SQL执行计划详解explain
1.使用explain语句去查看分析结果
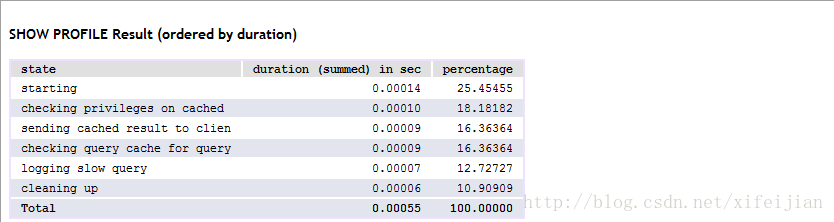
如explain select * from test1 where id=1;会出现:id selecttype table type possible_keys key key_len ref rows extra各列。
其中,
type=const表示通过索引一次就找到了;
key=primary的话,表示使用了主键;
type=all,表示为全表扫描;
key=null表示没用到索引。
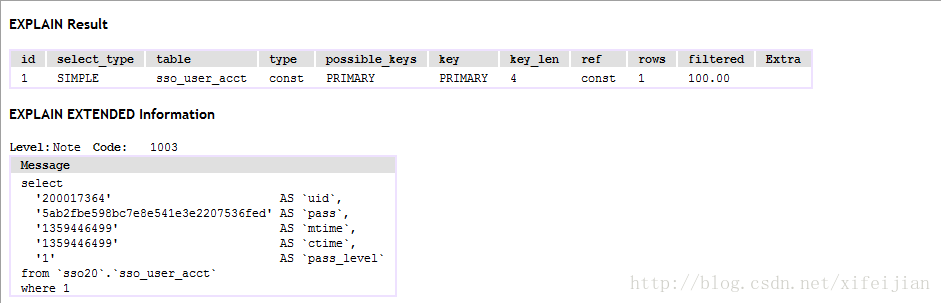
type=ref,因为这时认为是多个匹配行,在联合查询中,一般为REF。
2.MYSQL中的组合索引
假设表有id,key1,key2,key3,把三者形成一个组合索引,则如:
复制代码 代码如下:
- where key1=....
- where key1=1 and key2=2
- where key1=3 and key2=3 and key3=2
根据最左前缀原则,这些都是可以使用索引的,如from test where key1=1 order by key3,用explain分析的话,只用到了normal_key索引,但只对where子句起作用,而后面的order by需要排序。
3.使用慢查询分析(实用)
在my.ini中:
long_query_time=1
log-slow-queries=d:\mysql5\logs\mysqlslow.log
把超过1秒的记录在慢查询日志中
