C#winform抓取百度,Google搜索关键词结果
基于网站seo,做了一采集百度和Google搜索关键字结果的采集.在这里与大家分享一下
先看先效果图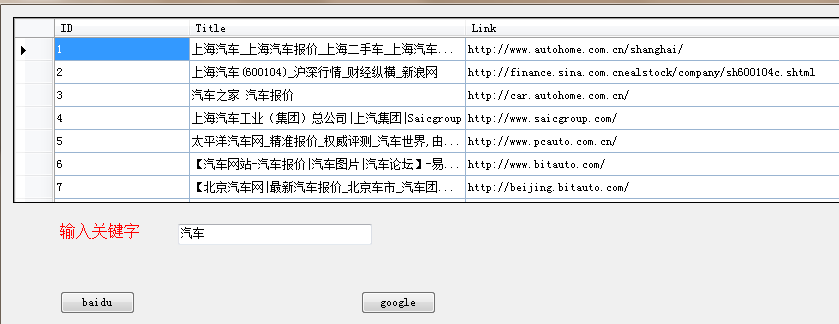
代码附加:
1 private void baidu_Click(object sender, EventArgs e)
2 {
3 int num = 100;//搜索条数
4 string url = "http://www.baidu.com/s?wd=" + txtSearch.Text.Trim() + "&rn=" + num + "";
5 string html = search(url, "gb2312");
6 BaiduSearch baidu = new BaiduSearch();
7 if (!string.IsNullOrEmpty(html))
8 {
9 int count = baidu.GetSearchCount(html);//搜索条数
10 if (count > 0)
11 {
12 List<Keyword> keywords = baidu.GetKeywords(html, txtSearch.Text.Trim());
13 dataGridView1.DataSource = keywords;
14 }
15
16 }
17 }
18
19 private void google_Click(object sender, EventArgs e)
20 {
21 int num = 100;
22 string url = "http://www.google.com.hk/search?hl=zh-CN&source=hp&q=" + txtSearch.Text.Trim() + "&aq=f&aqi=&aql=&oq=&num=" + num + "";
23 string html = search(url, "utf-8");
24 if (!string.IsNullOrEmpty(html))
25 {
26
27 googleSearch google = new googleSearch();
28 List<Keyword> keywords = google.GetKeywords(html, txtSearch.Text.Trim());
29 dataGridView1.DataSource = keywords;
30
31 }
32 }
33 /// <summary>
34 /// 搜索处理
35 /// </summary>
36 /// <param name="url">搜索网址</param>
37 /// <param name="Chareset">编码</param>
38 public string search(string url, string Chareset)
39 {
40 HttpState result = new HttpState();
41 Uri uri = new Uri(url);
42 HttpWebRequest myHttpWebRequest = (HttpWebRequest)WebRequest.Create(url);
43 myHttpWebRequest.UseDefaultCredentials = true;
44 myHttpWebRequest.ContentType = "text/html";
45 myHttpWebRequest.UserAgent = "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.0; .NET CLR 1.1.4322; .NET CLR 2.0.50215;)";
46 myHttpWebRequest.Method = "GET";
47 myHttpWebRequest.CookieContainer = new CookieContainer();
48
49 try
50 {
51 HttpWebResponse response = (HttpWebResponse)myHttpWebRequest.GetResponse();
52 // 从 ResponseStream 中读取HTML源码并格式化 add by cqp
53 result.Html = readResponseStream(response, Chareset);
54 result.CookieContainer = myHttpWebRequest.CookieContainer;
55 return result.Html;
56 }
57 catch (Exception ex)
58 {
59 return ex.ToString();
60 }
61
62 }
63 public string readResponseStream(HttpWebResponse response, string Chareset)
64 {
65 string result = "";
66 using (StreamReader responseReader = new StreamReader(response.GetResponseStream(), Encoding.GetEncoding(Chareset)))
67 {
68 result = formatHTML(responseReader.ReadToEnd());
69 }
70
71 return result;
72 }
73 /// <summary>
74 /// 描述:格式化网页源码
75 ///
