MySQL复制进阶
Ⅰ、背景
搭建MySQL复制环境非常简单
你的系统是否也是像我之前那么搭建的呢?
那么,你的复制系统是否出现过以下的情况呢?
- 复制报错,例如:1062,1032
- 主从数据不一致
Ⅱ、真正高可靠复制环境相关配置(crash-safe replication)
master:
binlog_do_db # if possible
binlog_ignore_db # if possbile
max_binlog_size = 2048M
# 默认1g,其实也够用,MySQL每次写满1g后做的切换代价太大,但5.7已经修复了,不是太大问题
binlog_format = ROW
transaction_isolation = read-committed
expire_logs_days = 7 #capacity plan
server_id = # Unique
binlog_cache_size = # take care
# 默认32k,如果一个大事务,产生日志大于32k,那内存写不下就要写磁盘了
# show global status like 'binlog_cache_disk_use';
# 表示使用了基于磁盘的binlog的cache有多少
# 如果这个值比较高,那就可以考虑调大binlog_cache_size
# 通常32k够用,但是批量删除或者更新就可能超过32k,这时候性能就会下降了
sync_binlog = 1 # must set to 1,default is 0,5.7.7 default is 1
# 二进制日志一定要实时落盘,这个时时落盘,上一个参数就没用了
innodb_flush_log_at_trx_commit = 1 # redo也必须实时落盘
innodb_support_xa = 1
# 上面两个参数是通过内部分布式事务实现的,所以要开
relay_log_recovery = 1 # I/O thread crash safe 默认关的
relay_log_info_repository = TABLE # SQL thread crash safe 默认是file
# 高可用切换时,主可能变成从,所以上面两个参数主也要配上
master_info_repository = TABLE
slave:
log_slave_updates
# 级联复制用,对于同步过来的操作回放后,再产生日志,这样就不用做增量备份了
replicate_do_db
replicate_ignore_db
replicate_do_table
replicate_ignore_table
server_id = # Unique
relay_log_recovery = 1 # I/O thread crash safe 默认关的
relay_log_info_repository = TABLE # SQL thread crash safe 默认是file
master_info_repository = TABLE
read_only = 1
Ⅲ、sql/io高可靠
3.1 sql线程高可靠
背景:
- 如果将relay_log_info_repository设置为FILE,MySQL会把回放信息记录在一个relay-info.log 的文件中,其中包含SQL线程回放到的Relay_log_name和Relay_log_pos,以及对应的Master的Master_log_name和Master_log_pos
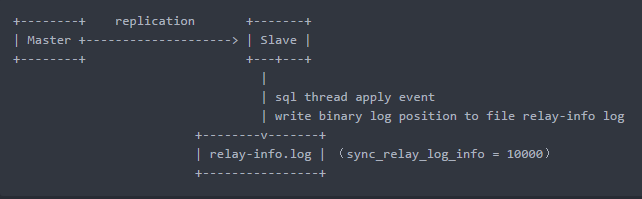
- SQL线程回放event
- 将回放到的binlog的文件名和位置写到relay-info.log文件
- 参数sync_relay_log_info = 10000(fsync)代表每回放10000个event,写一次 relay-info.log,默认1w
综上:SQL线程的数据回放是写数据库操作,relay-info是写文件操作,这两个操作很难保证一致性,看下面这种情况
step1:
主上顺序插入1,2,3
step2:
从同步主,插入1,2,3,成功且已刷盘
刚好1这条记录刚好是第 N w个event,此时relay-info.log刷盘,这样就只刷到1的位置,2,3没被刷进去
step3:
无独有偶,slave挂了
这时候slave起来之后,继续回放的时就会从1后面的位置开始回放,这样问题就出来了,报1062,2,3这两条记录重复了
解决:
有人说把sync_relay_log_info设置为1就好了,其实不然
- 如果该参数设置为 1,则表示每回放一个event,就写一次relay-info.log ,那写入代价很大,且性能很差
- 设置为1后,即使性能上可以接受,还是会丢最有一次的操作,恢复起来后还是有1062的错误
MySQL 5.6之后,我们将relay_log_info_repository设置为TABLE,relay-info将写入到mysql.slave_relay_log_info这张表中
原理:
