ionic工程 ionic start projectname cd projectname 2.安装karma插件 npm install karma karma-jasmine karm ...
- sbt第一次运行下载jar包很慢解决办法
一.补充sbt配置文件,添加下载路径 文件结构如下:修改了sbtconfig.txt,repo.properties. sbtconfig.txt配置内容为: # Set the java args ...
- java中三种for循环之间的对比
普通for循环语法: for (int i = 0; i < integers.length; i++) { System.out.println(intergers[i]); } foreac ...
- mysql 删除数据库中所有的表中的数据,只删database下面所有的表。
select concat('drop table ',table_name,';') from TABLES where table_schema='数据库名称'; select concat('t ...
- Avalon总线学习 ---Avalon Interface Specifications
Avalon总线学习 ---Avalon Interface Specifications 1.Avalon Interfaces in a System and Nios II Processor ...
- Flume的基本概念
Flume 概念 Flume 最早是Cludera提供的日志收集系统,后贡献给Apache.所以目前是Apache下的项目,Flume支持在日志系统中指定各类数据发送方,用于收集数据. Flume 是 ...
- nodejs选择JavaScript作为开发语言,是因为一般的开发语言的标准库都是带有IO模块的,并且通常这个 模块是阻塞性的,所以nodejs选择了没有自带IO模块的Javascript
Javascrip本身不带IO功能,nodejs选择JavaScript作为开发语言,是因为一般的开发语言的标准库都是带有IO模块的,并且通常这个 模块是阻塞性的,所以nodejs选择了没有自带IO模 ...
- angular的subscribe
angular中可以使用observable和subscribe实现订阅,从而实现异步. 这里记录一个工作中的小问题,以加深对subscribe的理解.前端技能弱,慢慢积累中. 本来希望的是点击一个按 ...
- go语言学习--go的临时对象池--sync.Pool
一个sync.Pool对象就是一组临时对象的集合.Pool是协程安全的. Pool用于存储那些被分配了但是没有被使用,而未来可能会使用的值,以减小垃圾回收的压力.一个比较好的例子是fmt包,fmt包总 ...