可以用mysqlsla来分析之。也可以在mysqlreport中,有如
DMS分别分析了select ,update,insert,delete,replace等所占的百分比
4.MYISAM和INNODB的锁定
myisam中,注意是表锁来的,比如在多个UPDATE操作后,再SELECT时,会发现SELECT操作被锁定了,必须等所有UPDATE操作完毕后,再能SELECT
innodb的话则不同了,用的是行锁,不存在上面问题。
5.MYSQL的事务配置项
innodb_flush_log_at_trx_commit=1
表示事务提交时立即把事务日志flush写入磁盘,同时数据和索引也更新,很费性能。
innodb_flush_log_at_trx_commit=0
事务提交时,不立即把事务日志写入磁盘,每隔1秒写一次,MySQL挂了可能会丢失事务的数据。
innodb_flush_log_at_trx_commit=2 ,在整个操作系统 挂了时才可能丢数据,一般不会丢失超过1-2秒的更新。
事务提交时,立即写入磁盘文件(这里只是写入到系统内核缓冲区,但不立即刷新到磁盘,而是每隔1秒刷新到磁盘,同时更新数据和索引),这种方案是不是性价比好一些,当然如何配置,决定于你对系统数据安全性的要求。
使用explain关键字可以模拟优化器执行SQL查询语句,从而知道MySQL是如何处理你的SQL语句的,分析你的查询语句或是表结构的性能瓶颈。
explain执行计划包含的信息
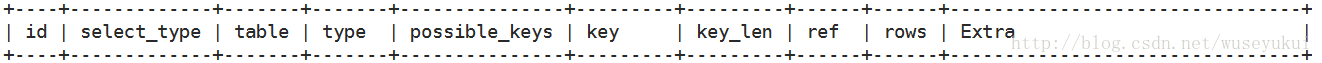
其中最重要的字段为:id、type、key、rows、Extra
各字段详解
id
