Solr单机环境搭建及部署
一、定义
官网的定义:
Solr是基于Lucene构建的流行,快速,开放源代码的企业搜索平台。它具有高度的可靠性,可伸缩性和容错能力,可提供分布式索引,复制和负载平衡查询,自动故障转移和恢复,集中式配置等。 Solr支持许多世界上最大的互联网站点的搜索和导航功能。
简单的理解solr就是一款搜索框架,通常用实现查询功能,比如电商网站的商品检索。
二、环境搭建
本文基于以下开源组件版本搭建,约定下载后组件和解压缩的文件都放置在/opt目录下:
solr-8.2.0
apache-tomcat-8.5.47
首先下载solr-8.2.0.tgz,可以使用wget命令:
wget http://mirrors.tuna.tsinghua.edu.cn/apache/lucene/solr/8.2.0/solr-8.2.0.tgz
解压缩:
tar -zxvf solr-8.2.0.tgz -C .
解压后,/opt目录下会多一个solr-8.2.0目录
下载apache-tomcat-8.5.47:
wget https://mirrors.tuna.tsinghua.edu.cn/apache/tomcat/tomcat-8/v8.5.47/bin/apache-tomcat-8.5.47.tar.gz
解压缩:
tar -zxvf apache-tomcat-8.5.47.tar.gz
为了将solr部署到tomcat服务器,不使用solr自带的jetty,首先在/opt目录下创建一个目录用于部署solr服务,名称无限制,这里取名solr了。
mkdir solr
复制一份tomcat到/opt/solr目录下,重命名为tomcat8
cp -r apache-tomcat-8.5.47 solr/tomcat8
solr本质是一个web服务,我们将它复制到tomcat8下:
cp -r solr-8.2.0/server/solr-webapp/webapp solr/tomcat8/webapps/solr
复制solr-8.2.0/server/lib/ext下的部分jar到solr目录中,为了简便可以完全复制所有的,然后忽略掉disruptor-3.4.2.jar
cp solr-8.2.0/server/lib/ext/* solr/tomcat8/webapps/solr/WEB-INF/lib/
复制solr-8.2.0/server/lib下以metrics开头的jar到solr目录:
cp solr-8.2.0/server/lib/metrics* solr/tomcat8/webapps/solr/WEB-INF/lib/
上面这两项注意是复制到solr服务的lib目录下,不是复制到tomcat8/lib下。
复制solr-8.2.0/server/resources下的log4j*.xml文件到solr
首先在solr创建classes目录:
mkdir solr/tomcat8/webapps/solr/WEB-INF/classes
复制日志配置文件:
cp solr-8.2.0/server/resources/log4j2*.xml solr/tomcat8/webapps/solr/WEB-INF/classes/
将solr-8.2.0/server/solr目录复制到solr/目录下,并重命名为solrhome:
cp -r solr-8.2.0/server/solr solr/solrhome
修改日志路径
vim solr/tomcat8/webapps/solr/WEB-INF/classes/log4j2.xml
指定fileName和filePattern的路径:
<RollingRandomAccessFile
name="MainLogFile"
fileName="/opt/solr/solrhome/log/solr.log"
filePattern="/opt/solr/solrhome/log/solr.log.%i" >
<PatternLayout>
....
