103 - kube-scheduler源码分析 - 调度算法-寻找predicates和priorities

scheduler的主要逻辑是predicate和priority,前者回答哪些节点可以运行pod的问题,后者回答哪个节点更合适运行pod的问题。今天我们的任务是:从主函数出发,寻找predicates和priorities的入口!
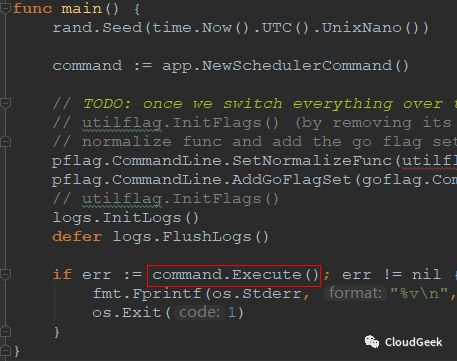
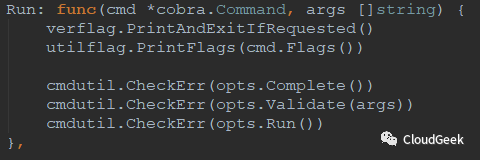
前面我们提到过Execute()其实是运行了这个Run方法,在cmd/kube-scheduler/app/server.go的337行。
顺着opts.Run()往里跟:
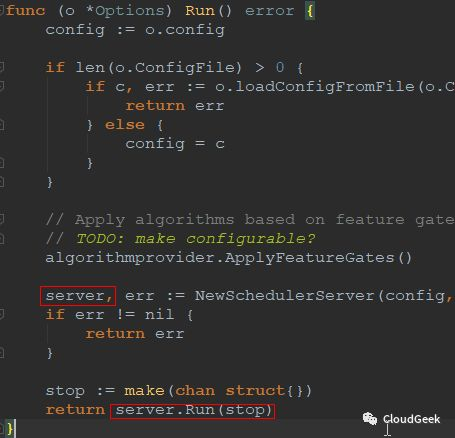
可以很清楚看到opts.Run()的逻辑,初始化一个server,然后执行server.Run()方法。这里的server类型是*SchedulerServer,这个类型的官方解释是:
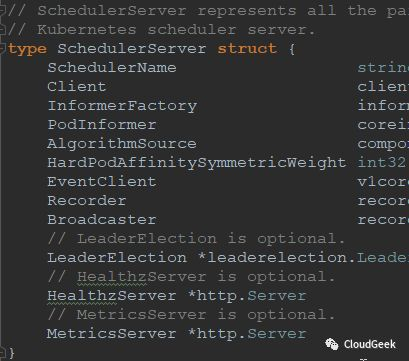
SchedulerServer represents all the parameters required to start the kubernetes scheduler server. 也就是说运行scheduler server所需的所有参数集合:
我们顺着主干往下走,看一下server.Run()方法的定义:
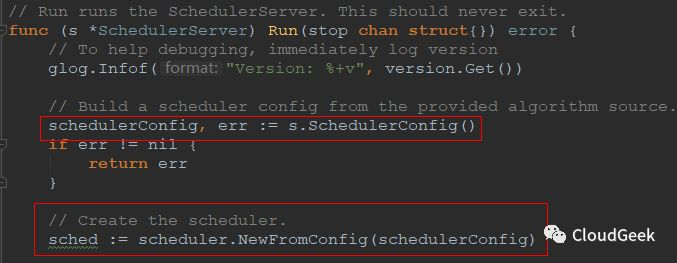
如上图,我们需要关注一下函数开头的注释,这个Run是要运行SchedulerServer,永远不退出!也就是说到这里就启动了一个server,开始无怨无悔永不停息地处理pod的scheduler流程!接着通过一个方法SchedulerConfig()获取到一个对象叫做schedulerConfig,我们也看一下这个对象的定义:Config is an implementation of the Scheduler's configured input data.
