Appscan工作原理详解
AppScan,即 AppScan standard edition。其安装在 Windows 操作系统上,可以对网站等 Web 应用进行自动化的应用安全扫描和测试。
- 通过搜索(爬行)发现整个 Web 应用结构
- 根据分析,发送修改的 HTTP Request 进行攻击尝试(扫描规则库)
- 通过对于 Respone 的分析验证是否存在安全漏


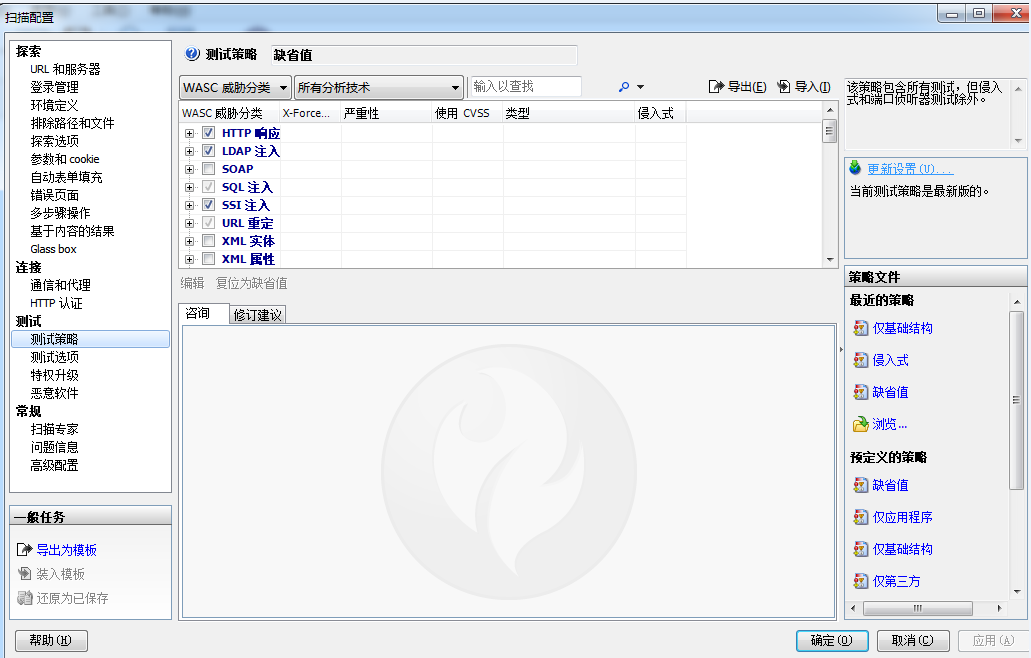
- 扫描配置信息:扫描配置信息,如扫描的目标网站地址,录制的登陆过程脚本等,选择的扫描设置等都保存在 Scan 文件中。
- 所有访问到页面信息:针对每个发现的页面,即使没有进行测试,在探索过程也会访问该页面并纪录 http request/response 信息;所以如果探索的页面访问的时候返回的页面内容比较多,页面比较大,那么即使只做了探索根本没有扫描,整个 Scan 文件也会很大。
- 测试阶段,记录测试成功的测试变体和页面访问信息:针对每个页面都会发送多次测试(测试变体),每次测试都会有 Request/response 信息,这些信息如果测试通过,即发现了一个安全问题,则会把该测试变体对应得 request/response 都会纪录下来,保存在 .scan 文件中;由于 AppScan 的扫描测试用例库全面,对于每种安全威胁漏洞,都会发送多个安全测试变体(Variant)进行测试,比如对于 XSS 问题,AppScan 发送了 100 个变体,其中 30 个执行失败,70 个变体执行成功,则会纪录 70 次执行成功的具体变体信息,以及每个变体对应的 Request/Response 信息。这就是一个很大的数据量。这些信息保存以后,就可以在不连接在网站的情况下进行结果分析,快速显示当时测试的页面快照等。

- 网站规模(页面个数,页面参数)
- 扫描策略的选择
- 扫描设置
- 选择合适的,最小化的扫描规则
- 分解扫描任务,把一个大的扫描任务分解为多个小的扫描任务
- 根据页面特点,设置可以过滤的类似页面(冗余页面)
Appscan工作原理详解的更多相关文章
- 块级格式化上下文(block formatting context)、浮动和绝对定位的工作原理详解
CSS的可视化格式模型中具有一个非常重要地位的概念——定位方案.定位方案用以控制元素的布局,在CSS2.1中,有三种定位方案——普通流.浮动和绝对定位: 普通流:元素按照先后位置自上而下布局,inli ...