select查询的序列号,包含一组数字,表示查询中执行select子句或操作表的顺序
三种情况:
1、id相同:执行顺序由上至下

2、id不同:如果是子查询,id的序号会递增,id值越大优先级越高,越先被执行

3、id相同又不同(两种情况同时存在):id如果相同,可以认为是一组,从上往下顺序执行;在所有组中,id值越大,优先级越高,越先执行

select_type
查询的类型,主要是用于区分普通查询、联合查询、子查询等复杂的查询
1、SIMPLE:简单的select查询,查询中不包含子查询或者union
2、PRIMARY:查询中包含任何复杂的子部分,最外层查询则被标记为primary
3、SUBQUERY:在select 或 where列表中包含了子查询
4、DERIVED:在from列表中包含的子查询被标记为derived(衍生),mysql或递归执行这些子查询,把结果放在零时表里
5、UNION:若第二个select出现在union之后,则被标记为union;若union包含在from子句的子查询中,外层select将被标记为derived
6、UNION RESULT:从union表获取结果的select
type
访问类型,sql查询优化中一个很重要的指标,结果值从好到坏依次是:
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
一般来说,好的sql查询至少达到range级别,最好能达到ref
1、system:表只有一行记录(等于系统表),这是const类型的特例,平时不会出现,可以忽略不计
