hadoop2.7.3+spark2.1.0+scala2.12.1环境搭建(2)安装hadoop
一、依赖安装
安装JDK
二、文件准备
hadoop-2.7.3.tar.gz
2.2 下载地址
http://hadoop.apache.org/releases.html
三、工具准备
3.1 Xshell
3.2 Xftp
四、部署图
master:192.168.136.128
slave:192.168.136.129
slave:192.168.136.130
五、Hadoop安装
以下操作,均使用root用户
5.1 主机名与IP地址映射关系配置
Master节点上,执行如下命令:
#vi /etc/hosts
在文件最后,输入如下内容:
- 192.168.136.128 LxfN1
- 192.168.136.129 LxfN2
- 192.168.136.130 LxfN3
保存,退出,然后通过scp命令,将配置好的文件拷贝其他两个Slave节点:
#scp /etc/hosts root@LxfN2:/etc
#scp /etc/hosts root@LxfN3:/etc
5.2 SSH免登陆配置
#ssh-keygen -t rsa
一直回车
然后分别拷贝到Master以及Slave节点:
- 对于LxfN1:
- 对于LxfN2:
- scp ./id_rsa.pub root@LxfN1:/root/.ssh/id_rsa_2.pub
- 对于LxfN3:
scp ./id_rsa.pub root@LxfN1:/root/.ssh/id_rsa_3.pub- 在LxfN1上合并所有文件成authorized_keys
分发合并后的文件authorized_keys到其他机器上
- scp ./authorized_keys root@LxfN1:/root/.ssh/
- scp ./authorized_keys root@LxfN1:/root/.ssh/
通过#ssh LxfN2 测试是否配置成功,如果不需要输入密码,则证明配置成功
5.3 通过Xftp将下载下来的Hadoop安装文件上传到Master及两个Slave的/usr目录下
5.4 通过Xshell连接到虚拟机,在Master及两个Slave上,执行如下命令,解压文件:
# tar zxvf hadoop-2.7.3.tar.gz
建立到解压目录的连接hadoop
5.5 在Master上,使用Vi编辑器,设置环境变量
# vi /etc/profile
在文件最后,添加如下内容:
# Hadoop Env
export HADOOP_HOME=/opt/moudles/hadoop
export PATH=PATH:PATH:HADOOP_HOME/bin:$HADOOP_HOME/sbin
5.6 退出vi编辑器,使环境变量设置立即生效
# source /etc/profile
通过scp命令,将/etc/profile拷贝到两个Slave节点:
#scp /etc/profile root@LxfN2:/etc
#scp /etc/profile root@LxfN3:/etc
分别在两个Salve节点上执行# source /etc/profile使其立即生效
5.7 查看Hadoop版本信息

- # hadoop version
- Hadoop 2.7.3
- Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r baa91f7c6bc9cb92be5982de4719c1c8af91ccff
- Compiled by root on 2016-08-18T01:41Z
- Compiled with protoc 2.5.0
- From source with checksum 2e4ce5f957ea4db193bce3734ff29ff4
- This command was run using /opt/modules/hadoop/share/hadoop/common/hadoop-common-2.7.3.jar
六、Hadoop配置
以下操作均在Master节点,配置完后,使用scp命令,将配置文件拷贝到两个Slave节点即可。
切换到/opt/modules/hadoop/etc/hadoop/目录下,修改如下文件:
6.1 hadoop-env.sh
在文件最后,增加如下配置:
- export JAVA_HOME=/opt/modules/jdk1.8
- export HADOOP_PREFIX=/opt/modules/hadoop
6.2 yarn-env.sh
在文件最后,增加如下配置:
- export JAVA_HOME=/opt/modules/jdk1.8
6.3 core-site.xml
创建tmp目录:#mkdir /usr/hadoop-2.7.3/tmp
- <configuration>