76 /// </summary>77 /// <param name="htmlContent"></param>78 /// <returns></returns>79 public string formatHTML(string htmlContent)80 {81 string result = "";82 83 result = htmlContent.Replace("»", "").Replace(" ", "")84 .Replace("©", "").Replace("/r", "").Replace("/t", "")85 .Replace("/n", "").Replace("&", "&");86 return result;87
把百度和Google两个类抽取了出来
1.百度Search类
1 class BaiduSearch
2 {
3 protected string uri = "http://www.baidu.com/s?wd=";
4 protected Encoding queryEncoding = Encoding.GetEncoding("gb2312");
5 protected Encoding pageEncoding = Encoding.GetEncoding("gb2312");
6 protected string resultPattern = @"(?<=找到相关结果[约]?)[0-9,]*?(?=个)";
7 public int GetSearchCount(string html)
8 {
9 int result = 0;
10 string searchcount = string.Empty;
11
12 Regex regex = new Regex(resultPattern);
13 Match match = regex.Match(html);
14
15 if (match.Success)
16 {
17 searchcount = match.Value;
18 }
19 else
20 {
21 searchcount = "0";
22 }
23
24 if (searchcount.IndexOf(",") > 0)
25 {
26 searchcount = searchcount.Replace(",", string.Empty);
27 }
28
29 int.TryParse(searchcount, out result);
30
31 return result;
32 }
33
34 public List<Keyword> GetKeywords(string html, string word)
35 {
36 int i = 1;
37 List<Keyword> keywords = new List<Keyword>();
38 string ss="<h3 class=\"t\"><a.*?href=\"(?<url>.*?)\".*?>(?<content>.*?)</a>";
39 MatchCollection mcTable = Regex.Matches(html,ss);
40 foreach (Match mTable in mcTable)
41 {
42 if (mTable.Success)
43 {
44 Keyword keyword = new Keyword();
45 keyword.ID = i++;
46 keyword.Title = Regex.Replace(mTable.Groups["content"].Value, "<[^>]*>", string.Empty);
47 keyword.Link = mTable.Groups["url"].Value;
48 keywords.Add(keyword);
49
50 }
51 }
52
53 return keywords;
54 }
2 .GoogleSearch类
1 class googleSearch
2 {
3
4 public List<Keyword> GetKeywords(string html, string word)
5 {
6 int i = 1;
7 List<Keyword> keywords = new List<Keyword>();
8
9 Regex regTable = new Regex("<h3 class=\"r\"><a.*?href=\"(?<url>.*?)\".*?>(?<content>.*?)</a>", RegexOptions.IgnoreCase);
10 Regex regA = new Regex(@"(?is)<a/b[^>]*?href=(['""]?)(?<link>[^'""/s>]+)/1[^>]*>(?<title>.*?)</a>", RegexOptions.IgnoreCase);
11
12 MatchCollection mcTable = regTable.Matches(html);
13 foreach (Match mTable in mcTable)
14 {
15 if (mTable.Success)
16 {
17 Keyword keyword = new Keyword();
18 keyword.ID = i++;
19 keyword.Title = Regex.Replace(mTable.Groups["content"].Value, "<[^>]*>", string.Empty);
20 keyword.Link = mTable.Groups["url"].Value;
21 keywords.Add(keyword);
22 }
23 }
24
25 return keywords;
26 }
忘了.还有个导出Excel,这个友友们应该都有自己的方法,我这里就简单写了一个excel导出.也贴出来吧.