- log4j-over-slf4j工作原理详解
log4j-over-slf4j工作原理详解 摘自:https://blog.csdn.net/john1337/article/details/76152906 置顶 2017年07月26日 17: ...
- 【AppScan】入门工作原理详解
AppScan,即 AppScan standard edition.其安装在 Windows 操作系统上,可以对网站等 Web 应用进行自动化的应用安全扫描和测试.Rational AppScan( ...
- AppScan入门工作原理详解
AppScan,即 AppScan standard edition.其安装在 Windows 操作系统上,可以对网站等 Web 应用进行自动化的应用安全扫描和测试. Rational AppScan ...
- ASP.NET页面与IIS底层交互和工作原理详解
转载自:http://www.cnblogs.com/lidabo/archive/2012/03/13/2393200.html 第一回: 引言 我查阅过不少Asp.Net的书籍,发现大多数作者都是 ...
- ASP.NET页面与IIS底层交互和工作原理详解(第一回)
引言 我查阅过不少Asp.Net的书籍,发现大多数作者都是站在一个比较高的层次上讲解Asp.Net.他们耐心.细致地告诉你如何一步步拖放控件.设置控件属性.编写CodeBehind代码,以实现某个特定 ...
- 交换机工作原理、MAC地址表、路由器工作原理详解
一:MAC地址表详解 说到MAC地址表,就不得不说一下交换机的工作原理了,因为交换机是根据MAC地址表转发数据帧的.在交换机中有一张记录着局域网主机MAC地址与交换机接口的对应关系的表,交换机就是根据 ...
- HTTP响应报文与工作原理详解
超文本传输协议(Hypertext Transfer Protocol,简称HTTP)是应用层协议.HTTP 是一种请求/响应式的协议,即一个客户端与服务器建立连接后,向服务器发送一个请求;服务器接到 ...
- 【转】HTTP响应报文与工作原理详解
超文本传输协议(Hypertext Transfer Protocol,简称HTTP)是应用层协议.HTTP 是一种请求/响应式的协议,即一个客户端与服务器建立连接后,向服务器发送一个请求;服务器接到 ...
随机推荐
- 2018微信小程序开发遇到的坑
第一个坑:wx.showModal(OBJECT) wx.showModal在安卓手机里,如果点击遮罩的话会关闭弹窗,不会有任何回调.而苹果的情况下则是点击遮罩不会有任何反应. 这样会有什么问题呢? ...
- [洛谷P4438] HNOI2018 道路
问题描述 W 国的交通呈一棵树的形状.W 国一共有n - 1个城市和n个乡村,其中城市从1到n - 1 编号,乡村从1到n编号,且1号城市是首都.道路都是单向的,本题中我们只考虑从乡村通往首都的道路网 ...
- 12 Spring Boot密码加密算法
- 多数据源(sql server 2008,二个数据库不ip,)
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.sp ...
- adb打开系统设置的命令
adb命令打开手机设置页面 设置主页面adb shell am start com.android.settings/com.android.settings.Settings 安全adb shell ...
- CF F. Royal Questions kruskal
每一个 $A$ 必须和指定的唯一的 $B$ 匹配,转化成图论关系就是 $A$ 和 $B$ 之间有若干条连边,每个边有一个边权,而该边权只能代表一对 $A,B$. 这其实就是一个基环树的结构. 所以只需 ...
- SQL—事物
[选择题]以下哪个选项是DBMS的基本单位,是构成单一逻辑工作单元的操作集合. A.进程 B.SQL C.事务 D.文件 分析: (1)一个事务包含一个或多个SQL语句,是逻辑管理的工作单元(原子单元 ...
- Distinctive Image Features from Scale-Invariant Keypoints(SIFT) 基于尺度不变关键点的特征描述子——2004年
Abstract摘要本文提出了一种从图像中提取特征不变性的方法,该方法可用于在对象或场景的不同视图之间进行可靠的匹配(适用场景和任务).这些特征对图像的尺度和旋转不变性,并且在很大范围的仿射失真.3d ...
- maven入门问题解决
记录入门使用maven的问题和解决方法: 一.用mvn clean compile编译报错/ 或者在IDE中编译时,Problem视图显示错误:无法从maven服务器或者私有服务器或者某个网站中中下载 ...
- SQL的一对多,多对一,一对一,多对多什么意思?
1.一对多:比如说一个班级有很多学生,可是这个班级只有一个班主任.在这个班级中随便找一个人,就会知道他们的班主任是谁:知道了这个班主任就会知道有哪几个学生.这里班主任和学生的关系就是一对多. 2.多对 ...