6.集成算法boosting----AdaBoost算法
1.提升算法
提升算法实为将一系列单一算法(如决策树,SVM等)单一算法组合在一起使得模型的准确率更高。这里先介绍两种Bagging(代表算法随机森林),Boosting(代表算法AdaBoost-即本篇核心)
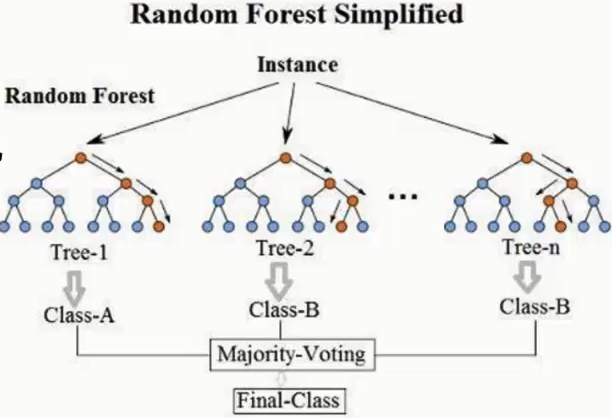
Bagging思想:以随机森林为例
假设样本集的总样本量为100个,每个样本有10个特征(也就是维度是10);随机取样的比例一般为(60%-80%)
步骤1 :我们随机从中拿出60个数据(注意这里是有放回的取样)用于建立决策树,这样随机取50次,最终将会形成60棵决策树。
步骤2: 我们在构建决策树时对于每个决策树的特征也采用随机取样(有放回),随机选6个特征。
步骤3:利用上述步骤1,步骤2构建的60个不同的决策树模型,最终结果用这60棵综合区评判,如下图(图片来此网络):
Boosting思想:在分类问题中,通过改变训练样本的权重,学习多个分类器,并将这些分类器进行线性组合,提高分类的性能(后文以AdaBoost进行说明)。
Bagging与Boosting的异同点:
同:两者都是集成算法,即综合考虑更过的分类器,提高分类的准确性
异:分类器层面:比如一个20人的工作小组,现在要对某一问题达成一项决议。现在开会讨论,Bagging是一视同仁的,即不论工作经验多少,能力怎样,我看多数,后者取平均。而Boosting会根据能力或者说经验的多少综合评定给每个工程师一个权重,也就说能力强的,有经验的权重就大一些,他们的意见就重要一些。在这个基础上再去决策(注意这此示例只针对分类器层面)。
样本层面:Boosting也会给予样本一定的权重。如果从结构层面。
模型结构层面:Bagging是并行决策的(可类比并联电路),而Boosting是串行决策的。
2.AdaBoost算法
2.1 AdaBoost原理以及形成过程
AdaBoost算法的感悟,我在整理时,想采用一种倒立的方式去记录和解读,因为我自己在学习的过程中直接从数学表达式去学习,总是感觉有诸多的疑问,以至于接受此算法所用的时间稍微长了一些,下面正式开始整理自己理解AdaBoost的过程
AdaBoost算法是boosting算法中的一种,它的作用就是将一系列弱分类器线性组合在一起形成一个强分类器,可以这样理解AdaBoost就像一个领导,那些弱分类器算法(如:单层决策树等)就像员工,每个员工均有自己的特征,而AdaBoost做为老板的作用就是将这些员工通过某种方式组合在一起将事情做得更好,放在机器学习中就是将分类任务或者说回归任务能做得更好,也就是所说的提升方法。AdaBoost是通过什么样的方式来完成这个任务的呢?
在《李航-统计学习方法中》关于提升方法提出两个问题,而AdaBoost的原理就是如何解决这两个问题
问题1:每一轮如何改变训练数据的权值或概率分布?
AdaBoost:提高那些被前一轮分类器错误分类样本的权值,而降低那些被分类正确样本的权值。这样一来,那些没有得到正确分类的的数据,由于其权值加大而受到后一轮若分类器更大的关注。
问题2:如何将若分类器组合成一个强分类器?
AdaBoost:采用加权多数表决的方法,即加大分类误差小的弱分类器的权值,使其在表决中起较大的作用,减小分类吴超率大的弱分类器的权值,使其在表决中起较小的作用
理解AdaBoost即就是理解上述两个问题的数学表达:
AdaBoost最终的数学表达式为:

其中m表示:第m个分类器,M表示总共有M个分类器
x:表示样本集合
上式(1)的形成过程如下:
输入:训练数据集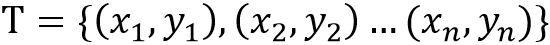 ,其中
,其中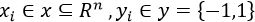 ;弱学习算法;
;弱学习算法;
输出:最终分类器G(x)

