Python之黏包的解决
黏包的解决方案
发生黏包主要是因为接收者不知道发送者发送内容的长度,因为tcp协议是根据数据流的,计算机操作系统有缓存机制,
所以当出现连续发送或连续接收的时候,发送的长度和接收的长度不匹配的情况下就会出现黏包。下面说几个处理方法:
解决方案一
问题的根源在于,接收端不知道发送端将要传送的字节流的长度,所以解决粘包的方法就是围绕,如何让发送端在发送数据前,
把自己将要发送的字节流总大小让接收端知晓,然后接收端来一个死循环接收完所有数据。
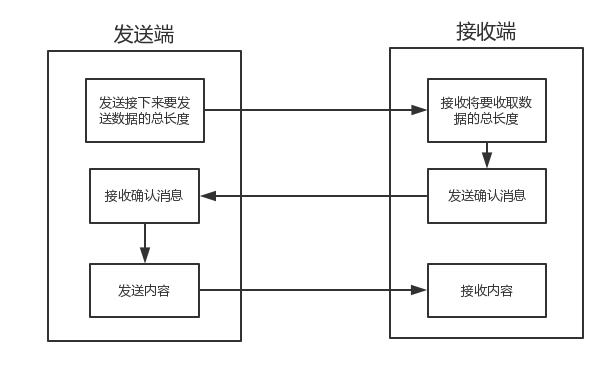
如图所示,即使发送了数据长度和数据内容,但在这两个发送的中间又插入了一个发送,所谓的 “确认信息” ,就是为了避免出现连续发送的情况
#_*_coding:utf-8_*_
import socket,subprocess
ip_port=('127.0.0.1',8080)
s=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
s.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1) s.bind(ip_port)
s.listen(5) while True:
conn,addr=s.accept()
print('客户端',addr)
while True:
msg=conn.recv(1024)
if not msg:break
res=subprocess.Popen(msg.decode('utf-8'),shell=True,\
stdin=subprocess.PIPE,\
stderr=subprocess.PIPE,\
stdout=subprocess.PIPE)
err=res.stderr.read()
if err:
ret=err
else:
ret=res.stdout.read()
data_length=len(ret)
conn.send(str(data_length).encode('utf-8'))
data=conn.recv(1024).decode('utf-8')
if data == 'recv_ready':
conn.sendall(ret)
conn.close() 服务端
服务端
#_*_coding:utf-8_*_
import socket,time
s=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
res=s.connect_ex(('127.0.0.1',8080)) while True:
msg=input('>>: ').strip()
if len(msg) == 0:continue
if msg == 'quit':break s.send(msg.encode('utf-8'))
length=int(s.recv(1024).decode('utf-8'))
s.send('recv_ready'.encode('utf-8'))
send_size=0
recv_size=0
data=b''
while recv_size < length:
data+=s.recv(1024)
recv_size+=len(data) print(data.decode('utf-8')) 客户端
客户端
存在的问题:
程序的运行速度远快于网络传输速度,所以在发送一段字节前,先用send去发送该字节流长度,这种方式会放大网络延迟带来的性能损耗
优点:
确实解决了黏包问题
解决方案二
这个方法不用发送数据的长度,在出现循环发送和接收或出现连续发送和接收的情况时,中间可以加上一句 time,sleep(1) 让程序停止一会,就会避免
数据流的缓存情况,但这种方法会显得很low,在传送大数据的情况下根本不适合,像是一种投机取巧的无奈之举。
解决方案二(高大上的解决方法)
可以借助一个模块,这个模块可以把要发送的数据长度转换成固定长度的字节。这样客户端每次接收消息之前只要先接受这个固定长度字节的内容
看一看接下来要接收的信息大小,那么最终接受的数据只要达到这个值就停止,就能刚好不多不少的接收完整的数据了。
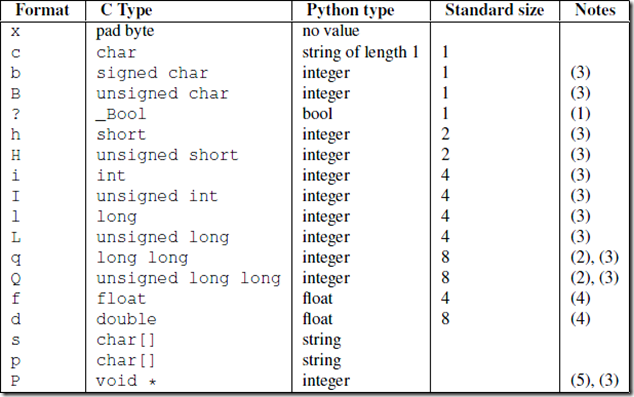
struct模块
该模块可以把一个类型,如数字,转成固定长度的bytes
>>> struct.pack('i',1111111111111)
struct.error: 'i' format requires -2147483648 <= number <= 2147483647 #这个是范围
import json,struct
#假设通过客户端上传1T:1073741824000的文件a.txt #为避免粘包,必须自定制报头
header={'file_size':1073741824000,'file_name':'/a/b/c/d/e/a.txt','md5':'8f6fbf8347faa4924a76856701edb0f3'} #1T数据,文件路径和md5值 #为了该报头能传送,需要序列化并且转为bytes
head_bytes=bytes(json.dumps(header),encoding='utf-8') #序列化并转成bytes,用于传输 #为了让客户端知道报头的长度,用struck将报头长度这个数字转成固定长度:4个字节