关联solr及solrhome
修改solr里的web.xml文件
vim solr/tomcat8/webapps/solr/WEB-INF/web.xml
web.xml中<web-app></web-app>标签内添加如下配置,指定sorlhome路径
<env-entry>
<env-entry-name>solr/home</env-entry-name>
<env-entry-value>/opt/solr/solrhome</env-entry-value>
<env-entry-type>java.lang.String</env-entry-type>
</env-entry>
注释掉下方的下列配置:
<!--
<security-constraint>
<web-resource-collection>
<web-resource-name>Disable TRACE</web-resource-name>
<url-pattern>/</url-pattern>
<http-method>TRACE</http-method>
</web-resource-collection>
<auth-constraint/>
</security-constraint>
<security-constraint>
<web-resource-collection>
<web-resource-name>Enable everything but TRACE</web-resource-name>
<url-pattern>/</url-pattern>
<http-method-omission>TRACE</http-method-omission>
</web-resource-collection>
</security-constraint>
-->
最后启动tomcat,访问服务器的solr服务:
sh solr/tomcat8/bin/start.sh
访问地址:
localhost:8080/solr/index.html
三、配置IK分词器
首先从IK分词器下载与solr版本匹配的jar包,并放置在solr服务的lib目录下,
cp ik-analyzer-8.2.0.jar solr/tomcat8/webapps/solr/WEB-INF/lib/
在solr/solrhome/下创建目录test_core,拷贝配置文件到test_core中:
cp -r solr/solrhome/configsets/sample_techproducts_configs/conf/ solr/solrhome/test_core/
修改conf中的solr.xml文件,修改jar路径:
<lib dir="${solr.install.dir:../}/contrib/extraction/lib" regex=".*\.jar" />
<lib dir="${solr.install.dir:../}/dist/" regex="solr-cell-\d.*\.jar" />
<lib dir="${solr.install.dir:../}/contrib/clustering/lib/" regex=".*\.jar" />
<lib dir="${solr.install.dir:../}/dist/" regex="solr-clustering-\d.*\.jar" />
<lib dir="${solr.install.dir:../}/contrib/langid/lib/" regex=".*\.jar" />
<lib dir="${solr.install.dir:../}/dist/" regex="solr-langid-\d.*\.jar" />
<lib dir="${solr.install.dir:../}/dist/" regex="solr-ltr-\d.*\.jar" />
<lib dir="${solr.install.dir:../}/contrib/velocity/lib" regex=".*\.jar" />
<lib dir="${solr.install.dir:../}/dist/" regex="solr-velocity-\d.*\.jar" />
修改managed-schema文件,添加ik分词器配置:
<!-- ik分词器 -->
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="true" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
重启solr服务,打开管理界面,添加test_core:
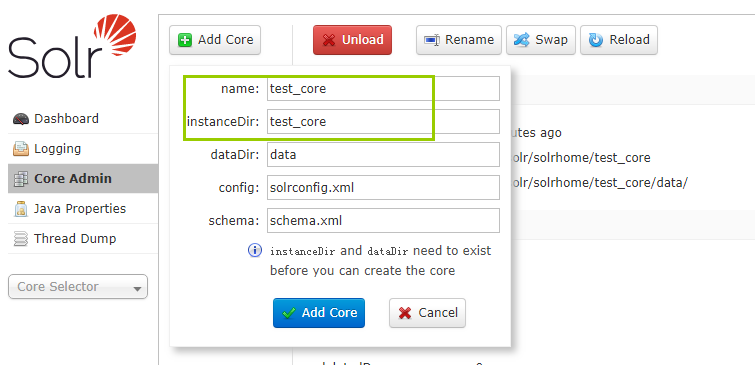
打开管理界面,分词示例:

Solr单机环境搭建及部署的更多相关文章
- Kafka 0.7.2 单机环境搭建
Kafka 0.7.2 单机环境搭建当下载完Kafka后,进行解压,其目录结构如下: bin config contrib core DISCLAIMER examples lib lib_manag ...
- Solr4.8.0源码分析(4)之Eclipse Solr调试环境搭建
Solr4.8.0源码分析(4)之Eclipse Solr调试环境搭建 由于公司里的Solr调试都是用远程jpda进行的,但是家里只有一台电脑所以不能jpda进行调试,这是因为jpda的端口冲突.所以 ...
- windows7 spark单机环境搭建及pycharm访问spark
windows7 spark单机环境搭建 follow this link how to run apache spark on windows7 pycharm 访问本机 spark 安装py4j ...
- [转载] Hadoop和Hive单机环境搭建
转载自http://blog.csdn.net/yfkiss/article/details/7715476和http://blog.csdn.net/yfkiss/article/details/7 ...
- 2-1 RHEL6.5 环境搭建与部署
第二部分:Linux常见服务管理 2-1 RHEL6.5 环境搭建与部署 第二部分主要讲解的是开源服务搭建 学习方法与注意事项: 1. 端正态度,开始学习 2. 认真完成作业和实验(并详细记录) 3. ...