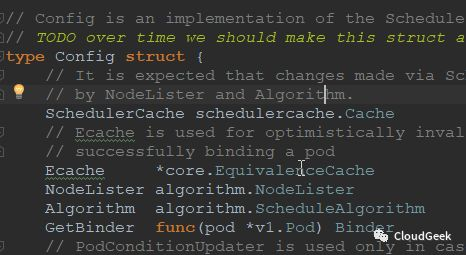
最后一个sched的创建代表着scheduler的daemon程序准备差不多了!sched的类型如下:

从注释中我们可以得到很多信息,Scheduler监视者未调度的pods,尝试寻找合适的node,把pod和node的绑定关系告诉api server!Run函数继续往后看可以找到(server.go的602行):
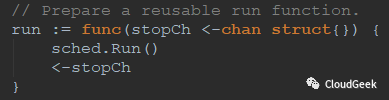
可以看到准备好了一个sched.Run(),但是没有立刻执行,626行有一个run(stop),就不贴截图了,我们直接跟到sched.Run()这个方法看一下里面写了啥:
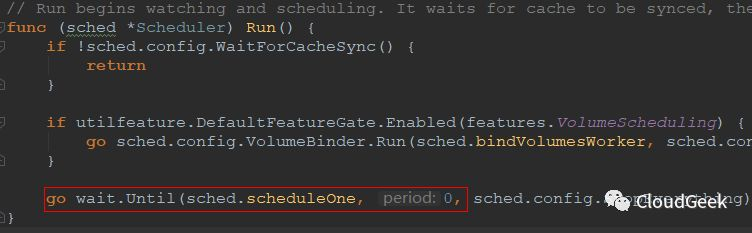
这个Run()方法开始watching and scheduling,最后面的红框需要注意几点,这是新开一个goroutine执行,然后立刻返回的。新开的goroutine是干嘛呢?每隔0秒就执行一次sched.scheduleOne方法!这里的0秒可能需要理解一下,我们看一下wait.Until()方法的定义:
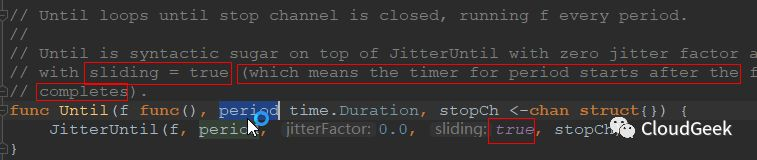
ok,其实是当f这个函数被调用完成后过0秒开始下一次调用,说白了就是前赴后继中间不休息!后面我们当然继续看scheduleOne()方法做了啥:
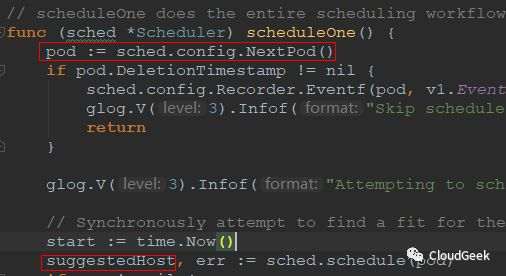
可以看到scheduleOne()方法能够处理一个pod完整的schedulering工作流。第一步是获取一个pod,这个pod的获取方法是这样定义的:

这里我们关注一下这个方法首先是阻塞的,也就是不返回一个结果就一直卡住。接着看一下suggestedHost是什么:
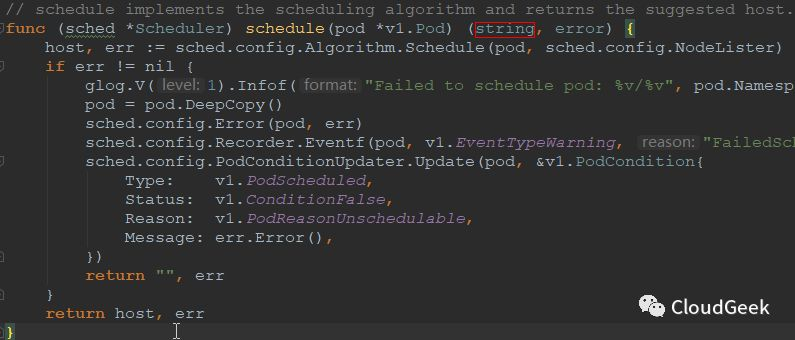
可以看到,这个类型是string,string不就意味着这就是最后的结果吗?不然怎么着也是一个[]string是吧???所以这里的suggestedHost也就是最后调度算法所给出建议跑pod的host!!!ok,我们的路没有偏离主线,继续看schedule方法的逻辑(上图中可以看到host是通过方法:sched.config.Algorithm.Schedule()获取的,我们直接看Schedule()方法):
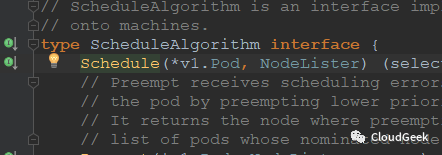
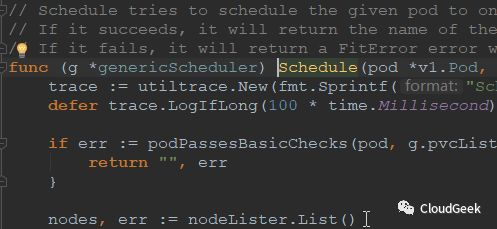
这个方法的参数是pod信息和node信息(获取node信息的接口),返回值是string类型,也就是根据pod信息和nodes信息看pod能够跑在哪个node上,然后返回这个node的名字!

