Apache Flink 介绍
本文简单介绍一下Flink,部分内容来源于网络,想深入了解Flink的读者可以参照官方文档深入学习Apache Flink。
流计算
在介绍Flink之前首先说一下流计算的概念,流计算是针对流式数据的实时计算。
- 流式数据是指将数据看作数据流的形式来处理,数据流是在时间分布和数量上无限的一系列动态数据集合体,数据记录是数据流的最小组成单元。
- 流数据具有数据实时持续不断到达、到达次序独立、数据来源众多格式复杂、数据规模大且不十分关注存储、注重数据的整体价值而不关注个别数据等特点。
Apache Flink是什么
Apache Flink是一个分布式流批一体化的开源平台。Flink的核心是一个提供数据分发、通信以及自动容错的流计算引擎。Flink在流计算之上构建批处理,并且原生的支持迭代计算、内存管理以及程序优化。官方称之为Stateful Computations over Data Streams,即数据流上有状态计算。官方对Flink的详细介绍What is Apache Flink。
Flink的特点
现有的开源计算方案会把流处理和批处理作为两种不同的应用类型(如Apache Storm只支持流处理,Apache Spark只支持批(Micro Batching)处理),流处理一般需要支持低延迟、Exactly-once保证,而批处理需要支持高吞吐、高效率。Flink同时支持流处理和批处理,作为流处理时输入数据流是无界的,批处理被作为一种特殊的流处理,只是它的输入数据流被定义为有界的。
Flink重要基石
Apache Flink的四个重要基石:Checkpoint、State、Time、Window
- Checkpoint:基于Chandy-Lamport算法实现了分布式一致性快照,提供了一致性的语义
- State:丰富的State API,包括ValueState、ListState、MapState、BoardcastState
- Time:实现了Watermark机制,能够支持基于事件的时间的处理,能够容忍数据的延时、迟到和乱序
- Window:开箱即用的窗口,滚动窗口、滑动窗口、会话窗口和灵活的自定义窗口
Flink的优势
- 支持高吞吐、低延迟、高性能的流数据处理
- 支持高度灵活的窗口(Window)操作
- 支持有状态计算的Exactly-once语义
- 提供DataStream API和DataSet API
适用场景
Flink支持下面这三种最常见类型的应用示例,官网有详细的介绍Use Cases。
- 事件驱动的应用程序
- 数据分析应用
- 数据管道应用
基础架构
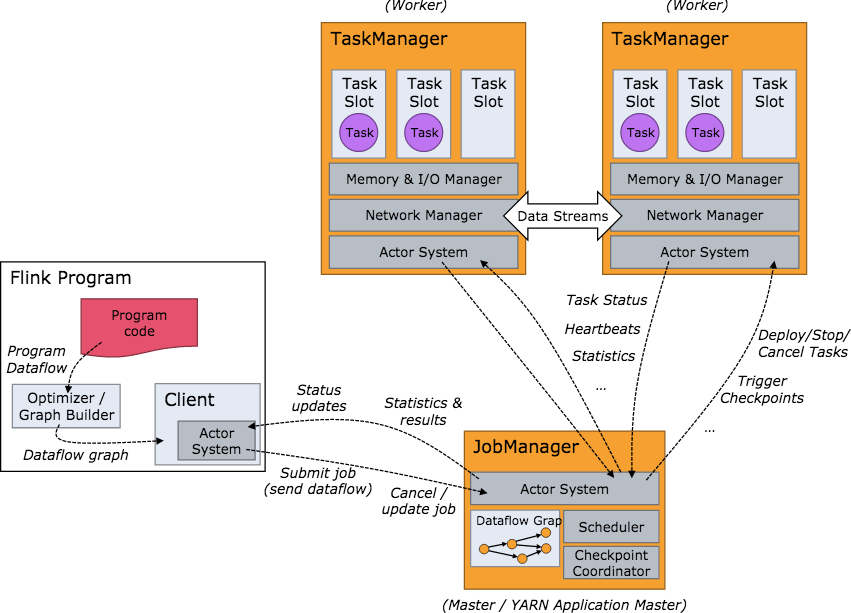
Flink集群启动后,首先会启动一个JobManger和一个或多个TaskManager。由Client提交任务给JobManager,JobManager再调度任务到各个TaskManager去执行,然后TaskManager将心跳和统计信息汇报给JobManager,TaskManager之间以流的形式进行数据的传输。JobManager、TaskManager和Client均为独立的JVM进程。
