Python 爬虫——抖音App视频抓包
APP抓包
前面我们了解了一些关于 Python 爬虫的知识,不过都是基于 PC 端浏览器网页中的内容进行爬取。现在手机 App 用的越来越多,而且很多也没有网页端,比如抖音就没有网页版,那么上面的视频就没法批量抓取了吗?
答案当然是 No!对于 App 来说应用内的通信过程和网页是类似的,都是向后台发送请求,获取数据。在浏览器中我们打开调试工具就可以看到具体的请求内容,在 App 中我们无法直接看到。所以我们就要通过抓包工具来获取到 App 请求与响应的信息。关于抓包工具有 Wireshark,Fiddler,Charles等。今天我们讲一下如何用 Fiddler 进行手机 App 的抓包。
Fiddler 的工作原理相当于一个代理,配置好以后,我们从手机 App 发送的请求会由 Fiddler 发送出去,服务器返回的信息也会由 Fiddler 中转一次。所以通过 Fiddler 我们就可以看到 App 发给服务器的请求以及服务器的响应了。
Fiddler 安装配置
我们安装好 Fiddler 后,首先在菜单 Tool>Options>Https 下面的这两个地方选上。
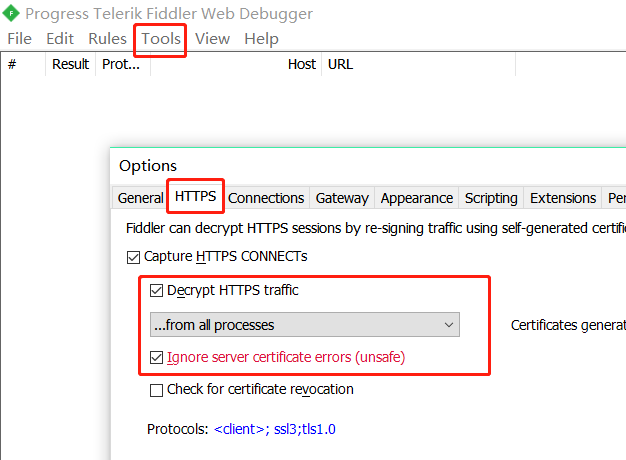
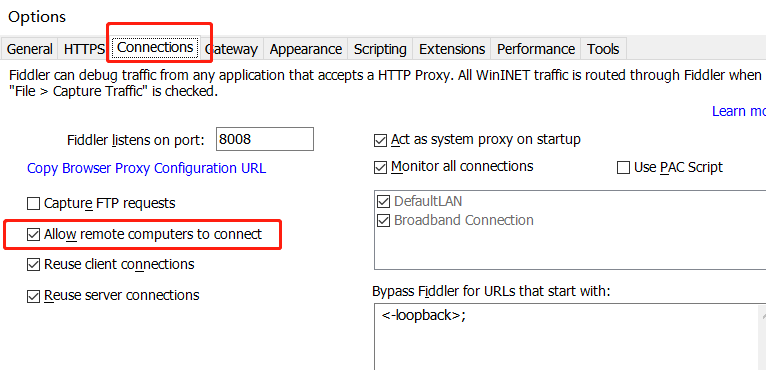
然后在 Connections 标签页下面勾选上 Allow remote computers to connect,允许 Fiddler 接受其他设备的请求。
