pandas 对数据帧DataFrame中数据的索引及切片操作
1、创建数据帧
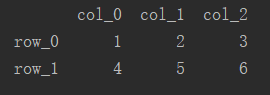
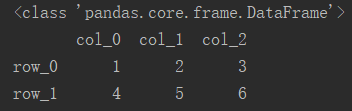
index是行索引,即每一行的名字;columns是列索引,即每一列的名字。建立数据帧时行索引和列索引都需要以列表的形式传入。
import pandas as pd
df = pd.DataFrame([[1, 2, 3], [4, 5, 6]], index=['row_0', 'row_1'], columns=['col_0', 'col_1', 'col_2'])
2、获取数据帧的行索引和列索引
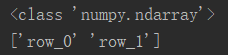
2.1 获取行索引
# 以数组形式返回
row_name = df.index.values
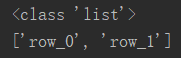
# 以列表形式返回
row_name = df.index.values.tolist()
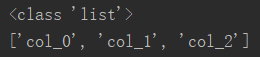
2.2 获取列索引
# 以数组的形式返回
col_name = df.columns.values

# 以列表的形式返回
col_name = df.columns.values.tolist()
3、获取指定行、列的元素
3.1 获取指定行的元素
获取某行数据需用.loc[]或.iloc[]方法,不能直接索引。
# 以行名索引,返回一个系列(series)
df_row0 = df.loc['row_0']
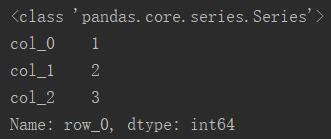
# 以行的绝对位置索引,返回一个系列(series)
df_row0 = df.iloc[0]

3.2 获取指定列的元素
获取某列数据可以通过列名直接索引。
# 以列名索引,返回一个系列(series)
df_col0 = df['col_0']
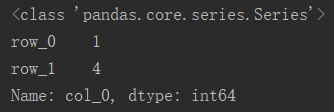
索引某列不能直接通过列的绝对位置来索引,但可以转换思路,借助列索引值实现用绝对位置的间接索引。
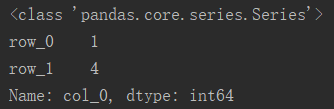
# df_col0 = df[0] 通过绝对位置直接索引报错
# 通过列索引名 df.columns 实现对列的绝对位置索引
df_col0 = df[df.columns[0]]
4、对数据帧切片
4.1 行切片
对行进行切片操作,可以通过.iloc[]方法或直接用行的绝对位置。不能通过行名进行切片操作。
# 通过iloc[]方法切片,[0:2]左闭右开,即切取第0行和第1行
df_row = df.iloc[0:2]
# 通过行的绝对位置切片,[0:2]左闭右开,即切取第0行和第1行
df_row = df[0:2]
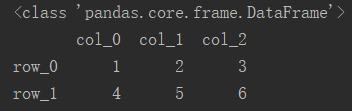
4.2 列切片
对列进行切片时,可以将所需要切取的列的列名组成一个一维的列表或数组,直接传入df[]即可。
# df_col = df[df.columns[0:2]] 切取第0列和第1列,与下句代码等价
df_col = df[['col_0', 'col_1']]
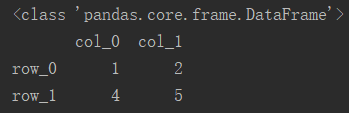
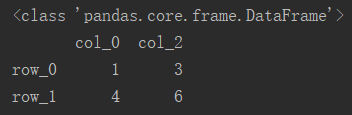
4.3 局部切片
先进行行切片,再进行列切片即可。
# 切取第0行和第1行,'col_0'和'col_2'列
df_new = df[0:2][['col_0', 'col_2']]
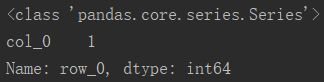
5、获取某位置元素
5.1 通过行、列定位
# 通过行列定位,返回值为一个系列(series)
df_new = df.loc['row_0'][['col_0']]
5.2 通过.at[]方法
# 用行名和列名索引,返回该位置的具体元素
df_new = df.at['row_0', 'col_0']

5.3 通过.iat[]方法
# 用行列的绝对位置定位,返回该位置的具体元素
df_new = df.iat[0,0]