head_len_bytes=struct.pack('i',len(head_bytes)) #这4个字节里只包含了一个数字,该数字是报头的长度 #客户端开始发送
conn.send(head_len_bytes) #先发报头的长度,4个bytes
conn.send(head_bytes) #再发报头的字节格式
conn.sendall(文件内容) #然后发真实内容的字节格式 #服务端开始接收
head_len_bytes=s.recv(4) #先收报头4个bytes,得到报头长度的字节格式
x=struct.unpack('i',head_len_bytes)[0] #提取报头的长度 head_bytes=s.recv(x) #按照报头长度x,收取报头的bytes格式
header=json.loads(json.dumps(header)) #提取报头 #最后根据报头的内容提取真实的数据,比如
real_data_len=s.recv(header['file_size'])
s.recv(real_data_len)
#_*_coding:utf-8_*_
#http://www.cnblogs.com/coser/archive/2011/12/17/2291160.html
__author__ = 'Linhaifeng'
import struct
import binascii
import ctypes values1 = (1, 'abc'.encode('utf-8'), 2.7)
values2 = ('defg'.encode('utf-8'),101)
s1 = struct.Struct('I3sf')
s2 = struct.Struct('4sI') print(s1.size,s2.size)
prebuffer=ctypes.create_string_buffer(s1.size+s2.size)
print('Before : ',binascii.hexlify(prebuffer))
# t=binascii.hexlify('asdfaf'.encode('utf-8'))
# print(t) s1.pack_into(prebuffer,0,*values1)
s2.pack_into(prebuffer,s1.size,*values2) print('After pack',binascii.hexlify(prebuffer))
print(s1.unpack_from(prebuffer,0))
print(s2.unpack_from(prebuffer,s1.size)) s3=struct.Struct('ii')
s3.pack_into(prebuffer,0,123,123)
print('After pack',binascii.hexlify(prebuffer))
print(s3.unpack_from(prebuffer,0)) 关于struct的详细用法
使用struct解决黏包
借助struct模块,我们知道长度数字可以被转换成一个标准大小的4字节数字。因此可以利用这个特点来预先发送数据长度。
| 发送时 | 接收时 |
| 先发送struct转换好的数据长度4字节 | 先接受4个字节使用struct转换成数字来获取要接收的数据长度 |
| 再发送数据 |
再按照长度接收数据 |
import socket,struct,json
import subprocess
phone=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
phone.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1) #就是它,在bind前加 phone.bind(('127.0.0.1',8080)) phone.listen(5) while True:
conn,addr=phone.accept()
while True:
cmd=conn.recv(1024)
if not cmd:break
print('cmd: %s' %cmd) res=subprocess.Popen(cmd.decode('utf-8'),
shell=True,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE)
err=res.stderr.read()
print(err)
if err:
back_msg=err
else:
back_msg=res.stdout.read() conn.send(struct.pack('i',len(back_msg))) #先发back_msg的长度
conn.sendall(back_msg) #在发真实的内容 conn.close() 服务端(自定制报头)
服务端(自定制报头)
#_*_coding:utf-8_*_
import socket,time,struct s=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
res=s.connect_ex(('127.0.0.1',8080)) while True:
msg=input('>>: ').strip()