同时要记住这里的端口号,默认是 8088,到时候需要在手机端填。
配置完毕,保存后,一定关掉 Fiddler 重新打开。
手机端配置
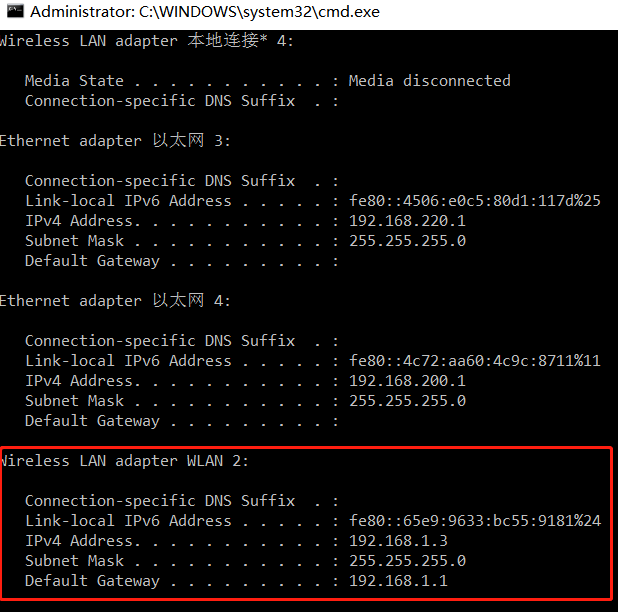
确保手机和电脑在同一个局域网中,我们先看下计算机的 IP 地址,在 cmd 中输入 ipconfig 就可以看到。我电脑用的是无线网,所以 IP 地址为 192.168.1.3。
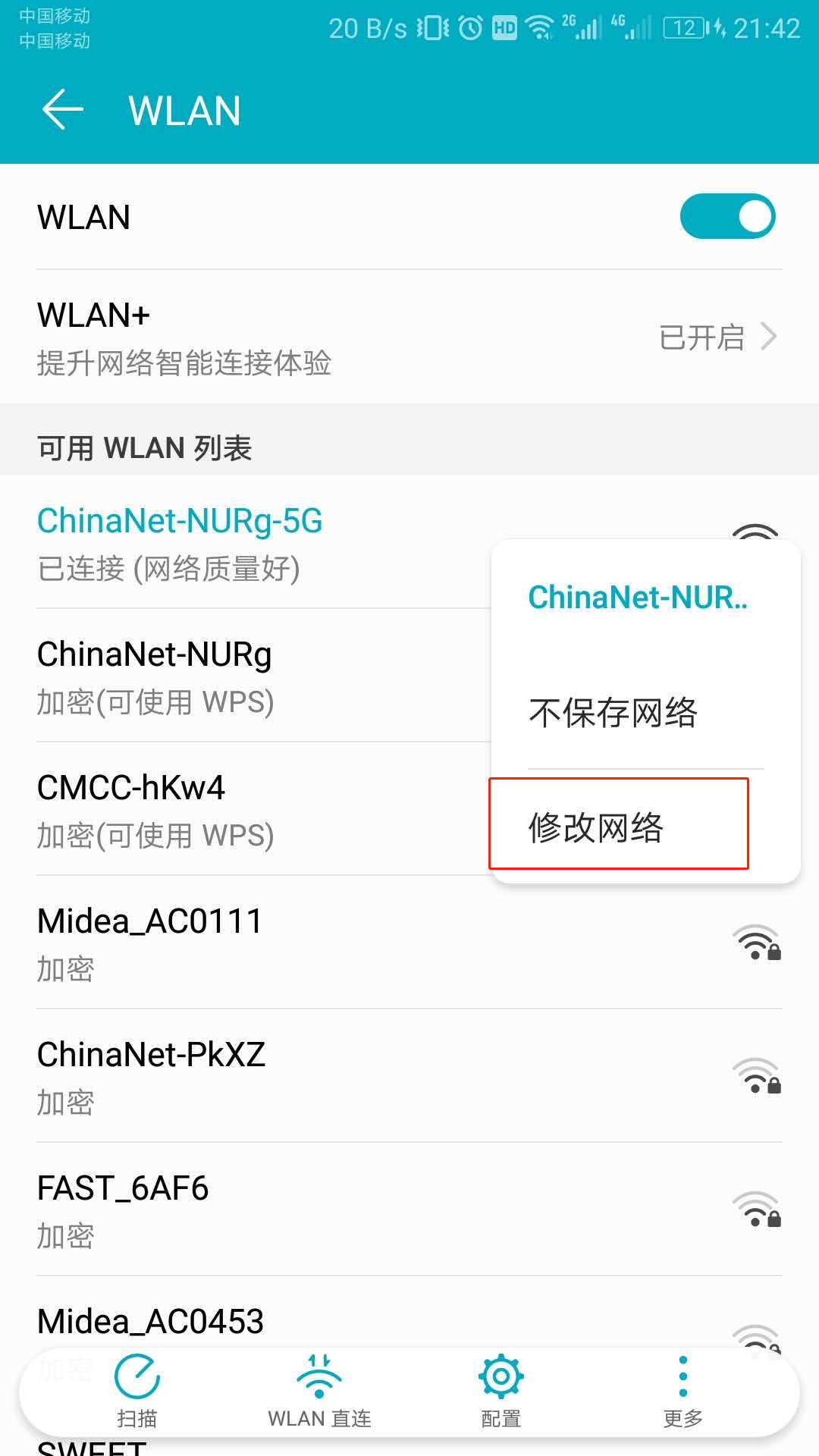
打开手机无线连接,选择要连接的热点。长按选择修改网络,在代理中填上我们电脑的 IP 地址和 Fiddler 代理的端口。如下图所示:
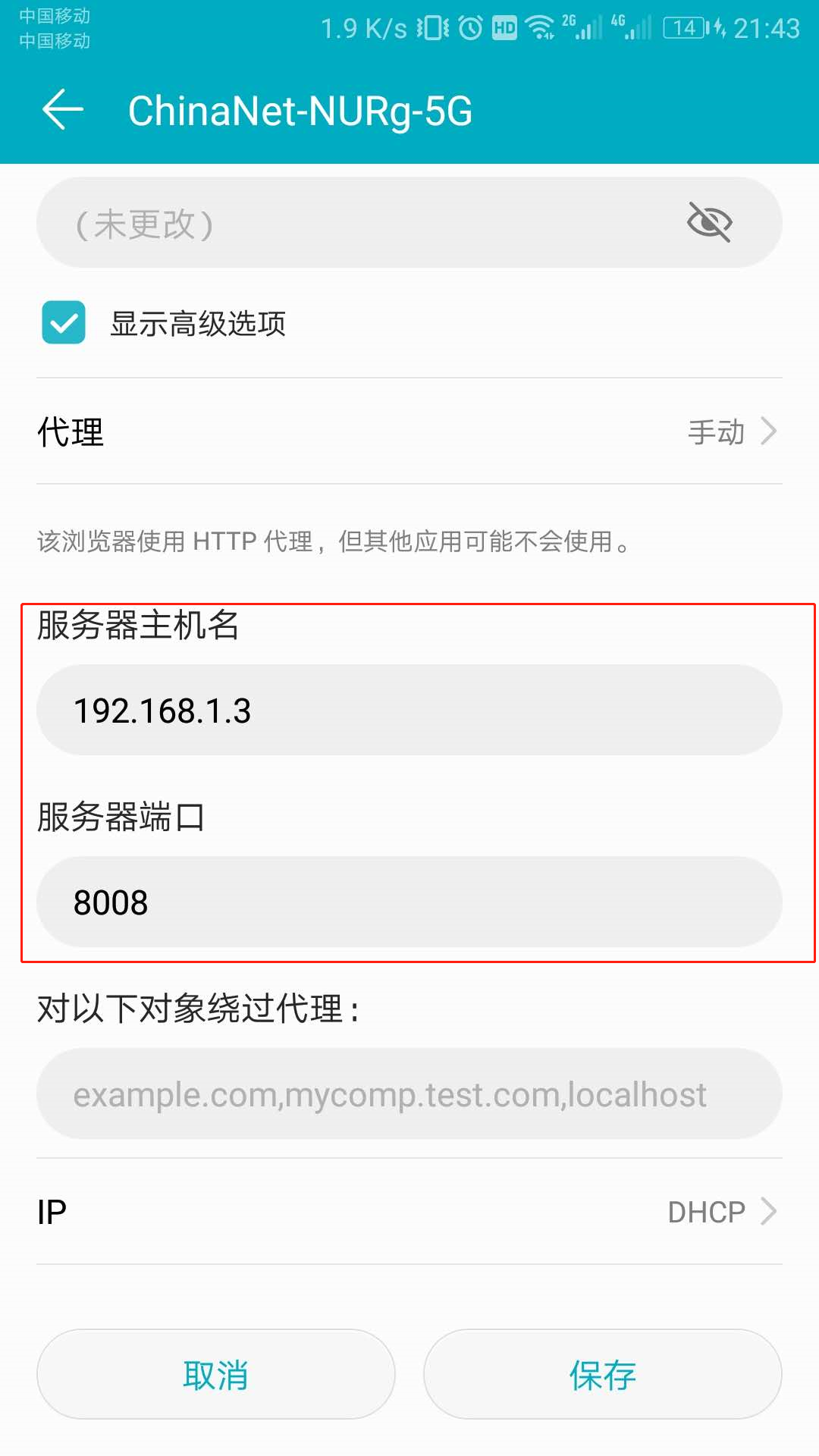