小结:对行操作一般通过df.iloc[绝对位置]或df.loc[‘行名’],对列操作直接用df[‘列名’]
pandas 对数据帧DataFrame中数据的索引及切片操作的更多相关文章
- pandas 对数据帧DataFrame中数据的增删、补全及转换操作
1.创建数据帧 import pandas as pd df = pd.DataFrame([[1, 'A', '3%' ], [2, 'B'], [3, 'C', '5%']], index=['r ...
- pandas | 如何在DataFrame中通过索引高效获取数据?
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是pandas数据处理专题的第四篇文章,我们一起来聊聊DataFrame中的索引. 上一篇文章当中我们介绍了DataFrame数据结构当 ...
- pandas,对dataFrame中某一个列的数据进行处理
背景:dataFrame的数据,想对某一个列做逻辑处理,生成新的列,或覆盖原有列的值 下面例子中的df均为pandas.DataFrame()的数据 1.增加新列,或更改某列的值 df[&qu ...
- pandas | 详解DataFrame中的apply与applymap方法
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是pandas数据处理专题的第5篇文章,我们来聊聊pandas的一些高级运算. 在上一篇文章当中,我们介绍了panads的一些计算方法, ...
- pandas 获取数据帧DataFrame的行、列数
1.创建数据帧 import pandas as pd df = pd.DataFrame([[1, 'A', '3%' ], [2, 'B']], index=['row_0', 'row_1'], ...
- Pandas:将DataFrame中的一列转化为List
#假设data是一个DataFrame对象,如果要把它的第二列转换为List print(data.iloc[:,1].to_list())
- 数据可视化基础专题(七):Pandas基础(六) 数据增删改以及相关操作
首先第一部还是导入 Pandas 与 NumPy ,并且要生成一个 DataFrame ,这里小编就简单的使用随机数的形式进行生成,代码如下: import numpy as np import pa ...
- python中str的索引、切片
1 a = "hello" 2 a1 = a[1] 3 a2 = a[0:2] 4 print(a1) 5 print(a2) 我们通过索引获取字符串中指定位数的字符 通过切片获取 ...
- 控制台程序实现利用CRM组织服务和SqlConnection对数据库中数据的增删改查操作
一.首先新建一个控制台程序.命名为TestCol. 二.打开App.config在里面加入,数据库和CRM连接字符串 <connectionStrings> <add name=&q ...
随机推荐
- golang map的判断,删除
http://blog.sina.com.cn/s/blog_9e14446a01018q8p.html map是一种key-value的关系,一般都会使用make来初始化内存,有助于减少后续新增操作 ...
- Python反序列化 pickle
# 若需要处理更复杂的数据, 用pickle. pickle只有在Python里能用, 其它语言不行. # 序列化. import pickle def sayhi(name): print('hel ...
- substr函数的用法
敲了几个demo,结果如下 substr(字符串,截取开始位置,截取长度) //返回截取的字 substr('1234567890',0,5) :返回结果为 '12345' *从字符串第一个字符开始截 ...
- nsq源码阅读笔记之nsqd(一)——nsqd的配置解析和初始化
配置解析 nsqd的主函数位于apps/nsqd.go中的main函数 首先main函数调用nsqFlagset和Parse进行命令行参数集初始化, 然后判断version参数是否存在,若存在,则打印 ...
- 【codeforces 698B】 Fix a Tree
题目链接: http://codeforces.com/problemset/problem/698/B 题解: 还是比较简单的.因为每个节点只有一个父亲,可以直接建反图,保证出现的环中只有一条路径. ...
- BZOJ_2734_[HNOI2012]集合选数_构造+状压DP
BZOJ_2734_[HNOI2012]集合选数_构造+状压DP 题意:<集合论与图论>这门课程有一道作业题,要求同学们求出{1, 2, 3, 4, 5}的所有满足以 下条件的子集:若 x ...
- BZOJ_3262_陌上花开_CDQ分治+树状数组
BZOJ_3262_陌上花开_CDQ分治+树状数组 Description 有n朵花,每朵花有三个属性:花形(s).颜色(c).气味(m),用三个整数表示. 现在要对每朵花评级,一朵花的级别是它拥有的 ...
- resteasy简单实例
1.建一个maven web项目 新建一个maven项目,next,第一个框不要勾选 选择maven-archetype-webapp,建一个web项目 键入项目组织id与项目id 一般此时搭建的只是 ...
- Lucene 源码分析之倒排索引(三)
上文找到了 collect(-) 方法,其形参就是匹配的文档 Id,根据代码上下文,其中 doc 是由 iterator.nextDoc() 获得的,那 DefaultBulkScorer.itera ...
- mysql5.7连接不上可能的问题(针对新安装的mysql5.7可能出现的问题)
"ERROR 2003 (HY000): Can't connect to MySQL server on 'localhost' (10061)" 今天刚刚安装好的mysql5. ...