- kafka单机环境搭建及其基本使用
最近在搞kettle整合kafka producer插件,于是自己搭建了一套单机的kafka环境,以便用于测试.现整理如下的笔记,发上来和大家分享.后续还会有kafka的研究笔记,依然会与大家分享! ...
- solr单机环境配置并包含外部单机zookeeper
首先和之前一样下载solr-5.3.1.tgz,然后执行下面命令释放文件并放置在/usr/目录下: $ .tgz $ /usr/ $ cd /usr/solr- 这个时候先不用启动solr,因为单机模 ...
- Mac系统STF自动化环境搭建及部署踩坑记录
因为公司需要寻找一个免root的自动化测试方案,所以以前做的老方案需要被替代.一阵搜寻找到了这个框架,但是部署起来很是折腾,搞了一下午终于搞定,顺便记录一下过程,有需要的自取. 转载请注明出处:htt ...
- HBase单机环境搭建
在搭建HBase单机环境之前,首先你要保证你已经搭建好Java环境: $ java -version java version "1.8.0_51" Java(TM) SE Run ...
随机推荐
- [19/06/06-星期四] HTML基础_文本标签、列表(有序、无序、定义)、文本格式化(单位、字体、大小写、文本修饰、间距、对齐文本)
一.文本标签 em:用来表示一段内容的着重点,语气上的强调.一般显示为斜体 i:是斜体显示,和em显示效果一样.h5规定不需要着重的内容而是单纯加粗或斜体可以用i或b.用的不多 strong:用来表示 ...
- 剑指Offer编程题(Java实现)——两个链表的第一个公共结点
题目描述: 输入两个链表,找出它们的第一个公共结点. 思路一: 设 A 的长度为 a + c,B 的长度为 b + c,其中 c 为尾部公共部分长度,可知 a + c + b = b + c + a. ...
- 执行命令npm publish报错:403 Forbidden - PUT https://registry.npmjs.org/kunmomotest2 - You cannot publish over the previously published versions: 0.0.1.
前言 执行命令npm publish报错:403 Forbidden - PUT https://registry.npmjs.org/kunmomotest2 - You cannot publis ...
- Socket通讯-C#客户端与Java服务端通讯(发送消息和文件)
设计思路 使用websocket通信,客户端采用C#开发界面,服务端使用Java开发,最终实现Java服务端向C#客户端发送消息和文件,C#客户端实现语音广播的功能. Java服务端设计 packag ...
- 认识一下Qt用到的开发工具
http://c.biancheng.net/view/3868.html Qt 不是凭空产生的,它是基于现有工具链打造而成的,它所使用的编译器.链接器.调试器等都不是自己的,Qt 官方只是开发了上层 ...
- Eclipse开发工具的编码问题
乱码:文件有一个编码,打开文件的工具(Eclipse或者浏览器)有一个编码,当两个编码不同就会出现编码异常或乱码. 参考: Eclipse修改编码格式 背景:在Eclipse的开发使用中,我们经常使用 ...
- MySQL新增用户及赋予权限
创建用户 USE mysql; #创建用户需要操作 mysql 表 # 语法格式为 [@'host'] host 为 'localhost' 表示本地登录用户,host 为 IP地址或 IP 地址区间 ...
- 这两天老是有兄弟问到Vue的登陆和注册,登陆成功留在首页,没有登录回到登录页面,现在我用最简单实用的方法实现(两分钟技就看懂)
其实登录注册,并且登录一次保持登录的状态,是每个项目都需要实现的功能. 网上也有很多的方法,不过,不是通俗易懂,在这里说一下我自己的方法,非常简单实用核心就是用localStorage存.取数据,这样 ...
- ipsec概念理解
互联网安全协议(英语:Internet Protocol Security,缩写:IPsec): 本质上一个协议包,透过对IP协议的分组进行加密和认证来保护IP协议的网络传输协议族(一些相互关联的协议 ...
- python中strftime和strptime函数
strftime和strptime函数均来自包datetime from datetime import * strftime: 将datetime包中的datetime类,按照入参格式生成字符串变量 ...