- <property>
- <name>fs.defaultFS</name>
- <value>hdfs://LxfN1:9000</value>
- </property>
- <property>
- <name>hadoop.tmp.dir</name>
- <value>/opt/data/hadoop/tmp</value>
- </property>
- </configuration>
6.4 hdfs-site.xml
- <configuration>
- <property>
- <name>dfs.replication</name>
- <value>3</value>
- </property>
- </configuration>
6.5 mapred-site.xml
- <configuration>
- <property>
- <name>mapreduce.framework.name</name>
- <value>yarn</value>
- </property>
- </configuration>
6.6 yarn-site.xml
- <configuration>
- <!-- Site specific YARN configuration properties -->
- <property>
- <name>yarn.nodemanager.aux-services</name>
- <value>mapreduce_shuffle</value>
- </property>
- <property>
- <name>yarn.resourcemanager.hostname</name>
- <value>LxfN1</value>
- </property>
- </configuration>
6.7 slaves
- LxfN1
- LxfN2
- LxfN3
6.8 拷贝配置文件到两个Slave节点
在Master节点,执行如下命令:
# scp -r /opt/modules/hadoop/etc/hadoop/ root@LxcN2:/opt/modules/hadoop/etc/
# scp -r /opt/modules/hadoop/ root@LxcN3:/opt/modules/hadoop/etc/
七、Hadoop使用
7.1 格式化NameNode
Master节点上,执行如下命令
#hdfs namenode -format
7.2 启动HDFS(NameNode、DataNode)
Master节点上,执行如下命令
#start-dfs.sh
使用jps命令,分别在Master以及两个Slave上查看Java进程
可以在Master上看到如下进程:
- 34225 SecondaryNameNode
- 33922 NameNode
- 34028 DataNode
- 49534 Jps
在两个Slave上,看到如下进程:
- 34028 DataNode
- 49534 Jps
7.3 启动 Yarn(ResourceManager 、NodeManager)
Master节点上,执行如下命令
#start-yarn.sh
使用jps命令,分别在Master以及两个Slave上查看Java进程
可以在Master上看到如下进程:
34225 SecondaryNameNode
33922 NameNode
34632 NodeManager
34523 ResourceManager
34028 DataNode
49534 Jps
在两个Slave上,看到如下进程:
34632 NodeManager
34028 DataNode
49534 Jps
7.4 通过浏览器查看HDFS信息
浏览器中,输入http://LxfN1:50070
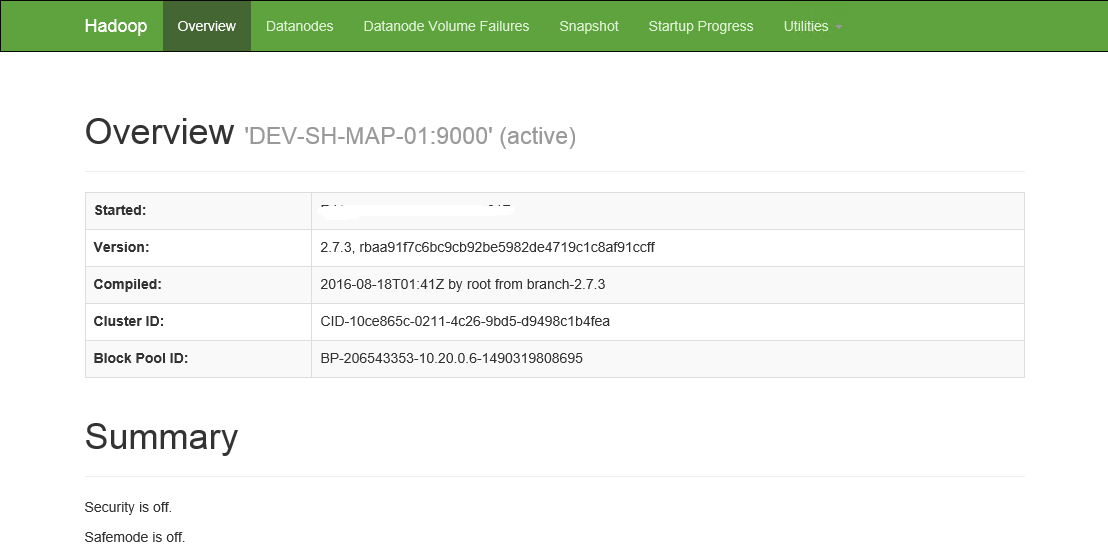
7.5 停止Yarn及HDFS
#stop-yarn.sh
#stop-dfs.sh
hadoop2.7.3+spark2.1.0+scala2.12.1环境搭建(2)安装hadoop的更多相关文章
- hadoop2.7.3+spark2.1.0+scala2.12.1环境搭建(4)SPARK 安装
hadoop2.7.3+spark2.1.0+scala2.12.1环境搭建(4)SPARK 安装 一.依赖文件安装 1.1 JDK 参见博文:http://www.cnblogs.com/liugh ...
- hadoop2.7.3+spark2.1.0+scala2.12.1环境搭建(3)http://www.cnblogs.com/liugh/p/6624491.html
一.文件准备 scala-2.12.1.tgz 下载地址: http://www.scala-lang.org/download/2.12.1.html 二.工具准备 2.1 Xshell 2.2 X ...