- JobManager是系统的协调者,负责接收Job,调度组成Job的多个Task的执行,收集Job的状态信息,管理Flink集群中的TaskManager。
- TaskManager是实际负责执行计算的Worker,并负责管理其所在节点的资源信息,在启动的时候将资源的状态向JobManager汇报。
- Client负责提交Job,可以运行在任何与JobManager环境连通的机器上,提交Job后,Client可以结束进程,也可以不结束并等待结果返回。
基本编程模型
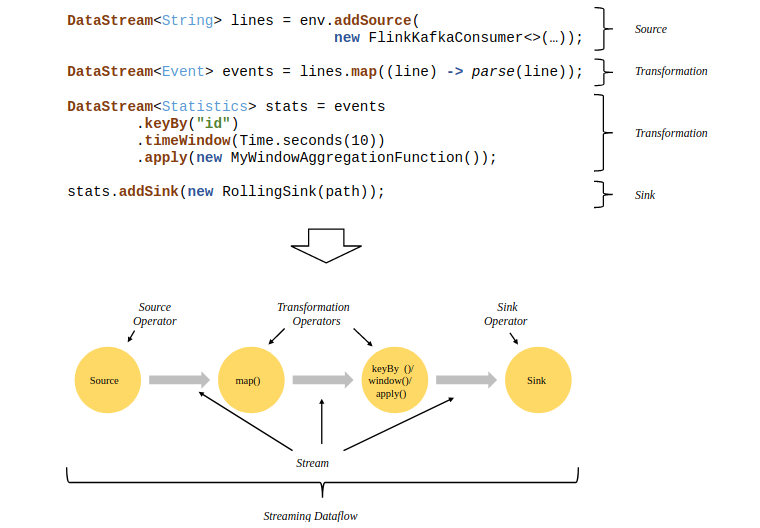
Flink程序的基础构建模块是流(streams)与转换(transformations),每一个数据流都起始于一个或多个source,并终止于一个或多个sink,下面是一个由Flink程序映射为Streaming Dataflow的示意图:
容错机制
Flink的容错机制的核心部分是分布式数据流和operator state的一致性快照,系统发生故障的时候这些快照可以充当一致性检查点来退回,恢复作业的状态和计算位置等。官网有详细介绍Data Streaming Fault Tolerance。
- Checkpointing
- Recovery
- Operator Snapshot Implementation
Apache Flink 介绍的更多相关文章
- Flink 从0到1学习 —— Flink 中如何管理配置?
前言 如果你了解 Apache Flink 的话,那么你应该熟悉该如何像 Flink 发送数据或者如何从 Flink 获取数据.但是在某些情况下,我们需要将配置数据发送到 Flink 集群并从中接收一 ...
- Flink 从0到1学习—— 分享四本 Flink 国外的书和二十多篇 Paper 论文
前言 之前也分享了不少自己的文章,但是对于 Flink 来说,还是有不少新入门的朋友,这里给大家分享点 Flink 相关的资料(国外数据 pdf 和流处理相关的 Paper),期望可以帮你更好的理解 ...
- Flink 从 0 到 1 学习 —— Flink 配置文件详解
前面文章我们已经知道 Flink 是什么东西了,安装好 Flink 后,我们再来看下安装路径下的配置文件吧. 安装目录下主要有 flink-conf.yaml 配置.日志的配置文件.zk 配置.Fli ...
- Flink 从 0 到 1 学习 —— 如何自定义 Data Sink ?
前言 前篇文章 <从0到1学习Flink>-- Data Sink 介绍 介绍了 Flink Data Sink,也介绍了 Flink 自带的 Sink,那么如何自定义自己的 Sink 呢 ...