if len(msg) == 0:continue
if msg == 'quit':break s.send(msg.encode('utf-8')) l=s.recv(4)
x=struct.unpack('i',l)[0]
print(type(x),x)
# print(struct.unpack('I',l))
r_s=0
data=b''
while r_s < x:
r_d=s.recv(1024)
data+=r_d
r_s+=len(r_d) # print(data.decode('utf-8'))
print(data.decode('gbk')) #windows默认gbk编码 客户端(自定制报头)
客户端(自定制报头)
我们还可以把报头做成字典,字典里包含将要发送的真实数据的详细信息,然后json序列化,然后用struck将序列化后的数据长度打包成4个字节(4个自己足够用了)
| 发送时 | 接收时 |
|
先发报头长度 |
先收报头长度,用struct取出来 |
| 再编码报头内容然后发送 | 根据取出的长度收取报头内容,然后解码,反序列化 |
| 最后发真实内容 | 从反序列化的结果中取出待取数据的详细信息,然后去取真实的数据内容 |
import socket,struct,json
import subprocess
phone=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
phone.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1) #就是它,在bind前加 phone.bind(('127.0.0.1',8080)) phone.listen(5) while True:
conn,addr=phone.accept()
while True:
cmd=conn.recv(1024)
if not cmd:break
print('cmd: %s' %cmd) res=subprocess.Popen(cmd.decode('utf-8'),
shell=True,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE)
err=res.stderr.read()
print(err)
if err:
back_msg=err
else:
back_msg=res.stdout.read() headers={'data_size':len(back_msg)}
head_json=json.dumps(headers)
head_json_bytes=bytes(head_json,encoding='utf-8') conn.send(struct.pack('i',len(head_json_bytes))) #先发报头的长度
conn.send(head_json_bytes) #再发报头
conn.sendall(back_msg) #在发真实的内容 conn.close() 服务端:定制稍微复杂一点的报头
from socket import *
import struct,json ip_port=('127.0.0.1',8080)
client=socket(AF_INET,SOCK_STREAM)
client.connect(ip_port) while True:
cmd=input('>>: ')
if not cmd:continue
client.send(bytes(cmd,encoding='utf-8')) head=client.recv(4)
head_json_len=struct.unpack('i',head)[0]
head_json=json.loads(client.recv(head_json_len).decode('utf-8'))
data_len=head_json['data_size'] recv_size=0
recv_data=b''
while recv_size < data_len:
recv_data+=client.recv(1024)
recv_size+=len(recv_data) print(recv_data.decode('utf-8'))
#print(recv_data.decode('gbk')) #windows默认gbk编码 客户端
Python之黏包的解决的更多相关文章
- python tcp黏包和struct模块解决方法,大文件传输方法及MD5校验
一.TCP协议 粘包现象 和解决方案 黏包现象让我们基于tcp先制作一个远程执行命令的程序(命令ls -l ; lllllll ; pwd)执行远程命令的模块 需要用到模块subprocess sub ...
- Python 的黏包问题
Client 端内的代码: #Author:BigBao #Date:2018/7/4 import socket import struct client=socket.socket(socket. ...
- Python之黏包
黏包现象 让我们基于tcp先制作一个远程执行命令的程序(命令ls -l ; lllllll ; pwd) res=subprocess.Popen(cmd.decode('utf-8'), shell ...
