python 爬虫学习之路
2016-6-18
--今天实现了第一个用urllib2实现的爬虫程序。
--过程中发现
req = urllib2.Request(url,headers = headers)
总是报错: 主要原因在于 url 地址错误。
例如:http://www.neihan8.com/wenzi/index_1.html
这个网址打开的是404网页错误。
但是 http://www.neihan8.com/wenzi/index_2.html 这个网页却可以了。
源代码如下:
#-*- coding:utf-8 -*-
import urllib2
class Spider:
'''
内涵段子吧。。。
'''
def load_page(self,page):
'''
发送内涵段子url
'''
url = 'http://www.neihan8.com/wenzi/index_'+ str(page) +'.html'
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.63 Safari/537.36"}
req = urllib2.Request(url,headers = headers)
response = urllib2.urlopen(req)
html = response.read()
return html
#main
''' '''
if __name__ == '__main__':
mySpider = Spider()
the_page = mySpider.load_page(2)
print the_page
综上,我们可以在代码中加一个判断 url 是否打开正常的代码,这个需要学习。
-----------------------------------------------------------华丽丽的分割线-------------------------------------------------------------------------------------------------
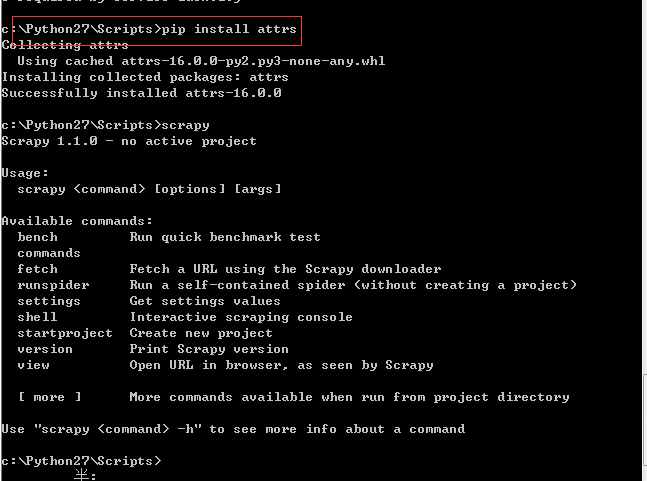
安装Scrapy

--安装scrapy 都要快被安装死了
首先会发现提示 一下问题:
1.版本问题,就是说 Scrapy 所依赖的模块版本太低。'>=1.00' 表明你要使用大于1.0的版本
2.
说明 你有一个包 attrs 没有安装。
那就使用 pip install attrs 安装即可
安装完之后终于正常了。。。。
Python教程:pywin32下载安装
下载链接http://sourceforge.net/projects/pywin32/files/pywin32/Build%20218/pywin32-218.win32-py2.7.exe/download
-------------------------开启爬虫之路----------------------------------------------
首先先说明当中可能遇到的问题:
1.String or binary data would be truncated.解决方法
步骤:在执行插入语句时,会提示上面的error。
原因:是因为数据库中定义的字段长度比较小,在插入或者更新的时候,用一个比这个字段长度大的值去操作,就会引起这个错误。
2.
python向数据库插入中文乱码问题
第一步:数据库那边总得把字段类型设置为utf8之类类的吧。
python 爬虫学习之路的更多相关文章
- python爬虫学习之路-遇错笔记-1
当在运行爬虫时同时开启了Fidder解析工具时(此爬虫并不是用于爬取手机端那内容,而是爬去电脑访问的网页时),访问目标站点会遇到以下错误: File "C:\Users\litao\AppD ...
- python爬虫学习(1) —— 从urllib说起
0. 前言 如果你从来没有接触过爬虫,刚开始的时候可能会有些许吃力 因为我不会从头到尾把所有知识点都说一遍,很多文章主要是记录我自己写的一些爬虫 所以建议先学习一下cuiqingcai大神的 Pyth ...
- python爬虫学习 —— 总目录
开篇 作为一个C党,接触python之后学习了爬虫. 和AC算法题的快感类似,从网络上爬取各种数据也很有意思. 准备写一系列文章,整理一下学习历程,也给后来者提供一点便利. 我是目录 听说你叫爬虫 - ...