2、const:表示通过索引一次就找到了,const用于比较primary key 或者 unique索引。因为只需匹配一行数据,所有很快。如果将主键置于where列表中,mysql就能将该查询转换为一个const

3、eq_ref:唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配。常见于主键 或 唯一索引扫描。
注意:ALL全表扫描的表记录最少的表如t1表

4、ref:非唯一性索引扫描,返回匹配某个单独值的所有行。本质是也是一种索引访问,它返回所有匹配某个单独值的行,然而他可能会找到多个符合条件的行,所以它应该属于查找和扫描的混合体
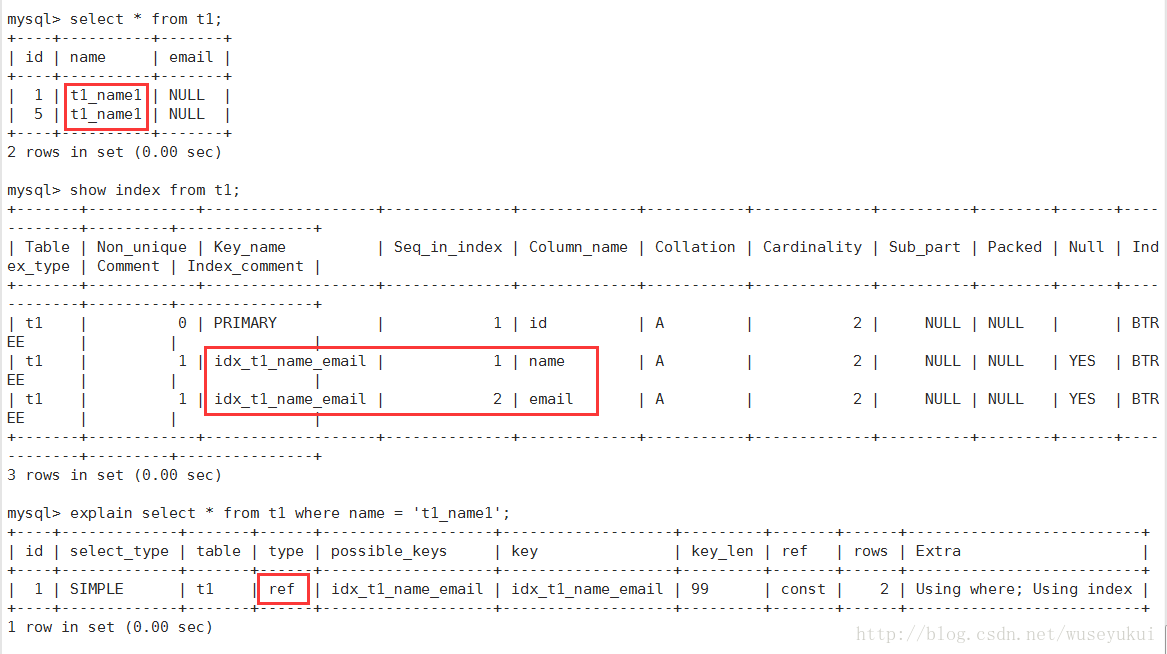
5、range:只检索给定范围的行,使用一个索引来选择行。key列显示使用了那个索引。一般就是在where语句中出现了bettween、<、>、in等的查询。这种索引列上的范围扫描比全索引扫描要好。只需要开始于某个点,结束于另一个点,不用扫描全部索引

6、index:Full Index Scan,index与ALL区别为index类型只遍历索引树。这通常为ALL块,应为索引文件通常比数据文件小。(Index与ALL虽然都是读全表,但index是从索引中读取,而ALL是从硬盘读取)

7、ALL:Full Table Scan,遍历全表以找到匹配的行

possible_keys
查询涉及到的字段上存在索引,则该索引将被列出,但不一定被查询实际使用
key
实际使用的索引,如果为NULL,则没有使用索引。
查询中如果使用了覆盖索引,则该索引仅出现在key列表中
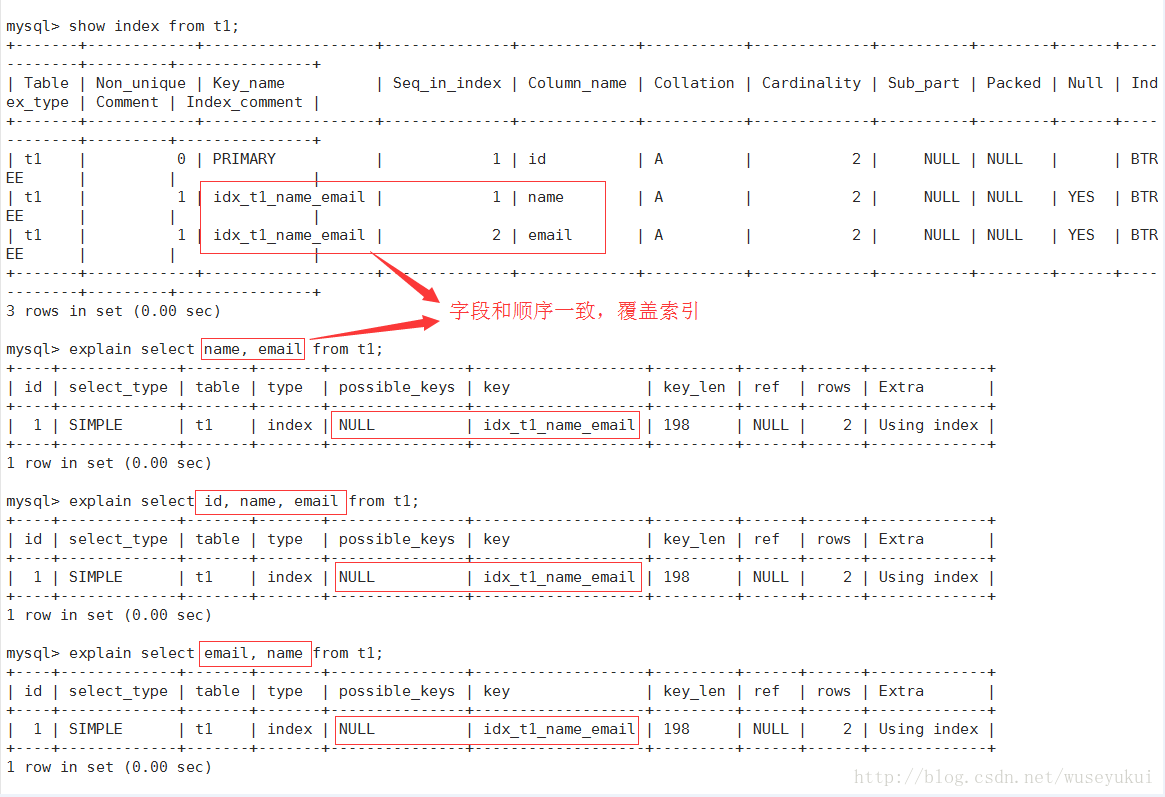