上图从generic_scheduler.go的134行开始,这个msg信息很有意思,"Computing predicates",后面的findNodesThatFit()函数返回filteredNodes,也就是predicates过程的结果,返回的filteredNodes也就是可以运行pod的node集合!往下看150行处:
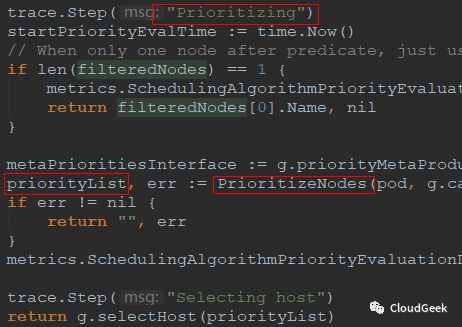
可以看到priorities过程在这里,PrioritizeNodes()函数返回一个priorityList,这个priorityList是schedulerapi.HostPriorityList类型,也就是[]HostPriority类型,HostPriority类型的定义如下:
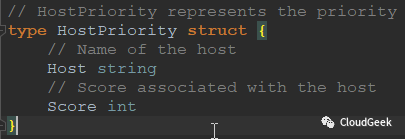
可以看到,这个类型其实存的数据就是一个节点的名字和分数信息,也就是说PrioritizeNodes()函数完成了所有可以跑pod的node的分数计算!结尾的selectHost()方法就很简单是,选择一个分高的host返回:
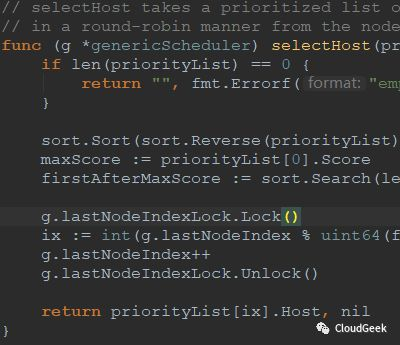
ok,总算跟完了,到这里我们就完成了整个调度过程的略读,下次开始我们可以看具体的predicates和priorities算法了!
103 - kube-scheduler源码分析 - 调度算法-寻找predicates和priorities的更多相关文章
- scheduler源码分析——preempt抢占
前言 之前探讨scheduler的调度流程时,提及过preempt抢占机制,它发生在预选调度失败的时候,当时由于篇幅限制就没有展开细说. 回顾一下抢占流程的主要逻辑在DefaultPreemption ...
- scheduler源码分析——调度流程
前言 当api-server处理完一个pod的创建请求后,此时可以通过kubectl把pod get出来,但是pod的状态是Pending.在这个Pod能运行在节点上之前,它还需要经过schedule ...
- Hadoop学习之--Capaycity Scheduler源码分析
Capacity Scheduler调度策略当一个新的job是否允许添加到队列中进行初始化,判断当前队列和用户是否已经达到了初始化数目的上限,下面就从代码层面详细介绍整个的判断逻辑.Capaycity ...