- Python爬虫学习:三、爬虫的基本操作流程
本文是博主原创随笔,转载时请注明出处Maple2cat|Python爬虫学习:三.爬虫的基本操作与流程 一般我们使用Python爬虫都是希望实现一套完整的功能,如下: 1.爬虫目标数据.信息: 2.将 ...
- Python爬虫学习:四、headers和data的获取
之前在学习爬虫时,偶尔会遇到一些问题是有些网站需要登录后才能爬取内容,有的网站会识别是否是由浏览器发出的请求. 一.headers的获取 就以博客园的首页为例:http://www.cnblogs.c ...
- Python爬虫学习:二、爬虫的初步尝试
我使用的编辑器是IDLE,版本为Python2.7.11,Windows平台. 本文是博主原创随笔,转载时请注明出处Maple2cat|Python爬虫学习:二.爬虫的初步尝试 1.尝试抓取指定网页 ...
- 《Python爬虫学习系列教程》学习笔记
http://cuiqingcai.com/1052.html 大家好哈,我呢最近在学习Python爬虫,感觉非常有意思,真的让生活可以方便很多.学习过程中我把一些学习的笔记总结下来,还记录了一些自己 ...
- python爬虫学习视频资料免费送,用起来非常666
当我们浏览网页的时候,经常会看到像下面这些好看的图片,你是否想把这些图片保存下载下来. 我们最常规的做法就是通过鼠标右键,选择另存为.但有些图片点击鼠标右键的时候并没有另存为选项,或者你可以通过截图工 ...
- python爬虫学习笔记(一)——环境配置(windows系统)
在进行python爬虫学习前,需要进行如下准备工作: python3+pip官方配置 1.Anaconda(推荐,包括python和相关库) [推荐地址:清华镜像] https://mirrors ...
随机推荐
- MySQL基础之 支持的数据类型
MySQL的数值类型 整数类型 字节 有符号 无符号 TINYINT 1 -128~+127 0~255 SAMLLINT 2 -32768~+32767 0~65535 MEDIUMINT 3 -8 ...
- 《面向对象程序设计》六 GUI
git传送门 我这无药可救的拖延症和懒癌orz 主界面 文件读取界面 提示界面 最初选择vs+mfc,发现许多自动生成的代码读不懂(不须懂),尝试qt后感觉人生迎来了希望,看了推荐的视频与教程稍微了解 ...
- [python]python官方原版编码规范路径
1.进入python官方主页:https://www.python.org/ 2.按如下图进入PEP Index 3.选择第8个,即为python的规范
- 微信小程序点击 navigator ,页面不跳转
1.navigator 对应的 url 必须配置在app.json的pages中: 2.navigator 对应的 url 不能配置在"tabBar"的"list&quo ...
- Mysql表类型(存储引擎)的比较
面试官问:你知道mysql有哪些存储引擎,区别是啥? 我:一脸闷逼,于是乎下来补一补,以作备查 1.和大多数数据库不同,MySQL 中有一个存储引擎的概念,针对不同的存储需求可以选择最优的存储引擎. ...
- 详解coredump
一,什么是coredump 我们经常听到大家说到程序core掉了,需要定位解决,这里说的大部分是指对应程序由于各种异常或者bug导致在运行过程中异常退出或者中止,并且在满足一定条件下(这里为什么说需要 ...
- myeclipse10无法weblogic10.3的问题解决方案
在完成了myec与wl10的基本配置后,启动报如下错误 Parsing Failure in config.xml: java.lang.AssertionError: java.lang.Class ...
- Volley源码分析(一)RequestQueue分析
Volley源码分析 虽然在2017年,volley已经是一个逐渐被淘汰的框架,但其代码短小精悍,网络架构设计巧妙,还是有很多值得学习的地方. 第一篇文章,分析了请求队列的代码,请求队列也是我们使用V ...
- c# winform 自动升级
winform自动升级程序示例源码下载 客户端思路: 1.新建一个配置文件Update.ini,用来存放软件的客户端版本: [update] version=2011-09-09 15:26 2.新 ...
- POJ2104 K-th Number(整体二分)
嘟嘟嘟 整体二分是一个好东西. 理解起来还行. 首先,需要牢记的是,我们二分的是答案,也就是在值域上二分,同时把操作分到左右区间中(所以操作不是均分的). 然后我就懒得讲了-- 李煜东的<算法竞 ...