key_len
表示索引中使用的字节数,查询中使用的索引的长度(最大可能长度),并非实际使用长度,理论上长度越短越好。key_len是根据表定义计算而得的,不是通过表内检索出的
ref
显示索引的那一列被使用了,如果可能,是一个常量const。
rows
根据表统计信息及索引选用情况,大致估算出找到所需的记录所需要读取的行数
Extra
不适合在其他字段中显示,但是十分重要的额外信息
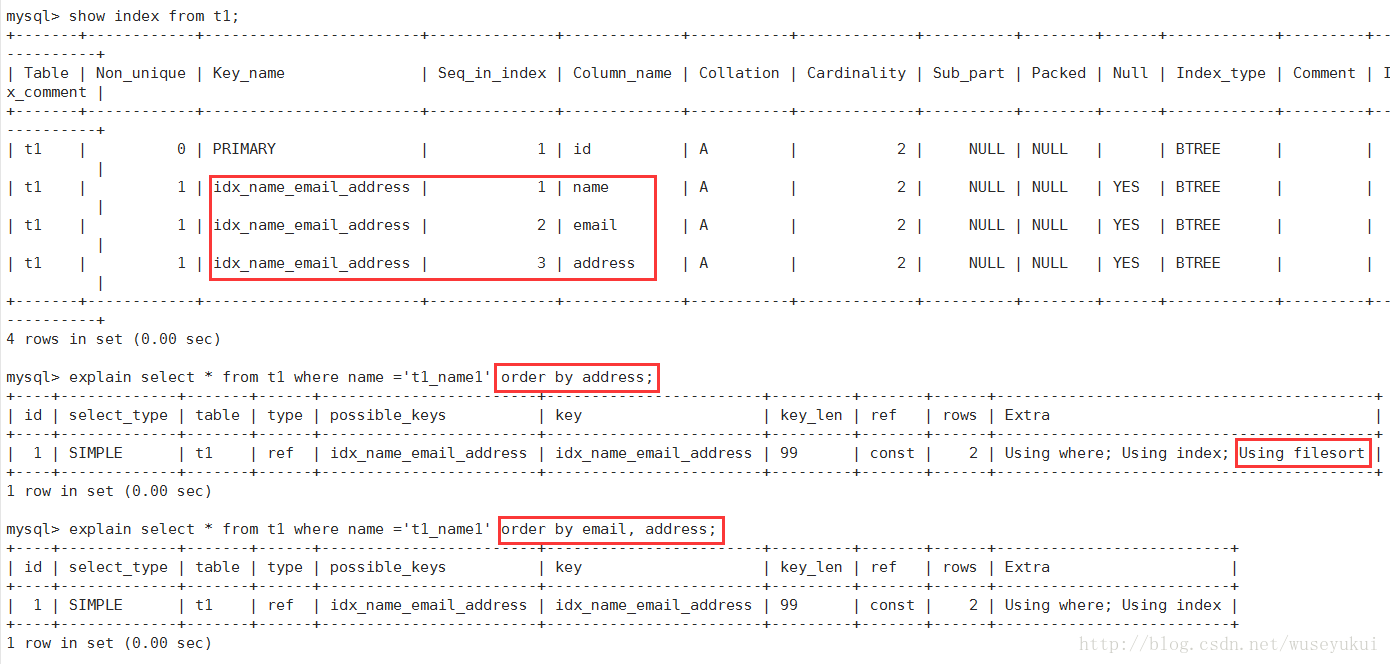
1、Using filesort :
mysql对数据使用一个外部的索引排序,而不是按照表内的索引进行排序读取。也就是说mysql无法利用索引完成的排序操作成为“文件排序”
由于索引是先按email排序、再按address排序,所以查询时如果直接按address排序,索引就不能满足要求了,mysql内部必须再实现一次“文件排序”
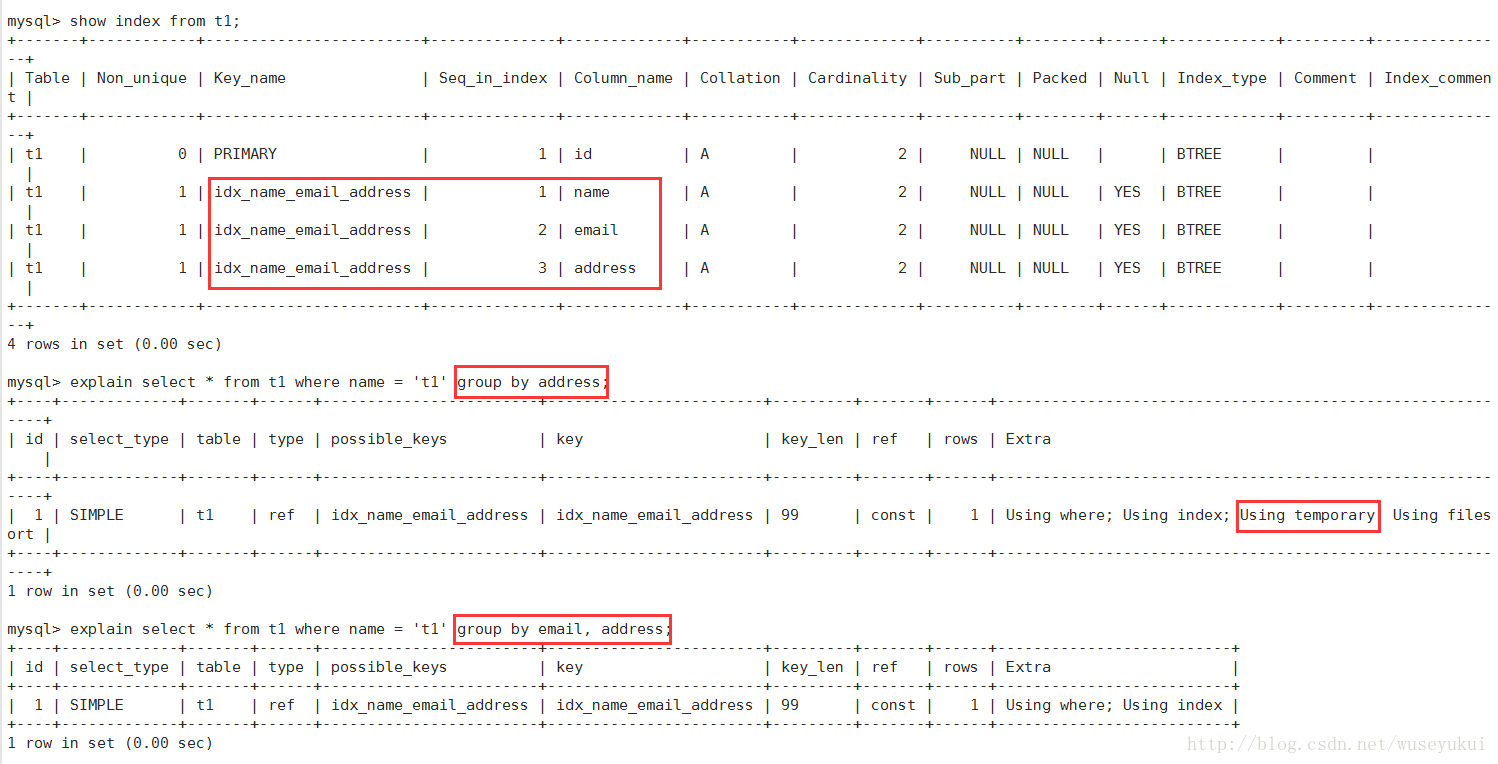
2、Using temporary:
使用临时表保存中间结果,也就是说mysql在对查询结果排序时使用了临时表,常见于order by 和 group by
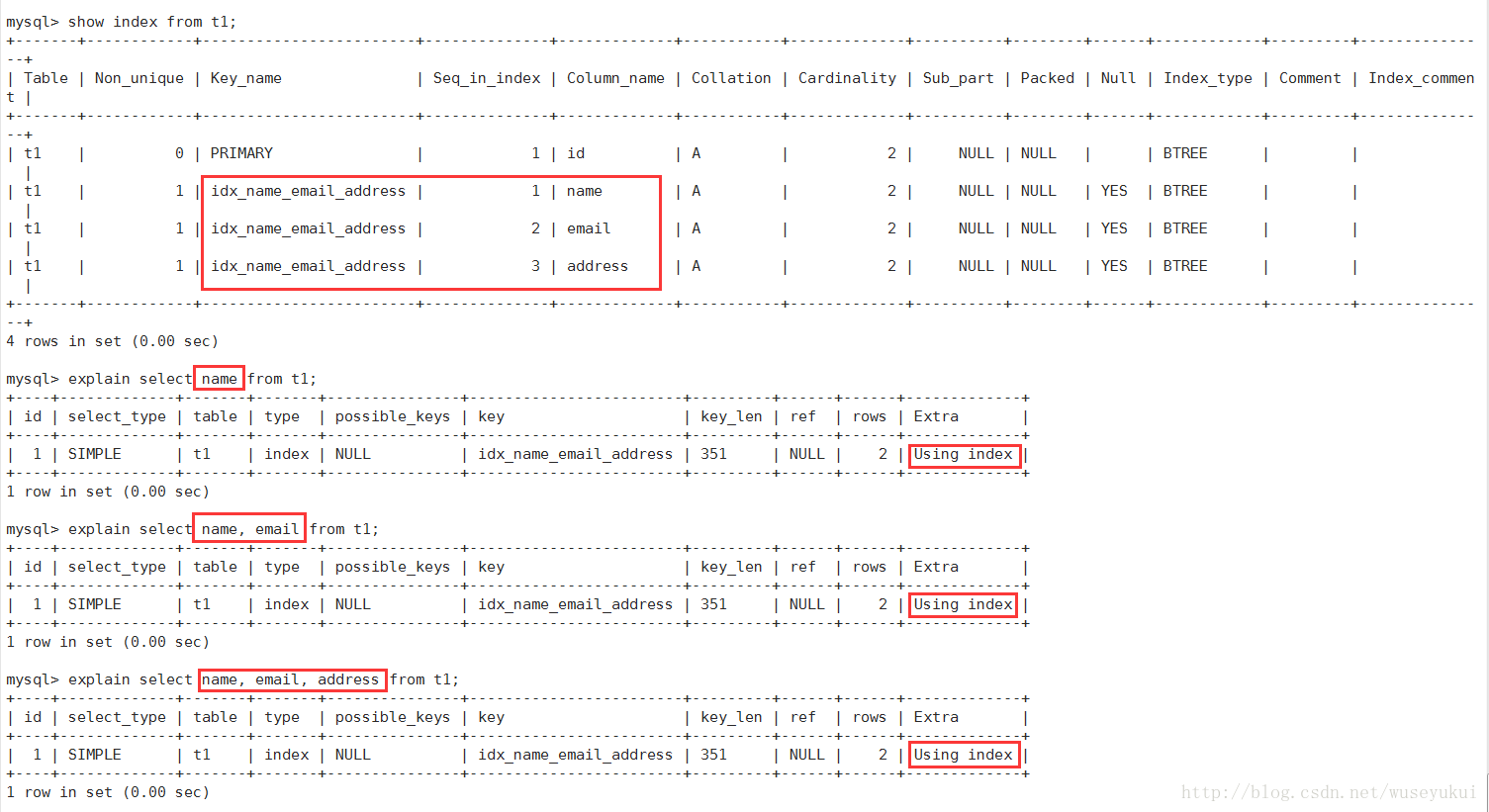
3、Using index:
表示相应的select操作中使用了覆盖索引(Covering Index),避免了访问表的数据行,效率高
如果同时出现Using where,表明索引被用来执行索引键值的查找(参考上图)
如果没用同时出现Using where,表明索引用来读取数据而非执行查找动作
