又是图论.jpg
BZOJ 2200 道路和航线重讲ww:
FJ 正在一个新的销售区域对他的牛奶销售方案进行调查。他想把牛奶送到 T 个城镇 (1 ≤ T ≤ 25000),编号为 1 到 T。这些城镇之间通过 R 条道路 (1 ≤ R ≤ 50000) 和 P 条航线(1 ≤ P ≤ 50000) 连接。每条道路 i 或者航线 i 连接城镇 Ai 到Bi,花费为 Ci。对于道路, 0 ≤ Ci ≤ 10000; 然而航线的花费很神奇,花费 Ci 可能是负数 (-10000 ≤ Ci ≤ 10000)。道路是双向的,可以从 Ai 到 Bi,也可以从 Bi 到 Ai,花费都是 Ci。然而航线与之不同,只可以从 Ai 到 Bi。事实上,由于最近恐怖主义太嚣张,为了社会和谐,出台了一些政策保证:如果有一条航线可以从 Ai 到 Bi,那么保证不可能通过一些道路和航线从 Bi 回到Ai。(有向边不存在于任何一个环,环都是正权无向边)由于 FJ 的奶牛世界公认〸分给力,他需要运送奶牛到每一个城镇。他想找到从发送中心城镇 S 把奶牛送到每个城镇的最便宜的方案,或者知道这是不可能的。 (求从s出发到某个点的单源最短路);O(nlogn)
把所有无向边加进去,形成若干连通块,看成一个大的点,然后加入有向边,形成一个DAG,如果有连通块的入度为0,直接连通块内跑dijkstar:以已更新的dis为基础ww,有向边按拓扑序dp,更新dis,连通块内部使用dijkstar来做;
连通块内怎么跑dijkstar:当有多个点dis已经更新时,将被更新的dis不为正无穷的点扔进堆中,然后跑dijkstar;
POJ 1125 Stockbroker Grapevine
有 N 个股票经济人可以互相传递消息,他们之间存在一些单向的通信路径。现在有一个消息要由某个人开始传递给其他所有人,问应该由哪一个人来传递,才能在最短时间内让所有人都接收到消息。
跑Floyd计算全局最短路,然后计算每个人单源最短路的和,取最小的一个,就是应该被用来传递信息的人ww;
POJ 1502 MPI Maelstrom
给出 N 个处理器之间传递信息所需时间矩阵的下三角,求信息从第一个处理器传到其它所有处理器所需时间最大值。 (原题求的是最小值)
给出了下三角矩阵,就可以知道任意两个处理器之间的时间,显然就是一个单源最短路的问题了。
如何求单源最长路:把单源最短路的小于号改成大于号;
POJ 1511 Invitation Cards
N 个点 M 条边的有向图,询问对于所有 i,从点 1 出发到点 i 并返回点 1 所需时间最小值。
ww:正向建图 + 单源最短路
反向建图 + 单源最短路
然后相加;
POJ 1724 ROADS
有 N 个城市和 M 条单向道路,每条道路有长度和收费两个属性。求在总费用不超过 K 的前提下从城市 1 到城市 N 的最短路。
写一个普通的dijkstra,多维护一个走的费用是多少,超过k就continue;
把点多开一些,建n*k个点。然后每个点记录两个条件,分别为编号和到达这个点时的费用。
那么对于一条边<u,v>,假设权值为w,费用为c,那么我们可以从u的每一个花费费用向v对应的连一条边,然后正常的跑dijkstra就可以了√
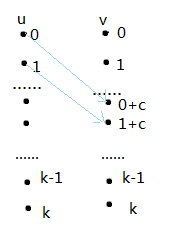
POJ 1797 Heavy Transportation
给出 N 个点 M 条边的无向图,每条边有最大载重。
求从点 1 到点 N 能通过的最大重量(也就是求路径的最小边权最大)。
