Python爬虫获取异步加载站点pexels并下载图片(Python爬虫实战3)
1. 异步加载爬虫
对于静态页面爬虫很容易获取到站点的数据内容,然而静态页面需要全量加载站点的所有数据,对于网站的访问和带宽是巨大的挑战,对于高并发和大访问访问量的站点来说,需要使用AJAX相关的技术来实现异步加载,即根据需要来获取数据,以pexels网站为例,按F12,切换到Network的XHR标签,通过下拉菜单访问该站点,此时数据会以此加载,在XHR页面中会逐步增加访问的URL地址,点击查看其中一个URL地址,发现其URL的地址类似为:https://www.pexels.com/search/book/?page=3&seed=2018-02-22+05:21:39++0000&format=js&seed=2018-02-22 05:21:39 +0000,将其修改为https://www.pexels.com/search/book/?page=3,并修改page后面数的值发现可以访问到不同的页面内容,以此来构造需要访问的url站点内容。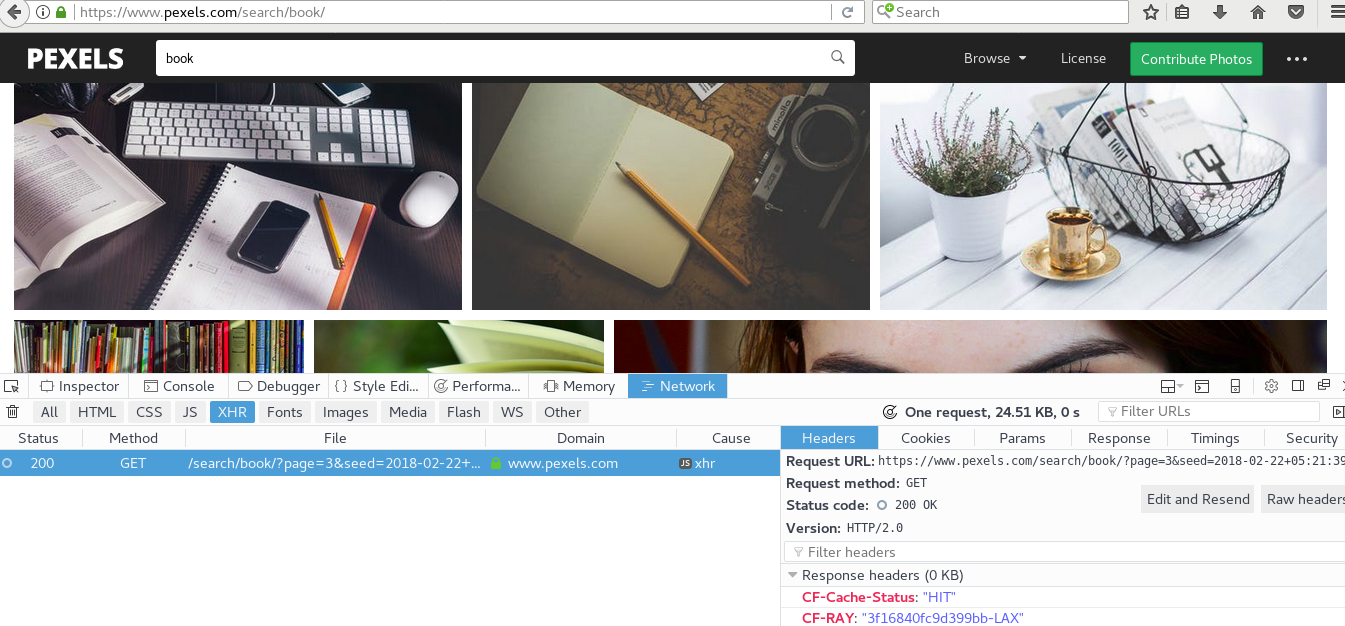
2. 代码内容
#!/usr/bin/python
#_*_ coding:utf _*_
#author: HappyLau
#blog: https://www.cnblogs.com/cloudlab import os
import sys
import time
import os.path
import random
import requests
from lxml import etree reload(sys)
sys.setdefaultencoding('utf8') def get_jianshu(url):
'''
demo简书网站的获取信息
'''
headers = {"User-Agent": "Mozilla/5.0 (X11; Linux x86_64; rv:52.0) Gecko/20100101 Firefox/52.0"}
try:
req = requests.get(url,headers=headers)
if req.status_code == 200:
return req.text.encode('utf8')
else:
return ''
except Exception as e:
print e def get_picture(url,download_dir):
'''
@params:获取url中的图片信息,并将其下载到download_dir目录中
@download_dir:图片下载的本地路径
'''
if not os.path.exists(download_dir):
os.mkdir(download_dir)
html = get_jianshu(url)
selector = etree.HTML(html)
for url in selector.xpath('//img[@class="photo-item__img"]/@src'):
picture_name = url.split("?")[0].split("/")[-1]
print "downloading picutre %s" % (picture_name)
with file(download_dir + picture_name,'wb') as f:
f.write(requests.get(url).content)
time.sleep(random.randint(1,3)) if __name__ == "__main__":
url_lists = ['https://www.pexels.com/search/book/?page={}'.format(i) for i in range(1,21)]
for url in url_lists:
get_picture(url,'/root/pexels')
3. 下载图片使用方式