覆盖索引(Covering Index):也叫索引覆盖。就是select列表中的字段,只用从索引中就能获取,不必根据索引再次读取数据文件,换句话说查询列要被所建的索引覆盖。
注意:
a、如需使用覆盖索引,select列表中的字段只取出需要的列,不要使用select *
b、如果将所有字段都建索引会导致索引文件过大,反而降低crud性能
4、Using where :
使用了where过滤
5、Using join buffer :
使用了链接缓存
6、Impossible WHERE:
where子句的值总是false,不能用来获取任何元祖

7、select tables optimized away:
在没有group by子句的情况下,基于索引优化MIN/MAX操作或者对于MyISAM存储引擎优化COUNT(*)操作,不必等到执行阶段在进行计算,查询执行计划生成的阶段即可完成优化
8、distinct:
优化distinct操作,在找到第一个匹配的元祖后即停止找同样值得动作
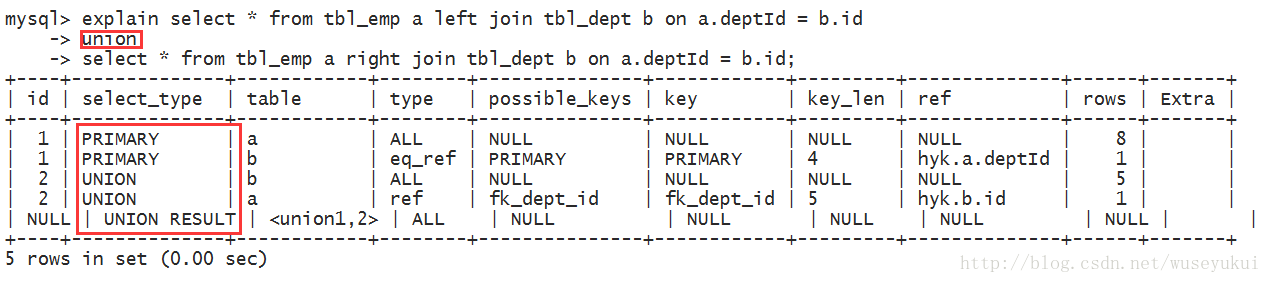
综合Case

执行顺序
1(id = 4)、【select id, name from t2】:select_type 为union,说明id=4的select是union里面的第二个select。
2(id = 3)、【select id, name from t1 where address = ‘11’】:因为是在from语句中包含的子查询所以被标记为DERIVED(衍生),where address = ‘11’ 通过复合索引idx_name_email_address就能检索到,所以type为index。