二分:二分答案,假设最大载重>=mid,那么我们只能通过限重>=mid的边,将其加入图中,如果从1=>n可以通过说明可行,把答案增加;
dij:\(if(dis[v]<min(dis[u],w_{(u,v)})) dis[v]=min(dis[u],w_{(u,v)});\)
Kruscal:跑最大生成树(边权从大到小排序w)
POJ 1062 昂贵的聘礼
(题面太长,移步 http://poj.org/problem?id=1062)
总的花费:1个原价+优惠价ww;
替代关系是边,优惠价格是长度,从某物品出发交换至酋长允诺就是一条路径
不考虑地位限制:
我们把优惠之间建边:<u,v,w>表示u=>v有一条长度为w的边,也就表示我得到u物品后再买v物品价格是w;从某一个点出发走到1就是一种方案,然后要求最短路;
考虑反向建边,跑1到其它点的最短路;
考虑有等级限制的情况:
我们可以考虑枚举哪一段区间,其中区间长度为M,
但是由于这个毒瘤ych可能会给出很大的等级,所以如果枚举M可能会炸掉,我们考虑到N只有100,枚举N是个不错的选择,只需要算某一个地位的人+M这段区间就好啦√
枚举地位等级区间,不在地位等级区间内的点不可经过,枚举量 O(N)
BZOJ 3040 最短路 *
N 个点, M 条边的有向图,求点 1 到点 N 的最短路(保证存在)。
1 ≤ N ≤ 1000000, 1 ≤ M ≤ 10000000
By lydrainbowcat
边集分为两部分:
随机生成
输入给出
采用高效的堆来优化 Dijkstra 算法。
斐波那契堆
配对堆
https://paste.ubuntu.com/p/Mp2fXMKv8J/
事实上,忽略随机生成的边(这些边占大部分)亦可得到正确的解。
https://paste.ubuntu.com/p/NHvZXTGnZp/
最小生成树
Prim
死活不会Prim
将所有点分为两个集合,已经和点 1 连通的集合 S、未和点1 连通的集合 T
计算集合 T 中每个点 u 和集合 S 的距离,
\(d_u =min_{<u,v>∈E,v∈S}\{w_{u,v}\}\)
选取集合 T 中距离 S 最近的点 u,选中对应的边,加入集合 S
重复上面的过程,直到所有点都被加入集合 S
朴素写法时间复杂度较劣,可以采用堆优化至 \(O((N + M)logN)\)
Prim 是一个基于贪心的算法,可以采用归纳法和反证法证明其正确性。
首先证明第一条选中的边 e1 一定包含在某最优解方案中
如果最优解中不包含边 e1,则加入 e1 一定会出现环,且环上存在比 e1 大的边,用 e1 替换之答案更优
假设最优解包含前 k 个选中的边, e1, e2, . . . , ek,则类似地可证明 ek+1 存在于最优解中
运用归纳法, Prim 算法得到的 n - 1 条边构成最优解
Kruscal
将所有边按照边权从小到大排序
依次考虑每一条边 \(< u_i, v_i >\),如果这条边和之前选中的边形成环,则不选中此边;反之,选中此边
当考虑遍所有边后,选中的边一定构成了一棵最小生成树
需要并查集的支持,时间复杂度一般认为是 O(MlogM)
放弃证明.jpg
拟阵最优化问题:将集合中每个元素赋予一个权值,求权值和最小 (大) 的极大独立集。
拟阵最优化的贪心算法:
维护当前独立集 G,初始为空。将元素按照权值排序,从小到大枚举元素 x,若 G ∪ {x} 是一个独立集,那么就将 x 加入独立集并将 x 的权值累加入答案。最后的结果就是权值和最小的极大独立集。
POJ 1258 Agri-Net