- scrapy-redis(调度器Scheduler源码分析)
settings里面的配置:'''当下面配置了这个(scrapy-redis)时候,下面的调度器已经配置在scrapy-redis里面了'''##########连接配置######## REDIS_ ...
- Storm源码分析--Nimbus-data
nimbus-datastorm-core/backtype/storm/nimbus.clj (defn nimbus-data [conf inimbus] (let [forced-schedu ...
- apiserver源码分析——启动流程
前言 apiserver是k8s控制面的一个组件,在众多组件中唯一一个对接etcd,对外暴露http服务的形式为k8s中各种资源提供增删改查等服务.它是RESTful风格,每个资源的URI都会形如 / ...
- apiserver源码分析——处理请求
前言 上一篇说道k8s-apiserver如何启动,本篇则介绍apiserver启动后,接收到客户端请求的处理流程.如下图所示 认证与授权一般系统都会使用到,认证是鉴别访问apiserver的请求方是 ...
- Quartz源码——scheduler.start()启动源码分析(二)
scheduler.start()是Quartz的启动方式!下面进行分析,方便自己查看! 我都是分析的jobStore 方式为jdbc的SimpleTrigger!RAM的方式类似分析方式! Quar ...
- JStorm与Storm源码分析(三)--Scheduler,调度器
Scheduler作为Storm的调度器,负责为Topology分配可用资源. Storm提供了IScheduler接口,用户可以通过实现该接口来自定义Scheduler. 其定义如下: public ...
随机推荐
- 【BZOJ 3626】 [LNOI2014]LCA【在线+主席树+树剖】
题目链接: TP 题解: 可能是我比较纱布,看不懂题解,只好自己想了…… 先附一个离线版本题解[Ivan] 我们考虑对于询问区间是可以差分的,然而这并没有什么卵用,然后考虑怎么统计答案. 首先LC ...
- python黑科技:还在为没有wifi而烦心吗?这篇文章解决你的困扰
python作为一门高级编程语言,它的定位是优雅.明确和简单.阅读Python编写的代码感觉像在阅读英语一样,这让使用者可以专注于解决问题而不是去搞明白语言本身.Python虽然是基于C语言编写,但是 ...
- Python一行代码实现快速排序
上期文章排序算法——(2)Python实现十大常用排序算法为大家介绍了十大常用排序算法的前五种(冒泡.选择.插入.希尔.归并),因为快速排序的重要性,所以今天将单独为大家介绍一下快速排序! 一.算法介 ...
- ASP.NET Core的实时库: SignalR -- 预备知识
大纲 本系列会分为2-3篇文章. 第一篇介绍SignalR的预备知识和原理 然后会介绍SignalR和如何在ASP.NET Core里使用SignalR. 本文的目录如下: 实时Web简述 Long ...
- 记ibatis使用动态列查询问题(remapresults)
今天在项目开发中,遇到了一个问题:使用ibatis 动态查询列时,每次返回的结果列都是第一次查询的结果列,然而控制台执行的SQL语句时包含该结果列的.比如: <select id="g ...
- Web前端-Ajax基础技术(下)
Web前端-Ajax基础技术(下) 你要明白ajax是什么,怎么使用? ajax,web程序是将信息放入公共的服务器,让所有网络用户可以通过浏览器进行访问. 浏览器发送请求,获取服务器的数据: 地址栏 ...
- office365的开发者训练营,免费,在微软广州举办
本活动在微软官网的地址: https://www.microsoft.com/china/events/detail_1707 先上活动内容: Office 365每月有超过1亿的商业活跃用户 ...
- iOS----------时间戳与NSDate
1:时间戳转NSDate NSString *timeStamp =@"1545965436"; NSDate *date = [NSDate dateWithTimeInterv ...
- Centos 配置开机启动脚本启动 docker 容器
Centos 配置开机启动脚本启动 docker 容器 Intro 我们的 Centos 服务器上部署了好多个 docker 容器,因故重启的时候就会导致还得手动去手动重启这些 docker 容器,为 ...
- 用samba来创建windows下的文件共享
前言 Samba是一个能让Linux系统应用Microsoft网络通讯协议的软件,而SMB是Server Message Block的缩写,即为服务器消息块 ,SMB主要是作为Microsoft的网络 ...