2.2 分步骤理解上述AdaBoost算法
m = 1 时,即利用第一个分类器开始学习训练数据集时
*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-
第一步:对于第一个分类器,我们假设每个样本的权值是相同的。引用《李航-统计学习方法》中的案例来理解第一步:
例:对于如下数据集,假设弱分类器由x<ν或想x>v产生,其中阀值ν使得该分类器在训练数据集上分类误差率最低,试用AdaBoost算法学习一个强分类器;
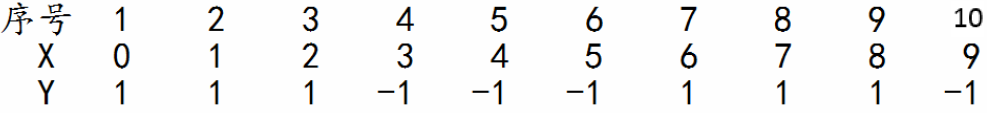
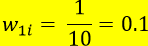
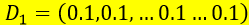
第二步:确定基本分类器G

此处样本量并不大,我们可以手动计算一下,例如阀值分别取1.5,2.5,3.5,...,9.5时的分类误差率,就能得到当v=2.5是分类误差率最小即:
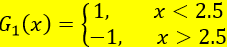
第三步:计算在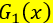 分类器上的训练误差率
分类器上的训练误差率

第四步:计算分类器的权值(注意这里是以e为底进行计算的)
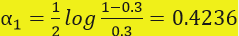
第六步:确定最终分类器
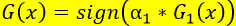
利用上述G(x)对训练数据集进行分类,仍有3个数据被分类错误
第七步:计算下一次循环的样本集的权重

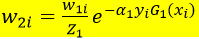
D2=(0.0715, 0.0715, 0.0715, 0.0715, 0.0715, 0.0715,0.1666, 0.1666, 0.1666, 0.0715)
m = 2 ,组合第二个弱分类器
*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-
重复上述第二步到第七步
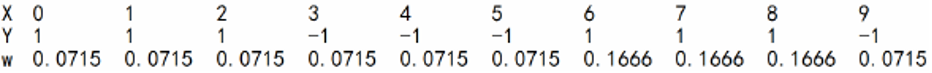
分类误差率最小的阀值为8.5
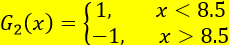
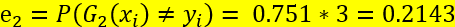
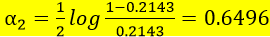

此时利用上述G(x)对训练数据集进行分类,仍有3个点被误分类
m = 3 ,组合第三个弱分类器
*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-
再次重复上述第二步到第七步

分类误差最小的阀值为5.5
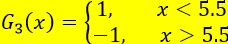
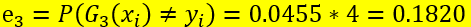

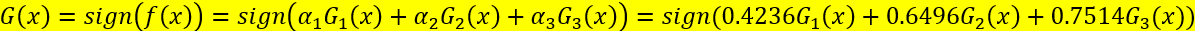
此时利用上述的G(x)在对样本集进行分类,上述训练数据集上有0个误分类点,即误分率为0,此时即可停止,上述G(x)即可作此数据的强分类器
1.3 总结
通过对上述案例的认识,我们可量化的指标所表现的规律再从定性的角度理解
(1)被前一个分类器分错得样本,下一个分类器再对其进行分类时一定不会被分错,为什么?
我们通过数值观察,被分错的样本,在下一次分类时样本权值被增大如(m=2时样本权值为0.1666的样本),而我们在流程图中第二步提到,在选择分类器时,要求选择分类误差率最低的分类器(为甚要这么选的原理见下文式(11)),显然如果将权值大的样本分类错时根本达不到第二步的要求。
(2)m=3时为什么误分率为0,从定性的角度如何理解?
m=3时的组合分类器的权值alpha逐渐增大,即我们给予分类误差率低的样本给予了高的权值,而从数值上去判断,最终f(x)>0亦或是f(x)<0是由三个分类器所共同决定的,假如说第一个分类器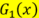 将某一样本原本是1类别,分成了-1类别,那么其对最终分类器来说,会提供一个负的贡献,而后边的分类器总会将这个负的贡献抵消掉,使得最终结果还是1类别。
将某一样本原本是1类别,分成了-1类别,那么其对最终分类器来说,会提供一个负的贡献,而后边的分类器总会将这个负的贡献抵消掉,使得最终结果还是1类别。
3.AdaBoost算法的理解
《李航-统计学习方法》中提到,AdaBoost算法是模型为加法模型,损失函数为指数函数,学习算法为前向分步算法时的二分类学习方法,此解释实际解释了上述我们的AdaBoost算法的原理的由来;
3.1 加法模型的一般表达式如下:


3.2 前向分步算法:
选定模型后,我们的目标就是通过训练数据集去训练模型(本质是训练模型中的参数),用什么来衡量模型训练的好坏呢?常常通过经验风险极小化即损失函数极小化,此处在给定训练数据集及损失函数L(y,f(x))的条件下,我们的目标极小化此损失函数,形式如下:
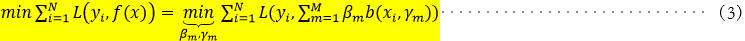
由于f(x)为加法模型,现在我们的任务是优化模型参数 ,使得损失函数
,使得损失函数 最小,我们可以采用优化加法模型中的每一项,让每一项的结果最小,这样问题将转化为如下形式:
最小,我们可以采用优化加法模型中的每一项,让每一项的结果最小,这样问题将转化为如下形式:

上述(3)到(4)转化过程即为前向分步算法的核心。
3.3 利用上述加法模型以及前向分步算法的原理推导AdaBoost模型
AdaBoost模型为:

损失函数为:

设已经优化了m-1轮,即已经得到了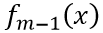 ,如式(7),在第m轮我们通过迭代可得如下式(8)
,如式(7),在第m轮我们通过迭代可得如下式(8)
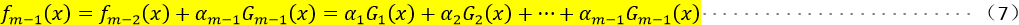

我们可通过使上述式(8)对对应的损失函数最小,损失函数如下式(9)

通过优化式(9)使得式(9)最小即可得到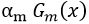

 即不依赖于alpha,也不依赖于G,故以G为自变量求解损失函数的极小值即等价于下述式(11):
即不依赖于alpha,也不依赖于G,故以G为自变量求解损失函数的极小值即等价于下述式(11):

式(11)解释了再上述流程图的第二步,我们每次找分类器的时候,要找误差率最小的分类器的原因,即要使得损失函数最小。
而对于alpha,式(9)关于alpha求导,并令倒数等于0,即可得到 ,过程如下:
,过程如下:
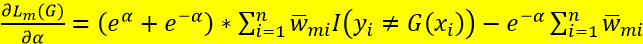 ,令其为0即得
,令其为0即得
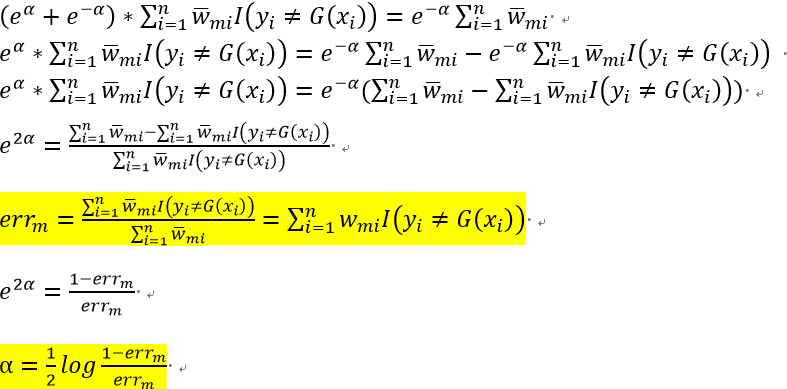
由上述(9)已知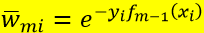 ,所以
,所以