有 N 个村庄,村庄之间形成完全图。现给出邻接矩阵,选择总长度尽可能小的边将 N 个村庄连通。
就是跑一个最小生成树呗w;
POJ 2421 Constructing Roads
有 N 个村庄,有一些道路已经存在,现在希望用最少的总长度将所有村庄连通。
将已经存在道路设置长度为 0,然后跑最小生成树;
POJ 2560 Freckles
给出平面上 N 个点,求将所有点连通的最小距离和
\(O(N^2)\) 建边,对所有点两两求距离连边,然后跑最小生成树;
POJ 1789 Truck History
有 N 个编号,每个编号均为 7 位数。两个编号之间的距离定义为其不同位个数,由一个编号生成另一个编号代价为两个编号的距离。希望用最小总代价从某一编号开始生成所有编号。
\(O(N^2)\)建边,然后求最小生成树;
BZOJ 1601 灌水
Farmer John 已经决定把水灌到他的 n(1 ≤ n ≤ 300) 块农田,农田被数字 1 到 n 标记。把一块土地进行灌水有两种方法,从其他农田引水,或者这块土地建造水库。建造一个水库需要花费wi(1 ≤ wi ≤ 100000), 连接两块土地需要花费\(p_{i,j}\)(1 ≤ \(p_{i,j}\) ≤ 100000,$ p_{i,j} =p_{j,i}, p_{i,i} = 0$). 计算 Farmer John 所需的最少代价。
建立超级水库点,在某点建立水库视为选择长度为 wi 的边将其和超级水库连通, 引水就是选择连接一个长度为 pi,j 的,由i指向j的边。目标是选择长度和尽可能小的边,使得所有点和超级水库连通。
所以就是跑最小生成树呗?
BZOJ 2753 滑雪与时间胶囊
a 来到雪山滑雪,这里分布着 M 条供滑行的轨道和 N 个轨道之间的交点 (同时也是景点),而且每个景点都有一编号 i 和一高度Hi。 a 能从景点 i 滑到景点 j 当且仅当存在一条 i 和 j 之间的边,且 i 的高度不小于 j。 a 喜欢用最短的滑行路径去访问尽量多的景点。如果仅仅访问一条路径上的景点,他会觉得数量太少。于是 a 拿出了他随身携带的时间胶囊。这是一种很神奇的药物,吃下之后可以立即回到上个经过的景点(不用移动也不被认为是 a滑行的距离)。请注意,这种神奇的药物是可以连续食用的,即能够回到较长时间之前到过的景点(比如上上个经过的景点和上上上个经过的景点)。现在, a 站在 1 号景点望着山下的目标,心潮澎湃。他〸分想知道在不考虑时间胶囊消耗的情况下,以最短滑行距离滑到尽量多的景点的方案 (即满足经过景点数最大的前提下使得滑行总距离最小)。你能帮他求出最短距离和景点数吗?
能够到达的景点容易通过 DFS 或 BFS 求出。
将不能到达的点删去,保证剩余点全部可以到达ww;
走过的所有边一定没有环,要不然我们可以用时间胶囊ww;
最优解应当构成树形,所需要的时间即为所有边长度之和。易联想到用最小生成树 Kruskal 算法解决本问题。
以到达点高度为第一关键字,边长度为第二关键字。到达点高度高的边优先,同样高时边长度短的优先。 第一关键字从大到小排序,第二关键字从小到大排序;
BZOJ 2561 最小生成树 *
给定一个边带正权的连通无向图 G =< V, E >,其中N = |V |, M =|E|, N 个点从 1 到 N 依次编号,给定三个正整数 u, v, L (u , v),假设现在加入一条边权为 L 的边 (u, v),那么需要删掉最少多少条边,才能够使得这条边既可能出现在最小生成树上,也可能出现在最大生成树上?