将event的回放和relay-info的更新放在同一个事物里面,变成原子操作,从而保证一致性(要么都写入,要么都不写)每一次事物提交,都会写入mysql.slave_relay_log_info中,sync_relay_log_info=N将被忽略
BEGIN;
apply log event;
apply log event;
UPDATE mysql.slave_relay_log_info
SET Master_log_pos = Exec_Master_Log_Pos,
Master_log_name = Relay_Master_Log_File,
Relay_log_name = Relay_Log_File,
Relay_log_pos = Relay_Log_Pos;
COMMIT;
3.2 io线程高可靠
背景:
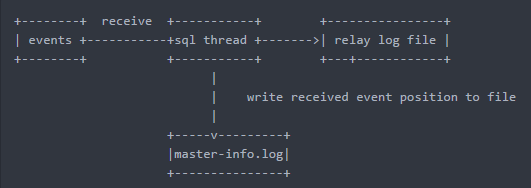
- io线程负责接收event到relay log file,每接收到一个event会在master-info.log记录一下IO线程接收到的位置(Master_log_name和Master_log_pos)
- sync_master_info=10000表示每接收10000个event,写一次master-info
这里存在同样的问题,master-info.log和relay log无法保证一致性,还是之前的例子:
step1:
主上顺序插入1,2,3
step2:
event已经都传到relay log中了
但2,3两个记录的master-info还未刷到master-info.log
step3:
io线程挂了
重新拉起来,io线程又会去拉一遍2和3送到relay log中,当sql线程执行到这一块也是报错冲突了
看到的现象还是 IO线程正常,SQL线程报错
- 可通过设置参数master_info_repository来选择master-info.log信息写入到FILE或TABLE
解决:
- 设置master_info_repository = TABLE???
没用的,event是写到relay log文件里的,不是数据库操作,所以写表里也没用,做不到原子性 - 正确做法是配置relay_log_recovery = 1,表示当slave重启时,将所有relay log删除,通过sql线程重放的位置点去重新拉日志
- master_info_repository设置为TABLE虽然对crash-safe没有帮助,但也请设置为TABLE,特别是5.7,并行复制会大幅提升master.info更新的消耗,所以设置为TABLE降低消耗
tips:
如果 Slave落后Master的时间很多,超过了Master上binlog的保存时间,那Master上对应的binlog就会被删除,Slave的I/O Thread就拉不到数据了,注意监控主从落后的时间
3.3 小结
真正的MySQL复制的高可靠是从 5.6 版本开始的,通过设置以下三个参数确保复制的高可靠(换言,之前的版本复制不可靠很正常)
relay_log_recover = 1
relay_log_info_repository = TABLE
master_info_repository = TABLE
非常建议这3个参数主从配置完全一致,主从是平等的,尽量对称
Ⅳ、并行复制(Multi-Threaded Slave)
4.1 背景
主从复制延迟是老生常谈的问题了,这里只谈sql线程回放慢的问题,其他因素不考虑,sql线程回放慢最主要的原因就是MySQL 5.5之前都是单线程回放
- 5.6开始支持多线程复制
slave_parallel_workers 0表示只有1个线程,可以动态设置,但是要重启一下复制,线上设为8或者16
注意:5.6版本只支持基于database的并行回放,所以不能选择并行模式,有多少个库,就可以开多少个线程,每个线程回放指定的库,缺点就是只有一个库的时候就并行不了,所以说这时候的并行复制用的并不多
- 5.7支持并行复制模式设置
slave_parallel_type=logical_clock
配置很简单,性能很棒棒,主上面怎么并行,从上面就怎么回放,基于逻辑时钟的概念
5.7才有,5.7.19之前有bug,会导致主从不一致,慎用
- Slave上commit的顺序保持一致,否则可能会有GAP锁产生
slave_preserve_commit_order=1
- 并行复制时,slave上coordinator线程负责任务指派,work thread负责回放如下
(root@172.16.0.10) [test]> show processlist;
+----+-------------+-----------+------+---------+-------+--------------------------------------------------------+------------------+
| Id | User | Host | db | Command | Time | State | Info |
+----+-------------+-----------+------+---------+-------+--------------------------------------------------------+------------------+