1 public void ExportDataGridViewToExcel(DataGridView dataGridview1)
2 {
3 SaveFileDialog saveFileDialog = new SaveFileDialog();
4 saveFileDialog.Filter = "Execl files (*.xls)|*.xls";
5 saveFileDialog.FilterIndex = 0;
6 saveFileDialog.RestoreDirectory = true;
7 saveFileDialog.CreatePrompt = true;
8 saveFileDialog.Title = "导出Excel文件";
9
10 DateTime now = DateTime.Now;
11 saveFileDialog.FileName = now.Year.ToString().PadLeft(2) + now.Month.ToString().PadLeft(2, '0') + now.Day.ToString().PadLeft(2, '0') + "-" + now.Hour.ToString().PadLeft(2, '0') + now.Minute.ToString().PadLeft(2, '0') + now.Second.ToString().PadLeft(2, '0');
12 saveFileDialog.ShowDialog();
13
14 Stream myStream;
15 myStream = saveFileDialog.OpenFile();
16 StreamWriter sw = new StreamWriter(myStream, System.Text.Encoding.GetEncoding("gb2312"));
17 string str = "";
18 try
19 {
20 //写标题
21 for (int i = 0; i < dataGridview1.ColumnCount; i++)
22 {
23 if (i > 0)
24 {
25 str += "\t";
26 }
27 str += dataGridview1.Columns[i].HeaderText;
28 }
29 sw.WriteLine(str);
30 //写内容
31 for (int j = 0; j < dataGridview1.Rows.Count; j++)
32 {
33 string tempStr = "";
34 for (int k = 0; k < dataGridview1.Columns.Count; k++)
35 {
36 if (k > 0)
37 {
38 tempStr += "\t";
39 }
40 tempStr += dataGridview1.Rows[j].Cells[k].Value.ToString();
41 }
42 sw.WriteLine(tempStr);
43 }
44 sw.Close();
45 myStream.Close();
46 MessageBox.Show("导出成功");
47 }
48 catch (Exception e)
49 {
50 MessageBox.Show(e.ToString());
51 }
52 finally
53 {
54 sw.Close();
55 myStream.Close();
56 }
57 }
我把HTTpStatus类给贴出来..有需要demo的可以发邮件给我.或者留下邮箱
Httpstatus.cs
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
|
class HttpState { private string _statusDescription; public string StatusDescription { get { return _statusDescription; } set { _statusDescription = value; } } /// <summary> /// 回调 址址, 登陆测试中使用 /// </summary> private string _callBackUrl; public string CallBackUrl { get { return _callBackUrl; } set { _callBackUrl = value; } } /// <summary> /// 网页网址 绝对路径格式 /// </summary> private string _url; public string Url { get { return _url; } set { _url = value; } } /// <summary> /// 字符串的形式的Cookie信息 /// </summary> private string _cookies; public string Cookies { get { return _cookies; } set { _cookies = value; } } /// <summary> /// Cookie信息 /// </summary> private CookieContainer _cookieContainer = new CookieContainer(); public CookieContainer CookieContainer { get { return _cookieContainer; } set { _cookieContainer = value; } } /// <summary> /// 网页源码 /// </summary> private string _html; public string Html { get { return _html; } set { _html = value; } } /// <summary> /// 验证码临时文件(绝对路径) /// </summary> private string _tmpValCodePic; public string TmpValCodePic { get { return _tmpValCodePic; } set { _tmpValCodePic = value; } } /// <summary> /// 验证码临时文件名(相对路径) /// </summary> private string _tmpValCodeFileName = "emptyPic.gif"; public string TmpValCodeFileName { get { return _tmpValCodeFileName; } set { _tmpValCodeFileName = value; } } /// <summary> /// 有验证码 /// </summary> private bool _isValCode; public bool IsValCode { get { return _isValCode; } set { _isValCode = value; } } /// <summary> /// 验证码URL /// </summary> private string _valCodeURL; public string ValCodeURL { get { return _valCodeURL; } set { _valCodeURL = value; } } /// <summary> /// 验证码识别后的值 /// </summary> private string _valCodeValue; public string ValCodeValue { get { return _valCodeValue; } set { _valCodeValue = value; } } /// <summary> /// 其它参数 /// </summary> private Hashtable _otherParams = new Hashtable(); public Hashtable OtherParams { get { return _otherParams; } set { _otherParams = value; } } // 重复添加处理 add by fengcj 09/11/19 PM public void addOtherParam(object key, object value) { if (!this.OtherParams.ContainsKey(key)) this.OtherParams.Add(key, value); else { this.OtherParams[key] = value; } } public void removeOtherParam(object key) { this.OtherParams.Remove(key); } public object getOtherParam(object key) { return this.OtherParams[key]; } } |
KeyWord.cs
class Keyword { public int ID { get; set; } public string Title { get; set; } public string Link { get; set; } } |
鉴于大家都需要demo,今天就整理一下发上来.添加了导出word,导出excel功能.晕...木找到怎么放文件路径进来....有需要的可以email我.
C#winform抓取百度,Google搜索关键词结果的更多相关文章
- selenium-java web自动化测试工具抓取百度搜索结果实例
selenium-java web自动化测试工具抓取百度搜索结果实例 这种方式抓百度的搜索关键字结果非常容易抓长尾关键词,根据热门关键词去抓更多内容可以用抓google,百度的这种内容容易给屏蔽,用这 ...