前置技能:网络流最小割
官方gugu,最为致命;
树上倍增
有根树(随意定根)
最近公共祖先
链上信息(和、最值)
优秀的时间复杂度
序列倍增
回忆普通的序列倍增思想,以 ST 表为例。
\(F_{i,j}\) 记录区间 \([i, i + 2^j - 1]\) 内信息(区间和或区间最值)
\(F_{i,j} = merge(F_{i,j-1}, F_{i+2^j-1,j-1})\)
取出区间 [l, r] 答案时,使用若干个 \(F_{i,j}\) 即可
如果求区间最值,那么取$ F_{l,k} \(和\) F_{r-2^k ,k}$ 即可,其中
\(k= ⌊lo g_2(r - l + 1)⌋\)
如果求区间和,可以取 \(F_{l,k1}, F_{l+2^{k1},k2}, F_{l+2^{k1}+2^{k2} ,k3},\) . . . 即可
树上倍增
树上从每个点出发到根结点的链也具有类似的形式。
\(F_{i,j}\) 表示点 i 向上走$ 2^j$ 步的结点
\(F_{i,0}\) 就是点 i 的父亲节点
$F_{i,j} =F_{F_{i,j-1},j-1} $
如何求解 u 向上移动 k 步是哪个点?
将 k 写作 2 的幂次之和,如 \(11 =2^3 + 2^1 + 2^0\)。
用 \(G_{i, j}\) 表示 i 向上移动 j 步的结果。
\(G_{u,11}= F_{_{Gu,10},0}\)
\(G_{u,10}= F_{_{Gu,8},1}\)
\(G_{u,8}= F_{u,3}\)
在 O(logN) 步内完成。
树上倍增最常见的用处是求解两个点的最近公共祖先。
求解 a 和 b 的最近公共祖先:
将 a 和 b 调整到相同高度
判断 a 和 b 是否重合,若重合则该点即为答案
令 a 和 b 一起向上移动尽可能大的距离,保证移动后两点不重合
此时两点的父亲结点即为答案
单次询问时间复杂度 O(logN)
如何处理\(f[i][j]\)
dfs处理:显然要记录父亲\(f[i][0]=fa\),对于每个点进行for循环:
for(int j=1;j<=20;j++)
f[i][j]=f[f[i][j-1]][j-1];//大概没写错ww
LCA的常见求解方法有:
树上倍增
树链剖分
DFS序+RMQ
DFS序+RMQ:
定义一个长度为2n的数组,在dfs中,如果我们第一次经过一个点,把其加入数组中,如果我们回溯时再次经过一个点,再一次把它加入数组中,那么对于两个点的LCA x来说,x在数组中只会在这两个点中间出现一次,并且是深度最小的。那么通过这样,我们就可以用ST表预处理(O(nlogn)),得到每个区间的ans;
向上路径
如何求解从 u 到 v 路径上边权最值?保证 v 是 u 的祖先。
\(M_{i,j}\) 表示点 i 出发向上移动 \(2^j\) 步经过边权最值
\(M_{i,0} =W_{i, f ather_i}\)
\(M_{i,j} =merge(M_{i,j-1}, M_{F_{i,j-1},j-1})\)
在树上倍增向上走时取移动区间最值更新答案即可
树上路径
记 g= LCA(u, v),则树上从 u 到 v 的路径可以拆分为两段:
从 u 到 g 的路径
从 g 到 v 的路径
如何求解从 u 到 v 路径上的边权和?
将路径拆分为两段向上路径,分别求解其答案再合并。
树链剖分
树链:不拐弯的路径
剖分:每个点属于一条链
应当具有优良的性质。
重儿子:子树大小最大的子结点
重链:从一点出发,一直选择重儿子向下走,走到叶子
轻边:不属于任何一条重链的边
从任意一点 u 走到根结点,经过的重链条数、轻边个数的量级是多少?