| 1 | system user | | NULL | Connect | 26277 | Waiting for master to send event | NULL |
| 2 | system user | | NULL | Connect | 26217 | Slave has read all relay log; waiting for more updates | NULL |
| 4 | system user | | NULL | Connect | 26277 | Waiting for an event from Coordinator | NULL |
| 5 | system user | | NULL | Connect | 26277 | Waiting for an event from Coordinator | NULL |
| 6 | system user | | NULL | Connect | 26277 | Waiting for an event from Coordinator | NULL |
| 7 | system user | | NULL | Connect | 26277 | Waiting for an event from Coordinator | NULL |
| 10 | root | localhost | NULL | Query | 0 | starting | show processlist |
+----+-------------+-----------+------+---------+-------+--------------------------------------------------------+------------------+
7 rows in set (0.00 sec)
tips:
这里的并行复制指的是SQL Thread,而非IO Thread
Waiting for master to send event 这个State在show processlist中只有一个,即只有一个IO Thread
4.2 理解logical_clock
这是一种基于组提交的并行复制
如果一批事务在一组里提交,这些事务之间是没有锁冲突的(有锁冲突就要等待了,不可能在一组里提交)
此时,binlog就会记录组提交的信息,从回放的时候就可以知道哪些事务是一组里面的,一组里面的就丢到不同线程去回放,不是一组里的就等待,以此来提升并行度
5.7相关测试:
单线程,从机回放速度只能达到5k的qps
设置为logical_clock,从的qps能超过2.5w
tips:
- 如何看哪些事务在一组?
[root@VM_0_5_centos ~]# mysqlbinlog xxx |grep last_comitted
last_comitted相等的事务是在同一组里提交的
- last_commited记录了上一组提交的事务号,而每个事务的sequence_number是一直递增的
- 每组的last_committed值,都是上一个组中事务的sequence_number最大值,也是本组中事务sequence_number最小值减1
- last_committed和sequence_number作用域不得跨文件
Ⅴ、8.0并行复制初探
MySQL 8.0出了一个更屌的复制并行回放,即使主上面是单线程执行了几个事务(更改了很多行,但是这些行不相关),从也可以并行回放这些事务
如何实现:
- 这种情况没有组提交,一组里面只有一个事务
- MySQL的binlog记录的行,每行都保存了这个库这张表以及它对应的主键值
- 如果两个事务之间修改的每行操作主键没有重复,没有交叉,就可以并行回放
- 基于writeset,所谓的writeset其实就是我们的row格式,写的结果集不就是row嘛
tips:
这种并行复制的前提是,binlog_format必须是row模式
没有主键的情况暂时没搞明白怎么做的,需要研究下官方文档
5.7.22已经引入了基于writeset的并行复制
小结
主从延迟问题困扰了MySQL差不多十年
5.7为什么这么重要?,最重要的就是并行复制,增强型的多线程回放,这可以说是一个里程碑
如果没有这个机制,做高可用切换,读写分离,效果都不好
MySQL复制进阶的更多相关文章
- mysql 开发进阶篇系列 47 物理备份与恢复(xtrabackup 的完全备份恢复,恢复后重启失败总结)
一. 完全备份恢复说明 xtrabackup二进制文件有一个xtrabackup --copy-back选项,它将备份复制到服务器的datadir目录下.下面是通过 --target-dir 指定完全 ...
- mysql 开发进阶篇系列 46 物理备份与恢复( xtrabackup的 选项说明,增加备份用户,完全备份案例)
一. xtrabackup 选项说明 在操作xtrabackup备份与恢复之前,先看下该工具的选项,下面记录了xtrabackup二进制文件的部分命令行选项,后期把常用的选项在补上.点击查看xtrab ...