- hadoop2.7.3+spark2.1.0+scala2.12.1环境搭建(1)安装jdk
一.文件准备 下载jdk-8u131-linux-x64.tar.gz 二.工具准备 2.1 Xshell 2.2 Xftp 三.操作步骤 3.1 解压文件: $ tar zxvf jdk-8u131 ...
- Hadoop2.7.3+Spark2.1.0完全分布式集群搭建过程
1.选取三台服务器(CentOS系统64位) 114.55.246.88 主节点 114.55.246.77 从节点 114.55.246.93 从节点 之后的操作如果是用普通用户操作的话也必须知道r ...
- Hadoop2.7.3+Spark2.1.0 完全分布式环境 搭建全过程
一.修改hosts文件 在主节点,就是第一台主机的命令行下; vim /etc/hosts 我的是三台云主机: 在原文件的基础上加上; ip1 master worker0 namenode ip2 ...
- Apache Spark1.1.0部署与开发环境搭建
Spark是Apache公司推出的一种基于Hadoop Distributed File System(HDFS)的并行计算架构.与MapReduce不同,Spark并不局限于编写map和reduce ...
- Windows Server 2003 IIS6.0+PHP5(FastCGI)+MySQL5环境搭建教程
准备篇 一.环境说明: 操作系统:Windows Server 2003 SP2 32位 PHP版本:php 5.3.14(我用的php 5.3.10安装版) MySQL版本:MySQL5.5.25 ...
- Cocos2dx-3.0版本 从开发环境搭建(Win32)到项目移植Android平台过程详解
作为重量级的跨平台开发的游戏引擎,Cocos2d-x在现今的手游开发领域占有重要地位.那么问题来了,作为Cocos2dx的学习者,它的可移植特性我们就需要掌握,要不然总觉得少一门技能.然而这个时候各种 ...
- SDL2.0的VS开发环境搭建
SDL2.0的VS开发环境搭建 [前言] 我是用的是VS2012,VS的版本应该大致一样. [开发环境搭建] >>>SDL2.0开发环境配置:1.从www.libsdl.org 下载 ...
随机推荐
- Lastpass——密码管理工具
Lastpass是一个优秀的在线密码管理器和页面过滤器,采用了强大的加密算法,自动登录/云同步/跨平台/支持多款浏览器. 我之前一直都在使用这个工具,不过都是在浏览器上以扩展的方式使用,在火狐浏览器上 ...
- 使用Jmeter自带的 Http 代理服务器录制脚本
最近要测试某个模块的压力测试,所以使用Jmeter录制脚本 1. 打开JMeter工具 创建一个线程组(右键点击“测试计划”--->“添加”---->“线程组”) 创建一个ht ...
- "码率适配限速”,如何使带宽成本减少30%?
3月28日.29日,B站.爱奇艺即将先后完成IPO.爱奇艺的招股书显示,爱奇艺依然处于亏损状态.2015 年.2016 年.2017 年三年合计亏损约 94 亿元.高昂的版权费是造成视频网站亏损的重要 ...
- freeMark的入门教程
1.FreeMarker支持如下转义字符: \";双引号(u0022) \';单引号(u0027) \\;反斜杠(u005C) \n;换行(u000A) \r;回车(u000D) \t;Ta ...
- 在 Rolling Update 中使用 Health Check - 每天5分钟玩转 Docker 容器技术(146)
上一节讨论了 Health Check 在 Scale Up 中的应用,Health Check 另一个重要的应用场景是 Rolling Update.试想一下下面的情况: 现有一个正常运行的多副本应 ...
- Spring Boot Druid数据源配置
package com.hgvip.config; import com.alibaba.druid.pool.DruidDataSource; import com.alibaba.druid.su ...
- Algorithm --> 求N以内的真分数个数
求N以内的真分数个数 For example, if N = 5, the number of possible irreducible fractions are 11 as below. 0 1/ ...
- kill-mysql-sleep.sh
#!/bin/bash #while : #do n=`/usr/bin/mysqladmin -uroot -pXXXXX processlist | grep -i sleep | wc -l` ...
- linux挂载windows共享文件夹
1.建立共享文件夹 2.在linux中挂载共享目录 #mount -t cifs -o username=administrator,password=你的系统账号密码 //192.168.0.22/ ...
- Item 15: 只要有可能,就使用constexpr
本文翻译自modern effective C++,由于水平有限,故无法保证翻译完全正确,欢迎指出错误.谢谢! 博客已经迁移到这里啦 如果说C++11中有什么新东西能拿"最佳困惑奖" ...