3(id = 2)、【select id from t3】:因为是在select中包含的子查询所以被标记为SUBQUERY。
4(id = 1)、【select d1.name, … d2 from … d1】:select_type为PRIMARY表示该查询为最外层查询,table列被标记为 “derived3”表示查询结果来自于一个衍生表(id = 3 的select结果)。
5(id = NULL)、【 … union … 】:代表从union的临时表中读取行的阶段,table列的 “union 1, 4”表示用id=1 和 id=4 的select结果进行union操作。
SQL执行计划详解explain的更多相关文章
- mysql的sql执行计划详解(非常有用)
以前没有怎么了解mysql执行计划,以及sql 优化方面,今天算学习了. https://blog.csdn.net/heng_yan/article/details/78324176 https:/ ...
- mysql的sql执行计划详解
实际项目开发中,由于我们不知道实际查询的时候数据库里发生了什么事情,数据库软件是怎样扫描表.怎样使用索引的,因此,我们能感知到的就只有 sql语句运行的时间,在数据规模不大时,查询是瞬间的,因此,在写 ...
- MySQL性能分析, mysql explain执行计划详解
MySQL性能分析 MySQL性能分析及explain用法的知识是本文我们主要要介绍的内容,接下来就让我们通过一些实际的例子来介绍这一过程,希望能够对您有所帮助. 1.使用explain语句去查看分析 ...