- mysql 开发进阶篇系列 42 逻辑备份与恢复(mysqldump 的完全恢复)
一.概述 在作何数据库里,备份与恢复都是非常重要的.好的备份方法和备份策略将会使得数据库中的数据更加高效和安全.对于DBA来说,进行备份或恢复操作时要考虑的因素大概有如下: (1) 确定要备份的表的存 ...
- MySQL 【进阶查询】
数据类型介绍 整型 tinyint, # 占1字节,有符号:-128~127,无符号位:0~255 smallint, # 占2字节,有符号:-32768~32767,无符号位:0~65535 med ...
- 浅析MySQL复制
MySQL的复制是基于binlog来实现的. 流程如下 涉及到三个线程,主库的DUMP线程,从库的IO线程和SQL线程. 1. 主库将所有操作都记录到binlog中.当复制开启时,主库的DUMP线程根 ...
- MySQL复制环境(主从/主主)部署总结性梳理
Mysql复制概念说明Mysql内建的复制功能是构建大型,高性能应用程序的基础.将Mysql的数据分布到多个系统上去,这种分布的机制,是通过将Mysql的某一台主机的数据复制到其它主机(slaves) ...
- MYSQL复制
今天我们聊聊复制,复制对于mysql的重要性不言而喻,mysql集群的负载均衡,读写分离和高可用都是基于复制实现.下文主要从4个方面展开,mysql的异步复制,半同步复制和并行复制,最后会简单聊下第三 ...
- mysql复制一列到另一列
mysql复制一列到另一列 UPDATE 表名 SET B列名=A列名 需求:把一个表某个字段内容复制到另一张表的某个字段. 实现sql语句1: 复制代码代码如下: UPDATE file_man ...
- MySQL 复制介绍及搭建
MySQL复制介绍 MySQL复制就是一台MySQL服务器(slave)从另一台MySQL服务器(master)进行日志的复制然后再解析日志并应用到自身,类似Oracle中的Data Guard. M ...
随机推荐
- Java 条形码生成(一维条形码)
utl:http://mianhuaman.iteye.com/blog/1013945 在这里给大家介绍一个java 生成条形码 jbarcode.jar 生成条形码 支持EAN13, EAN8, ...
- 安卓笔记--intent传值不更新问题
今天在学习安卓的过程中,遇到一个问题,就是用intent进行多次传值的话, 他永远是第一次的值 后来发现,intent接收数据被写到了onCreat();方法中,这时候finish();到上一个Act ...
- C语言之linux内核实现位数高低位互换
linux内核实在是博大精深,有很多优秀的算法,我之前在工作中就遇到过位数高低位交换的问题,那时候对于C语言还不是很熟练,想了很久才写出来.最近在看内核的时候看到有内核的工程师实现了这样的算法,和我之 ...
- How to configure ODBC DSN to access local DB2 for Windows
How to configure ODBC DSN to access local DB2 for Windows MA Genfeng (GuangdongUnitoll Services inco ...
- AI之微信跳一跳
需要环境:1,Python3.6 2,android手机 3,ADB驱动,下载地址https://adb.clockworkmod.com/ 步骤: 配置Python3,ADB安装目录到环境变量pat ...
- path sum II(深度优先的递归实现掌握)
Given a binary tree and a sum, find all root-to-leaf paths where each path's sum equals the given su ...
- 02_Linux学习_命令
帮助命令: xxx --help man xxx 列出当前目录下的目录和文件: ls ls -l ls --help ...
- java——抽象
抽象类:特点:1,方法只有声明,没有实现时,该方法就是抽象方法,需要被abstract关键字修饰.抽象方法必须定义在抽象类中,该类也必须被abstract修饰2,抽象类不可以被实例化.为什么?因为调用 ...
- 工作中EF遇到的问题
EF的条件中,无法用转格式,时间差作为条件,这时在EF6中,可以用 DbFunctions 这个类,例如: db.NewsComments.Any( (entity.PostDate - p.Pos ...
- Android字符串资源及其格式化
http://blog.csdn.NET/wsywl/article/details/6555959 在Android项目布局中,资源以XML文件的形式存储在res/目录下.为了更好的实现国际化及本地 ...