上面使用requests.get().content的方式来实现下载图片的方法,还可以通过urllib.urlretrieve()方法来实现图片的下载功能,该函数的使用参数为:retrieve(self, url, filename=None, reporthook=None, data=None),其中url地址为需要访问的url路径,filename为本地存放图片的路径,修改代码内容如下:
#!/usr/bin/python
#_*_ coding:utf _*_
#author: HappyLau
#blog: https://www.cnblogs.com/cloudlab import os
import sys
import time
import os.path
import random
import requests
import urllib
from lxml import etree reload(sys)
sys.setdefaultencoding('utf8') def get_jianshu(url):
'''
demo简书网站的获取信息
'''
headers = {"User-Agent": "Mozilla/5.0 (X11; Linux x86_64; rv:52.0) Gecko/20100101 Firefox/52.0"}
try:
req = requests.get(url,headers=headers)
if req.status_code == 200:
return req.text.encode('utf8')
else:
return ''
except Exception as e:
print e def get_picture(url,download_dir):
'''
@params:获取url中的图片信息,并将其下载到download_dir目录中
@download_dir:图片下载的本地路径
通过利用urllib模块中的urlretrieve()方法实现图片的下载功能
'''
if not os.path.exists(download_dir):
os.mkdir(download_dir)
html = get_jianshu(url)
selector = etree.HTML(html)
for url in selector.xpath('//img[@class="photo-item__img"]/@src'):
picture_name = download_dir + "/" + url.split("?")[0].split("/")[-1]
print "downloading picutre %s" % (picture_name)
urllib.urlretrieve(url,picture_name) #下载图片
time.sleep(random.randint(1,3)) if __name__ == "__main__":
url_lists = ['https://www.pexels.com/search/book/?page={}'.format(i) for i in range(1,21)]
for url in url_lists:
get_picture(url,'/root/pexels')
Python爬虫获取异步加载站点pexels并下载图片(Python爬虫实战3)的更多相关文章
- 【vue】获取异步加载后的数据
异步请求的数据,对它做一些处理,需要怎么做呢?? axios 异步请求数据,得到返回的数据, 赋值给变量 info .如果要对 info 的数据做一些处理后再赋值给 hobby ,直接在 axios ...
- Python 爬取异步加载的数据
在我们的工作中,可能会遇到这样的情况:我们需要爬取的数据是通过ajax异步加载的,这样的话通过requests得到的只是一个静态页面,而我们需要的是ajax动态加载的数据! 那我们应该怎么办呢??? ...
- Java 爬虫遇上数据异步加载,试试这两种办法!
这是 Java 爬虫系列博文的第三篇,在上一篇 Java 爬虫遇到需要登录的网站,该怎么办? 中,我们简单的讲解了爬虫时遇到登录问题的解决办法,在这篇文章中我们一起来聊一聊爬虫时遇到数据异步加载的问题 ...