走一条重链、轻边,子树大小至少翻倍,故易知 O(logN)。
每跳一条轻边,子树大小都会增加为原来的两倍;所以最多只有logN条轻边;
一些记号
\(dep_u\) 表示点 u 的深度
\(fat_u\) 表示点 u 的父亲节点
\(top_u\) 表示点 u 所在重链的顶端结点
\(dfn_u\) 表示重儿子优先 DFS 下点 u 的时间戳
\(end_u\)表示重儿子优先 DFS 下点 u 子树最大时间戳
\(size_u\)表示以u为根的子树里的结点个数
\(son_u\)表示u的重儿子
两次dfs:1.统计子树大小,确定重儿子
2.剖重链
void dfs1(int u,int fa){
dep[u]=dep[fa]+1;
fat[u]=fa;
size[u]=1;
int v,num=0;
for(int i=head[u];i;i=edge[i].nxt){
v=edge[i].to;
if(v!=fa) dfs1(v,u);
size[u]+=size[v];
if(size[v]>num) son[u]=v,num=size[v];
}
}
void dfs2(int u,int fa){
dfn[u]=++cnt;
if(u==son[fa]) top[u]=top[f];
else top[u]=u;
if(son[u]) dfs2(son[u],u);
int v;
for(int i=head[u];i;i=edge[i].nxt){
v=edge[i].to;
if(v!=fa&&v!=son[u]) dfs2(v,u);
}
end[u]=cnt;
}
树链剖分求LCA:
求点 a 和点 b 的最近公共祖先。
记 \(ta =top_a, tb = top_b\)
如果 ta =tb,则 a 和 b 在同一条重链,深度较小的为 LCA
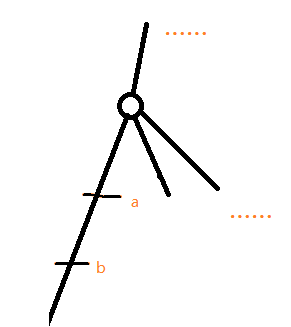
如果ta!=tb:
- 如果 \(dep_{ta} > dep_{tb}\),那么令 \(a =f at_{ta}\)
- 如果 \(dep_{ta} < dep_{tb}\),那么令$ b =f at_{tb}$
树的结构较为复杂,相较而言我们更喜欢序列这样的一维结构,因为有丰富的数据结构及其它算法可以处理序列上的种种问题。那么能否将树转化为序列以便维护信息?如果按照 \(d f n_u\) 将树转化为序列,有哪些有用的性质?
- 子树是序列中连续一段
- 树上路径由 O(logN) 个区间组成
SPOJ QTREE Query on a tree
You are given a tree (an acyclic undirected connected graph)with N nodes, and edges numbered 1, 2, 3 . . . N - 1.We will ask you to perfrom some instructions of the following
form:
- CHANGE i ti : change the cost of the i-th edge to ti
- QUERY a b : ask for the maximum edge cost on the pathfrom node a to node b
- 给定一棵n个节点的树,有两个操作:
- CHANGE i ti 把第i条边的边权变成ti
- QUERY a b 输出从a到b的路径中最大的边权,当a=b的时候,输出0
几个需要注意的点:
1.线段树建树是在dfn序的基础上。
2.查询的时候记得找lca;
#include<bits/stdc++.h>
using namespace std;
const int mxn=100010;
const int mxm=200010;
int dep[mxn],dfn[mxn],fat[mxn];
int top[mxn],son[mxn];
int size[mxn],head[mxn],num[mxn];
int n,cntt;
struct Node{
int u,v,w;
}e[mxm];
struct node{
int to,nxt,dis;
}ed[mxm];
struct nd{
int l,r,val;
}tr[mxm<<2];
void add(int from,int to){
++cntt;
ed[cntt].to=to;
ed[cntt].nxt=head[from];
head[from]=cntt;
}
void dfs1(int u,int fa){
dep[u]=dep[fa]+1;
size[u]=1;
fat[u]=fa;
son[u] = 0;