- python之黏包和黏包解决方案
黏包现象主要发生在TCP连接, 基于TCP的套接字客户端往服务端上传文件,发送时文件内容是按照一段一段的字节流发送的,在接收方看来,根本不知道该文件的字节流从何处开始,在何处结束. 两种黏包现象: 1 ...
- struct模块-黏包的解决方法
黏包的解决方案 解决方案一 问题的根源在于,接收端不知道发送端将要传送的字节流的长度,所以解决粘包的方法就是围绕,如何让发送端在发送数据前,把自己将要发送的字节流总大小让接收端知晓,然后接收端来一个死 ...
- python中黏包现象
#黏包:发送端发送数据,接收端不知道应如何去接收造成的一种数据混乱现象. #关于分包和黏包: #黏包:发送端发送两个字符串"hello"和"word",接收方却 ...
- 命令行下执行python找不包的解决方法
首先我们来了解一下,为什么会出现这样的问题,以及python搜索包的机制是怎么样的 1.为什么会出现这样的问题? 包是向下搜索机制. 2.为什么ide中执行没有报找不到包的问题? python搜索机制 ...
- Python Socket通信黏包问题分析及解决方法
参考:http://www.cnblogs.com/Eva-J/articles/8244551.html#_label5 1.黏包的表现(以客户端远程操作服务端命令为例) 注:只有在TCP协议通信的 ...
- 黏包-黏包的成因、解决方式及struct模块初识、文件的上传和下载
黏包: 同时执行多条命令之后,得到的结果很可能只有一部分,在执行其他命令的时候又接收到之前执行的另外一部分结果,这种显现就是黏包. 只有TCP协议中才会产生黏包,UDP协议中不会有黏包(udp协议中数 ...
随机推荐
- Canvas 画布组件(官网翻译)
Canvas画布 The Canvas is the area that all UI elements should be inside. The Canvas is a Game Object w ...
- MSIL实用指南-创建枚举类型
创建枚举类型比较简单,主要使用moduleBuilder.DefineEnum 和enumBuilder.DefineLiteral. 第一步:创建 EnumBuilder 创建 EnumBuilde ...
- Maven打包的三种方式(转)
Maven可以使用mvn package指令对项目进行打包,如果使用Java -jar xxx.jar执行运行jar文件,会出现"no main manifest attribute, in ...
- jQuery学习笔记之extend方法小结
在学习jQuery的时候,学习到了$.extend的主要用法,在此做一个简单的总结. (1)当只写一个对象自变量时,拓展的是jQuery的工具方法,如: $.extend({ aaa:function ...
- Online Judge(OJ)搭建——3、MVC架构
Model Model 层主要包含数据的类,这些数据一般是现实中的实体,所以,Model 层中类的定义常常和数据库 DDL 中的 create 语句类似. 通常数据库的表和类是一对一的关系,但是有的时 ...
- 面向对象写的简单的colors rain
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> < ...
- K-Means 聚类
机器学习中的算法主要分为两类,一类是监督学习,监督学习顾名思义就是在学习的过程中有人监督,即对于每一个训练样本,有对应的标记指明它的类型.如识别算法的训练集中猫的图片,在训练之前会人工打上标签,告诉电 ...
- JAVAEE——BOS物流项目08:配置代理对象远程调用crm服务、查看定区中包含的分区、查看定区关联的客户
1 学习计划 1.定区关联客户 n 完善CRM服务中的客户查询方法 n 在BOS项目中配置代理对象远程调用crm服务 n 调整定区关联客户页面 n 实现定区关联客户 2.查看定区中包含的分区 n 页面 ...
- Django之ORM基础
ORM简介 ORM概念 对象关系映射(Object Relational Mapping,简称ORM)模式是一种为了解决面向对象与关系数据库存在的互不匹配的现象的技术. 简单的说,ORM是通过使用描述 ...
- 使用pm2躺着实现负载均衡
事实上,pm2 是一个带有负载均衡功能的Node应用的进程管理器,Node实现进程管理的库有很多,forever也是其中一个很强大但是也相对较老的进程管理器. 为什么要使用pm2 对于这个问题,先说说 ...