- Flink 从 0 到 1 学习 —— 如何自定义 Data Source ?
前言 在 <从0到1学习Flink>-- Data Source 介绍 文章中,我给大家介绍了 Flink Data Source 以及简短的介绍了一下自定义 Data Source,这篇 ...
- Flink 从 0 到 1 学习 —— Flink Data transformation(转换)
toc: true title: Flink 从 0 到 1 学习 -- Flink Data transformation(转换) date: 2018-11-04 tags: Flink 大数据 ...
- Apache Flink 1.5.0 Release Announcement
Apache Flink: Apache Flink 1.5.0 Release Announcement https://flink.apache.org/news/2018/05/25/relea ...
- 当Atlas遇见Flink——Apache Atlas 2.2.0发布!
距离上次atlas发布新版本已经有一年的时间了,但是这一年元数据管理平台的发展一直没有停止.Datahub,Amundsen等等,都在不断的更新着自己的版本.但是似乎Atlas在元数据管理,数据血缘领 ...
- 企业实践 | 如何更好地使用 Apache Flink 解决数据计算问题?
业务数据的指数级扩张,数据处理的速度可不能跟不上业务发展的步伐.基于 Flink 的数据平台构建.运用 Flink 解决业务场景中的具体问题等随着 Flink 被更广泛的应用于广告.金融风控.实时 B ...
- Stream processing with Apache Flink and Minio
转自:https://blog.minio.io/stream-processing-with-apache-flink-and-minio-10da85590787 Modern technolog ...
随机推荐
- C#学习(一):委托和事件
预备知识 在学习委托和事件之前,我们需要知道的是,很多程序都有一个共同的需求,即当一个特定的程序事件发生时,程序的其他部分可以得到该事件已经发生的通知. 而发布者/订阅者模式可以满足这种需求.简单来说 ...
- sh 脚本执行sql文件传参数
一.前言 今天做数据删除,用的命令行输入参数,并且调用执行的sql文件,我采用了sed命令,进行替换. sh脚本如下 #! /bin/sh echo "Please enter the ba ...
- Cookie与 Session使用详解
Cookie概念 在浏览某些 网站 时,这些网站会把 一些数据存在 客户端 , 用于使用网站 等跟踪用户,实现用户自定义 功能. 是否设置过期时间: 如果不设置 过期时间,则表示这个 Cookie生命 ...
- 并发库应用之十二 & 常用集合问题汇总
1. List遍历时修改报错 别的先什么都不说,直接上代码看看就知道了: public class ListTest { public static void main(String[] args) ...
- yum安装指定版本的软件包的方法
yum默认都是安装最新版的软件,这样可能会出一些问题,或者我们希望yum安装指定(特定)版本(旧版本)软件包.所以,就顺带分享yum安装指定(特定)版本(旧版本)软件包的方法. 过程如下:假设这里是我 ...
- Spring-cloud (九) Hystrix请求合并的使用
前言: 承接上一篇文章,两文本来可以一起写的,但是发现RestTemplate使用普通的调用返回包装类型会出现一些问题,也正是这个问题,两文没有合成一文,本文篇幅不会太长,会说一下使用和适应的场景. ...
- level.go
package blog4go import ( "fmt" "strings" ) // LevelType type defined for logging ...
- 在MFC中怎么获得Excel文档中已经使用了的行数和列数
_Worksheet ws;Range range; range = ws.GetUsedRange();//获得Worksheet已使用的范围range = range.GetRows(); / ...
- 【状态表示】Bzoj1096 [SCOI2008] 着色方案
Description 有n个木块排成一行,从左到右依次编号为1~n.你有k种颜色的油漆,其中第i种颜色的油漆足够涂ci个木块.所有油漆刚好足够涂满所有木块,即c1+c2+...+ck=n.相邻两个木 ...
- CTF中常见的加解密(经典)
今天一早起来,就要去做早操,心里苦呀! 但是不影响我为未来的学弟学妹整理资料的心情呀!希望我的一些拙见能够帮助到学弟学妹! 永远爱你们的 ---- 新宝宝 ASCII编码 ASCII 码使用指定的7 ...