此处与AdaBoost算法的不同之处在于,AdaBoost对w进行了归一化
2.实例
3.算法推导
4.注意点
6.集成算法boosting----AdaBoost算法的更多相关文章
- 集成学习值Adaboost算法原理和代码小结(转载)
在集成学习原理小结中,我们讲到了集成学习按照个体学习器之间是否存在依赖关系可以分为两类: 第一个是个体学习器之间存在强依赖关系: 另一类是个体学习器之间不存在强依赖关系. 前者的代表算法就是提升(bo ...
- 集成学习之Adaboost算法原理小结
在集成学习原理小结中,我们讲到了集成学习按照个体学习器之间是否存在依赖关系可以分为两类,第一个是个体学习器之间存在强依赖关系,另一类是个体学习器之间不存在强依赖关系.前者的代表算法就是是boostin ...
- 集成学习之Adaboost算法原理
在boosting系列算法中,Adaboost是最著名的算法之一.Adaboost既可以用作分类,也可以用作回归. 1. boosting算法基本原理 集成学习原理中,boosting系列算法的思想:
- Python实现机器学习算法:AdaBoost算法
Python程序 ''' 数据集:Mnist 训练集数量:60000(实际使用:10000) 测试集数量:10000(实际使用:1000) 层数:40 ------------------------ ...
- adaboost算法
三 Adaboost 算法 AdaBoost 是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器,即弱分类器,然后把这些弱分类器集合起来,构造一个更强的最终分类器.(很多博客里说的三个臭皮匠 ...
- 【机器学习笔记之四】Adaboost 算法
本文结构: 什么是集成学习? 为什么集成的效果就会好于单个学习器? 如何生成个体学习器? 什么是 Boosting? Adaboost 算法? 什么是集成学习 集成学习就是将多个弱的学习器结合起来组成 ...
- 04-02 AdaBoost算法
目录 AdaBoost算法 一.AdaBoost算法学习目标 二.AdaBoost算法详解 2.1 Boosting算法回顾 2.2 AdaBoost算法 2.3 AdaBoost算法目标函数优化 三 ...
- SIGAI机器学习第二十集 AdaBoost算法1
讲授Boosting算法的原理,AdaBoost算法的基本概念,训练算法,与随机森林的比较,训练误差分析,广义加法模型,指数损失函数,训练算法的推导,弱分类器的选择,样本权重削减,实际应用 AdaBo ...
- AdaBoost 算法-分析波士顿房价数据集
公号:码农充电站pro 主页:https://codeshellme.github.io 在机器学习算法中,有一种算法叫做集成算法,AdaBoost 算法是集成算法的一种.我们先来看下什么是集成算法. ...
- Adaboost 算法
一 Boosting 算法的起源 boost 算法系列的起源来自于PAC Learnability(PAC 可学习性).这套理论主要研究的是什么时候一个问题是可被学习的,当然也会探讨针对可学习的问题的 ...
随机推荐
- 蚂蚁分类信息商家发布文章、商品外链及远程图片自动添加nofollow属性
蚂蚁商户发布文章.商品是可以添加外链或者直接用外部图片,但是这对分类网站运营不利. 所以要对外链进行过滤,演示网站保洁,蚂蚁分类的源码. 下面就说下怎么处理自动给外链自动加上nofollow属性. 1 ...
- C语言函数调用时候内存中栈的动态变化详细分析(彩图)
版权声明:本文为博主原创文章,未经博主允许不得转载.欢迎联系我qq2488890051 https://blog.csdn.net/kangkanglhb88008/article/details/8 ...
- linux环境下tomcat启动成功,部分请求页面出现404
这种情况很多,本文记录我遇到比较奇葩的情况. 第一种情况: 第一次tomact启动成功,访问404,乱捣鼓不知怎么好了:第二次tomcat启动成功,可以访问部分链接,有些却报404,但是代码和数据都还 ...
- maven项目转换为gradle项目
进入到项目更目录,运行 gradle init --type pom 上面的命令会根据pom文件自动生成gradle项目所需的文件和配置,然后以gradle项目重新导入即可.
- luogu P3226 [HNOI2012]集合选数
luogu 因为限制关系只和2和3有关,如果把数中2的因子和3的因子都除掉,那剩下的数不同的数是不会相互影响,所以每次考虑剩下的数一样的一类数,答案为每类数答案的乘积 如果选了一个数,那么2的因子多1 ...
- 16、Nginx Rewrite重写
1.Rewrite基本概述 1.1.什么是rewrite Rewrite主要实现url地址重写, 以及地址重定向,就是将用户请求web服务器的地址重新定向到其他URL的过程. 1.2.Rewrite使 ...
- 为你的docker容器增加一个健康检查机制
1.健康检查 在分布式系统中,经常需要利用健康检查机制来检查服务的可用性,防止其他服务调用时出现异常.自 1.12 版本之后,Docker 引入了原生的健康检查实现. 如何给Docke配置原生健康检查 ...
- init container
init container与应用容器在本质上是一样的, 但它们是仅运行一次就结束的任务, 并且必须在成功执行完成后, 系统才能继续执行下一个容器, 可以用在例如应用容器启动前做一些初始化工作,当in ...
- 多态(Polymorphism)的实现机制
1. 我理解的广义的 override 是指抛开各种访问权限,子类重定义(redefine)父类的函数(即函数签名相同). 2. C++中的三个所谓的原则:never redefine base cl ...
- maven私仓搭建——nexus3
maven私仓搭建——nexus3本文主要介绍maven私仓在windows下的搭建.本文主要参考:http://www.cnblogs.com/bingyeh/p/5913486.html好,下面上 ...