for(int i=head[u],v;i;i=ed[i].nxt){
v=ed[i].to;
if(v!=fa) {
dfs1(v,u);
size[u]+=size[v];
if (size[v] > size[son[u]])
son[u] = v;
}
}
}
int cnt;
void dfs2(int u,int fa){
dfn[u]=++cnt;
if(son[fa]==u) top[u]=top[fa];
else top[u]=u;
if(son[u]) dfs2(son[u],u);
for(int i=head[u];i;i=ed[i].nxt){
int v=ed[i].to;
if(v!=fa&&v!=son[u]) dfs2(v,u);
}
return;
}
void build(int k,int l,int r){
tr[k].l=l;
tr[k].r=r;
if(l==r){
tr[k].val=num[l];
return;
}
int mid=(l+r)>>1;
build(k<<1,l,mid);
build(k<<1|1,mid+1,r);
tr[k].val=max(tr[k<<1].val,tr[k<<1|1].val);
}
int query(int k,int x,int y){
if(x>y) return 0;
if(tr[k].l==x&&tr[k].r==y)
return tr[k].val;
int mid=(tr[k].r+tr[k].l)>>1;
int ans=0;
if(y<=mid) return query(k << 1, x, y);
if(x>mid) return query(k << 1 | 1, x, y);
else return max(query(k << 1, x, mid), query(k << 1 | 1, mid + 1, y));
}
int getans(int a,int b){
int ret = 0;
while (top[a] != top[b]){
int ta = top[a];
int tb = top[b];
if (dep[ta] > dep[tb])
ret = max(ret, query(1, dfn[ta], dfn[a])), a = fat[ta];
else
ret = max(ret, query(1, dfn[tb], dfn[b])), b = fat[tb];
}
if (dep[a] < dep[b])
swap(a, b);
ret = max(ret, query(1, dfn[b] + 1, dfn[a]));
return ret;
}
void change(int k,int p,int w){
if(tr[k].l==tr[k].r){
tr[k].val=w;
return;
}
int mid=(tr[k].l+tr[k].r)>>1;
if(p<=mid) change(k<<1,p,w);
else change(k<<1|1,p,w);
tr[k].val=max(tr[k<<1].val,tr[k<<1|1].val);
return;
}
int main(){
scanf("%d",&n);
int u,v,w;
for(int i=1;i<n;i++){
scanf("%d%d%d",&u,&v,&w);
e[i].u=u;
e[i].v=v;
e[i].w=w;
add(u,v);add(v,u);
}
dfs1(1,0);
dfs2(1,0);
num[1]=0;//因为是将边权赋给到达点,而dfn序中的第一个显然是没有入度的,那么就是0;
for(int i=1;i<n;i++){
if(dep[e[i].u]>dep[e[i].v])
num[dfn[e[i].u]]=e[i].w;
else
num[dfn[e[i].v]]=e[i].w;
}
build(1,1,n);
char s[100];
int a,b,i,it;
while(1){
scanf("%s",s);
if(s[0]=='D') break;
if(s[0]=='Q'){
scanf("%d%d",&a,&b);
printf("%d\n",getans(a,b));
}
if(s[0]=='C'){
scanf("%d%d",&i,&it);
if(dep[e[i].u]>dep[e[i].v])
change(1,dfn[e[i].u],it);
else
change(1,dfn[e[i].v],it);
}
}
return 0;
}
树链剖分 + 线段树维护区间最大值
BZOJ 4034
有一棵点数为 N 的树,以点 1 为根,且树点有权。然后有 M个操作,分为三种:
- 把某个节点 x 的点权增加 a 。
- 把某个节点 x 为根的子树中所有点的点权都增加 a 。
- 询问某个节点 x 到根的路径中所有点的点权和。
树链剖分 + 线段树单点加、区间加、区间求和
BZOJ 2243 染色
给定一棵有 n 个节点的无根树和 m 个操作,操作有 2 类:
将节点 a 到节点 b 路径上所有点都染成颜色 c
询问节点 a 到节点 b 路径上的颜色段数量(连续相同颜色被认为是同一段),例:“112221”由 3 段组成:“11”、“222”和“1”。
请你写一个程序依次完成这 m 个操作。
树链剖分 + 线段树
- 维护子区间内颜色段树数
- 合并时判断左子区间最右点和右子区间最左点颜色是否相同
- 树链剖分查询答案时还要判断上一条链和本条链相邻结点颜色是否相同
BZOJ 2238 MST
给出一个 N 个点 M 条边的无向带权图,以及 Q 个询问,每次询问在图中删掉一条边后图的最小生成树。 (各询问间独立,每次询问不对之后的询问产生影响,即被删掉的边在下一条询问中依然存在)
如果不在最小生成树上,显然不会产生影响;
如果在最小生成树上,树被分成了两块,寻找权值最小的非树边来代替删去的边;
强连通分量
在有向图中,如果两个点之间存在两个方向的路径,则称两个点强连通;如果有向图的任何两个顶点都强连通,则称其为强连通图;有向图的极大强连通子图即为强连通分量。
缩点
强连通分量最常见的用途是将能互相到达的点集缩为一个新的点,建立的新图一定是有向无环图。
Tarjan 算法
Tarjan 算法可以在 O(N + M) 的时间复杂度内求解有向图的所有强连通分量。
首先提取出有向图的一棵搜索树作为基础框架。
$d f n_u $为 u 点的 DFS 时间戳
\(low_u\) 为 u 点出发能追溯到的最小时间戳
\(low_u=min(dfn_u,low_{v1},dfn_{v2})\)
其中\(<u,v_1>\)为树枝边,\(<u,v_2>\)为后向边
BZOJ 2208 连通数
度量一个有向图的连通情况的一个指标是连通数,指图中可达的顶点对数量。
例如下图中连通数为 14。
现希望求出给定图的连通数。
N ≤ 2000

一个scc内的点互相可达,对答案的贡献:\(k^2\)(自己到自己也算w)
把每个scc缩成一个点,然后变成了DAG,拓扑排序,求每个scc可以到达哪个scc;
对每个点i建一个长度为2000的bitset,其中的第k位的1/0值表示编号为i的点能否到达点k。然后结果就是:
\(\sum\limits_{i=1}^{连通块数量}size[i](\sum\limits_{k=1}^{连通块数量}size[k]) \ \ 其中,bit_i[k]=1;\)
\(bit_i\)表示第i个连通块的bitset,size[i]表示此连通块有几个点;
bitset压位???
bitset:
bitset<100000> a; //长度为10^5的二进制数ww;
bitset<100000> b;
//下标a[0~99999];
//可以赋值,可以访问,支持位运算:a&b
a.set();//
a.reset(); //清零
a.count();//有多少位是1
POJ 2186 Popular Cows
每头牛都有一个梦想:成为一个群体中最受欢迎的名牛!在一个有 N(1 ≤ N ≤ 10000) 头牛的牛群中,给你 M(1 ≤ M ≤ 50000)个二元组 (A,B), 表示 A 认为 B 是受欢迎的。既然受欢迎是可传递的,那么如果 A 认为 B 受欢迎, B 又认为 C 受欢迎, 则 A 也会认为 C 是受欢迎的,哪怕这不是〸分明确的规定。你的任务是计算被所有其它的牛都喜欢的牛的个数
显然做过www,直接gugu没意见叭
POJ 1236 Network of Schools
给定 N 所学校和网络,每个学校收到软件后会分发给相邻的学校(单向边)。
求:
- 若选取一些学校分发软件使得所有学校都可收到,所需最少分发学校数
- 若要使任选一所学校分发软件,所有学校都可收到,最少新增边数
1.选所有入度为0的点;
2.先化成DAG,算入度为0的点有多少个,出度为0的点有多少个,取更大的就是答案w;
又是图论.jpg的更多相关文章
- UVA 10054 The Necklace
完全就是哭瞎的节奏···QAQ 又是图论··· 题意:有一种项链,每个珠子上有两种颜色,相同颜色的两颗珠子的两头相连,如果能连成环输出珠子的顺序,不能连成环输出"some beads may ...
- OI总结
当下考的钟声叮当响起,该走了,一年半的OI竞赛就此结束 留下了很多遗憾.也拥有过一段美好的竞赛生活 结识了一群优秀的OI战友,一起进步一起开心一起忧愁,但这一切的一切都将在今晚变成过去式,CSp的好与 ...