- PHP网络爬虫实践:抓取百度搜索结果,并分析数据结构
百度的搜索引擎有反爬虫机制,我先直接用guzzle试试水.代码如下: <?php /** * Created by Benjiemin * Date: 2020/3/5 * Time: 14:5 ...
- python requests库网页爬取小实例:百度/360搜索关键词提交
百度/360搜索关键词提交全代码: #百度/360搜索关键词提交import requestskeyword='Python'try: #百度关键字 # kv={'wd':keyword} #360关 ...
- Python多线程采集百度相关搜索关键词
百度相关搜索关键词抓取,读取txt关键词,导出txt关键词 #百度相关搜索关键词抓取,读取txt关键词,导出txt关键词 # -*- coding=utf-8 -*- import request ...
- Python抓取百度百科数据
前言 本文整理自慕课网<Python开发简单爬虫>,将会记录爬取百度百科"python"词条相关页面的整个过程. 抓取策略 确定目标:确定抓取哪个网站的哪些页面的哪部分 ...
- python3 - 通过BeautifulSoup 4抓取百度百科人物相关链接
导入需要的模块 需要安装BeautifulSoup from urllib.request import urlopen, HTTPError, URLError from bs4 import Be ...
- C#.Net使用正则表达式抓取百度百家文章列表
工作之余,学习了一下正则表达式,鉴于实践是检验真理的唯一标准,于是便写了一个利用正则表达式抓取百度百家文章的例子,具体过程请看下面源码: 一:获取百度百家网页内容 public List<str ...
- selenium+PhantomJS 抓取淘宝搜索商品
最近项目有些需求,抓取淘宝的搜索商品,抓取的品类还多.直接用selenium+PhantomJS 抓取淘宝搜索商品,快速完成. #-*- coding:utf-8 -*-__author__ =''i ...
- 用PHP抓取百度贴吧邮箱数据
注:本程序可能非常适合那些做百度贴吧营销的朋友. 去逛百度贴吧的时候,经常会看到楼主分享一些资源,要求留下邮箱,楼主才给发. 对于一个热门的帖子,留下的邮箱数量是非常多的,楼主需要一个一个的去复制那些 ...
随机推荐
- supervisorctl 常用命令
命令官方文档:http://supervisord.org/running.html#running-supervisorctl supervisorctl 常用命令: supervisorctl 常 ...
- web.xml启动spring详解
https://blog.csdn.net/king_cannon_fodder/article/details/79328576 详细介绍:https://www.cnblogs.com/wkrbk ...
- pyquery的使用
常用的三种初始化方法: 1.字符串初始化: from pyquery import PyQuery as pq html=""" <html> <hea ...
- c/c++ int数组初始化/重置为0
1.int数组其实初始化的时候默认就是全部为0 int a[1000];int a[1000] = {0}; 以上2种写法其实都可以 注意:int a[1000] = {0};这种方法如果想把整形数组 ...
- C#中四种常用集合的运用(非常重要)【转】
1.ArrayList ArrayList类似于数组,有人也称它为数组列表.ArrayList可以动态维护,而数组的容量是固定的. 它的索引会根据程序的扩展而重新进行分配和调整.和数组类似,它所存储的 ...
- ulimit设置内存限制是否有效
如何使用ulimit限制物理内存 限制物理内存 $ ulimit -m 512000 经测试,无效. 限制物理内存不起作用,ulimit不支持限制物理内存,可见man ulimit手册 -m The ...
- Centos7 设置Mongodb开机启动-自定义服务
(1).在/lib/systemd/system/目录下新建mongodb.service文件,内容如下 [Unit] Description=mongodb After=network.target ...
- LNMP, CentOS7.0+Nginx+Mysql5.7+PHP7环境安装
LNMP代表的就是:Linux系统下Nginx+MySQL+PHP这种网站服务器架构.这里和家分享一下,如何在CentOS 7.0上搭建一个这样的环境,其中软件使用yum方式安装. 进入CentOS ...
- HIMSS EMRAM新版标准将于2018年1月1日生效
https://www.cn-healthcare.com/article/20170223/content-489862.html HIMSS EMRAM新版标准将于2018年1月1日生效 2017 ...
- ALGO-12_蓝桥杯_算法训练_幂方分解(递归)
问题描述 任何一个正整数都可以用2的幂次方表示.例如: =++ 同时约定方次用括号来表示,即ab 可表示为a(b). 由此可知,137可表示为: ()+()+() 进一步:= ++ (21用2表示) ...