- UIImageView异步加载网络图片
在iOS开发过程中,经常会遇到使用UIImageView展现来自网络的图片的情况,最简单的做法如下: 去下载https://github.com/rs/SDWebImage放进你的工程里,加入头文件# ...
- 多线程异步加载图片async_pictures
异步加载图片 目标:在表格中异步加载网络图片 目的: 模拟 SDWebImage 基本功能实现 理解 SDWebImage 的底层实现机制 SDWebImage 是非常著名的网络图片处理框架,目前国内 ...
- Unity 异步加载场景
效果图如下: 今天一直在纠结如何加载场景,中间有加载画面和加载完毕的效果动画! A 场景到 B , 看见网上的做法都是 A –> C –> B. C场景主要用于异步加载B 和 播放一些 ...
- ios UIImageView异步加载网络图片
方法1:在UI线程中同步加载网络图片 UIImageView *headview = [[UIImageView alloc] initWithFrame:CGRectMake(0, 0, 40, 4 ...
- Android批量图片加载经典系列——使用xutil框架缓存、异步加载网络图片
一.问题描述 为提高图片加载的效率,需要对图片的采用缓存和异步加载策略,编码相对比较复杂,实际上有一些优秀的框架提供了解决方案,比如近期在git上比较活跃的xutil框架 Xutil框架提供了四大模块 ...
- [翻译]Bitmap的异步加载和缓存
内容概述 [翻译]开发文档:android Bitmap的高效使用 本文内容来自开发文档"Traning > Displaying Bitmaps Efficiently", ...
随机推荐
- Spring Boot : Whitelabel Error Page解决方案
楼主最近爱上了一个新框架--Spring Boot, 搭建快还不用写一堆xml,最重要的是自带Tomcat 真是好 pom.xml <?xml version="1.0" e ...
- 在ASP.Net Core下,Autofac实现自动注入
之前使用以来注入的时候,都是在xml配置对应的接口和实现类,经常会出现忘了写配置,导致注入不生效,会报错,而且项目中使用的是SPA的模式,ajax报错也不容易看出问题,经常会去排查日志找问题. 于是在 ...
- ICQ
我一直都想编一个自己的聊天软件,像QQ那种:最近有时间我就自己编了一个.编写的过程中收获很大…… 现在拿出来跟大家分享,有兴趣的朋友可以和我交流交流. 先给大家看一下效果: 启动服务器: 再给大家看一 ...
- Java数字签名——DSA算法
RSA数字加密算法参考:http://www.cnblogs.com/LexMoon/p/javaRSA.html DSS: 数字签名标准 DSA: 数字签名算法 DSA仅仅包含数字签名 —————— ...
- Android ADB Server启动失败
启动Android Stdio的时候报如下错误: Unable to create Debug Bridge: Unable to start adb server: error: could not ...
- 总结JS中string、math、array的常用的方法
JS为每种数据类型都内置很多方法,真的不好记忆,而且有些还容易记混,现整理如下,以便以后查看: 一.String ①charAt()方法用于返回指定索引处的字符.返回的字符是长度为 1 的字符串. 语 ...
- 由select引发的思考
一.前言 网络编程里一个经典的问题,selec,poll和epoll的区别?这个问题刚学习编程时就接触了,当时看了材料很不明白,许多概念和思想没有体会,现在在这个阶段,再重新回头看这个问题,有一种豁然 ...
- 浅谈JavaScript位操作符
因为ECMAscript中所有数值都是以IEEE-75464格式存储,所以才会诞生了位操作符的概念. 位操作符作用于最基本的层次上,因为数值按位存储,所以位操作符的作用也就是操作数值的位.不过位操作符 ...
- 解决ios不支持按钮:active伪类的方法
mozilla开发社区上有 :active 不起作用的答案: [1] By default, Safari Mobile does not use the :active state unless t ...
- canvas API总结
从简单的基本图形,到复杂炫酷的动画,通过canvas元素获取的2D图形渲染上下文CanvasRenderingContext2D,能够使用丰富的API来进行图形绘制.这篇文章将会总结在之前的canva ...