- 记第一场cf比赛(Codeforces915)
比赛感想 本来21:05开始的比赛,结果记成21:30了...晚了25分钟才开始[捂脸] 这次是Educational Round,所以还比较简单. 前两道题一眼看去模拟+贪心,怕错仔细看了好几遍题, ...
- JSOI2021 酱油记
Day -24 - 2021.3.16 终于停课了(bushi)-- 稍微规划了下省选前听课的日程,大约周二(3.16)请一天,周四(3.18)请一天,周五(3.19)请半天?月考正常考,月考完请两周 ...
- Cocos2d-x 地图步行实现1:图论Dijkstra算法
下一节<Cocos2d-x 地图行走的实现2:SPFA算法>: http://blog.csdn.net/stevenkylelee/article/details/38440663 本文 ...
- CJOJ 1070 【Uva】嵌套矩形(动态规划 图论)
CJOJ 1070 [Uva]嵌套矩形(动态规划 图论) Description 有 n 个矩形,每个矩形可以用两个整数 a, b 描述,表示它的长和宽.矩形 X(a, b) 可以嵌套在矩形 Y(c, ...
- codechef Sum of Cubes 图论
正解:图论+数学 解题报告: 先放个传送门QwQ 然后放下题目大意?就说给定简单图,无自环或重边,然后求(∑e[i][j])k,i,j∈S,S为点集的子集 然后因为k的取值只有[1,3],所以这里分类 ...
- 用深度优先搜索(DFS)解决多数图论问题
前言 本文大概是作者对图论大部分内容的分析和总结吧,\(\text{OI}\)和语文能力有限,且部分说明和推导可能有错误和不足,希望能指出. 创作本文是为了提供彼此学习交流的机会,也算是作者在忙碌的中 ...
- DP&图论 DAY 4 上午
DP&图论 DAY 4 上午 概率与期望 概率◦某个事件A发生的可能性的大小,称之为事件A的概率,记作P(A).◦假设某事的所有可能结果有n种,每种结果都是等概率,事件A涵盖其中的m种,那 ...
随机推荐
- 对items函数的理解
老师:dict的items应该是把dict转成列表,每个列表元素是一个包含key ,value的dict,元素应该是元组, {a:1, b:2, c:3} [(a, 1), (b,2), (c, ...
- The Preliminary Contest for ICPC Asia Shanghai 2019 B. Light bulbs
题目:https://nanti.jisuanke.com/t/41399 思路:差分数组 区间内操作次数为奇数次则灯为打开状态 #include<bits/stdc++.h> using ...
- CF191C Fools and Roads - 树剖解法
Codeforces Round #121 (Div. 1) C. Fools and Roads time limit per test :2 seconds memory limit per te ...
- (69)Python异常处理与断言
http://blog.csdn.net/pipisorry/article/details/21841883 断言 断言是一句必须等价于布尔真的判定;此外,发生异常也意味着表达式为假.这些工作类似于 ...
- Linux shell - shift命令用法(转载)
位置参数可以用shift命令左移.比如shift 3表示原来的$4现在变成$1,原来的$5现在变成$2等等,原来的$1.$2.$3丢弃,$0不移动.不带参数的shift命令相当于shift 1. 非常 ...
- MySort的实现
代码: package week12; import java.util.*; import java.lang.Integer; public class MySort{ public static ...
- 无法加载模块 TP3.2
报错 3.2的路由功能是针对模块设置的,所以URL中的模块名不能被路由,路由定义也通常是放在模块配置文件中. 'MODULE_DENY_LIST' => array('Common','User ...
- Text Classification
Text Classification For purpose of word embedding extrinsic evaluation, especially downstream task. ...
- c# SQLite 判断表、字段是否存在的方法,新增、删除、重命名列
SQLiteHelper class: using System; using System.Collections.Generic; using System.Text; using System. ...
- 开发-日常工具:TFS(Team Foundation Server)
ylbtech-开发-日常工具:TFS(Team Foundation Server) TFS(Team Foundation Server)是一个高可扩展.高可用.高性能.面向互联网服务的分布式文件 ...