- Oracle执行计划详解
Oracle执行计划详解 --- 作者:TTT BLOG 本文地址:http://blog.chinaunix.net/u3/107265/showart_2192657.html --- 简介: ...
- [转]Oracle执行计划详解
Oracle执行计划详解 --- 作者:TTT BLOG 本文地址:http://blog.chinaunix.net/u3/107265/showart_2192657.html --- 简介: ...
- MySQL 执行计划详解
我们经常使用 MySQL 的执行计划来查看 SQL 语句的执行效率,接下来分析执行计划的各个显示内容. EXPLAIN SELECT * FROM users WHERE id IN (SELECT ...
- mysql中SQL执行过程详解与用于预处理语句的SQL语法
mysql中SQL执行过程详解 客户端发送一条查询给服务器: 服务器先检查查询缓存,如果命中了缓存,则立刻返回存储在缓存中的结果.否则进入下一阶段. 服务器段进行SQL解析.预处理,在优化器生成对应的 ...
- Mysql探索之Explain执行计划详解
前言 如何写出效率高的SQL语句,提到这必然离不开Explain执行计划的分析,至于什么是执行计划,如何写出高效率的SQL,本篇文章将会一一介绍. 执行计划 执行计划是数据库根据 SQL 语句和相关表 ...
- MySql——Explain执行计划详解
使用explain关键字可以模拟优化器执行SQL查询语句,从而知道MySQL是如何处理你的SQL语句的,分析你的查询语句或是表结构的性能瓶颈. explain执行计划包含的信息 其中最重要的字段为:i ...
随机推荐
- LOJ 2978 「THUSCH 2017」杜老师——bitset+线性基+结论
题目:https://loj.ac/problem/2978 题解:https://www.cnblogs.com/Paul-Guderian/p/10248782.html 第 i 个数的 bits ...
- 登录成功后如何利用cookie保持登录状态
Cookie是一种服务器发送给浏览器的一组数据,用于浏览器跟踪用户,并访问服务器时保持登录状态等功能. 通常用户登录的时候,服务器根据用户名和密码在服务器数据库中校验该用户是否正确,校验正确后则可以根 ...
- 使用selenium+BeautifulSoup 抓取京东商城手机信息
1.准备工作: chromedriver 传送门:国内:http://npm.taobao.org/mirrors/chromedriver/ vpn: selenium BeautifulSo ...
- VB.NET导出Excel 轻松实现Excel的服务器与客户端交换 服务器不安装Office
说来VB.Net这个也是之前的一个项目中用到的.今天拿来总结下用途,项目需求,不让在服务器安装Office办公软件.这个也是煞费了一顿. 主要的思路就是 在导出的时候,利用DataTable做中间变量 ...
- 使用nsenter进入docker容器后端报错 mesg: ttyname failed: No such file or directory
通过nsenter 进入到docker容器的后端总是报下面的错,, [root@devdtt ~]# docker inspect -f {{.State.Pid}} mynginx411950 [r ...
- Django中执行原生SQL语句【新编辑】
参考我的个人博客 这部分迁移到了个人博客中:Django中执行原生SQL语句 这里需要补充一下,还有一个extra方法: ret = models.Student.objects.all().extr ...
- R 数据分析
目录: windows命令行中执行R dataframe 常用函数.变量 1.windows命令行中执行R 前提:已经把R的命令目录加入了系统路径中. 在windows中,命令行执行R可以用以下两种方 ...
- obj文件中的关键字
obj文件使用的关键字 关键字 含义 v 表示本行指定一个顶点,此关键字后跟着3个单精度浮点数,分别表示该顶点的X.Y.Z坐标值 vt 表示本行指定一个纹理坐标,此关键字后跟着两个单精度浮点数,分别表 ...
- mysql捕捉所有SQL语句
MySQL可以通过开通general_log参数(可动态修改)来扑捉所有在数据库执行的SQL语句.显示参数:mysql> show variables like 'general%log%';+ ...
- spring cloud学习--eureka 02
开启eureka client的注解@EnableDiscoveryClient的功能类DiscoveryClient梳理图 获取server url位于类EndpointUtils的getServi ...