保存后,在手机原生浏览器打开 http://192.168.1.3:8008 ,就是上面我们的计算机 IP 和端口。这一步我在夸克浏览器中打开是不行的,一定要到手机自带的浏览器打开。
打开后,点击下图链接,下载证书,然后安装证书。
电脑端浏览器也需要打开此地址,安装证书,方便以后对浏览器的抓包操作。
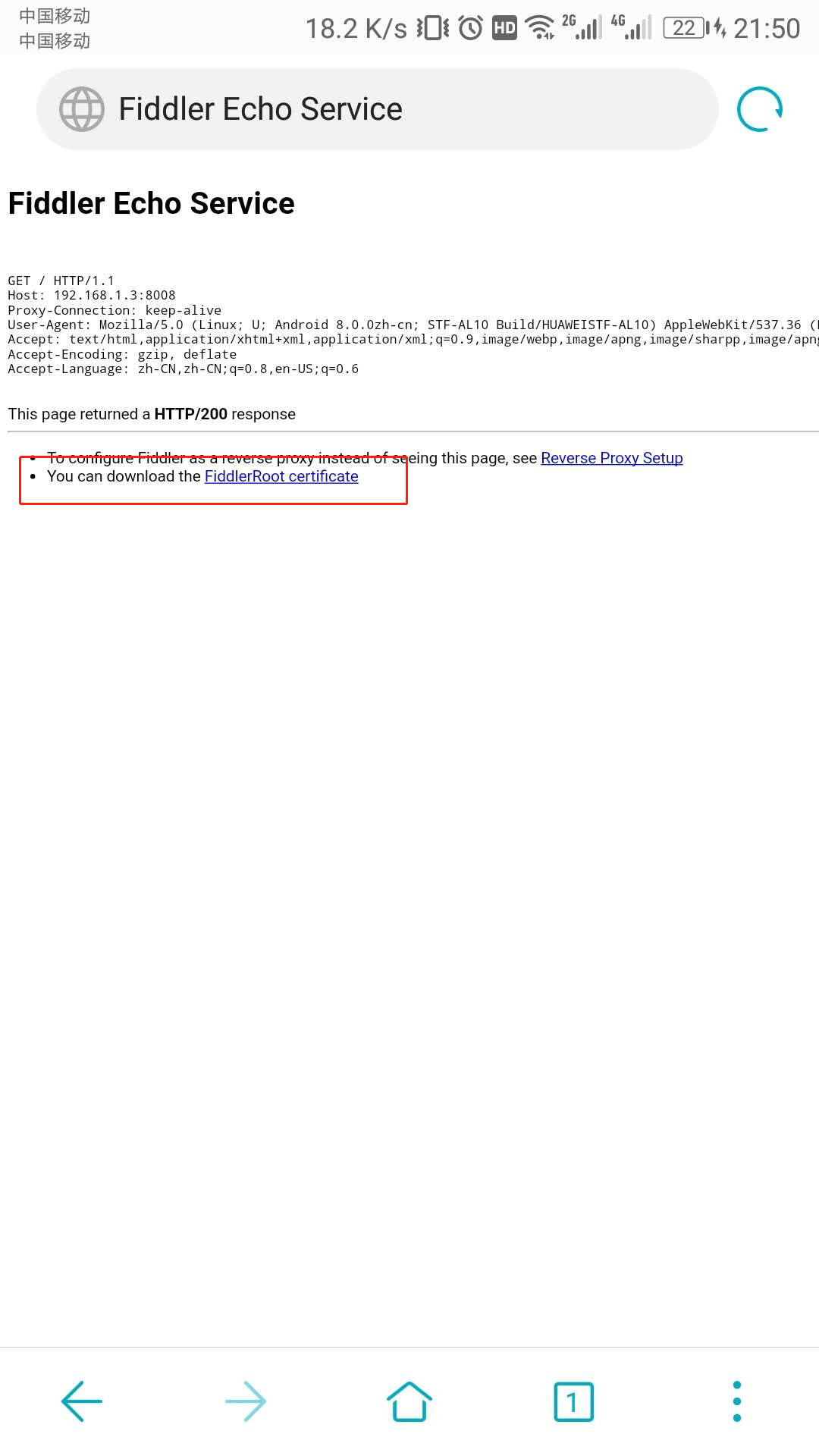
安装后就万事 OK 了,可以用手机打开 App ,在 Fiddler 上愉快的抓包了。
抓包
我们打开抖音 App,会发现 Fiddler 上出来很多连接。我们先清空没用的连接信息,然后滑动到某个人的主页上,来查看他发布过的所有视频,同时在 Fiddler 上找到视频链接。
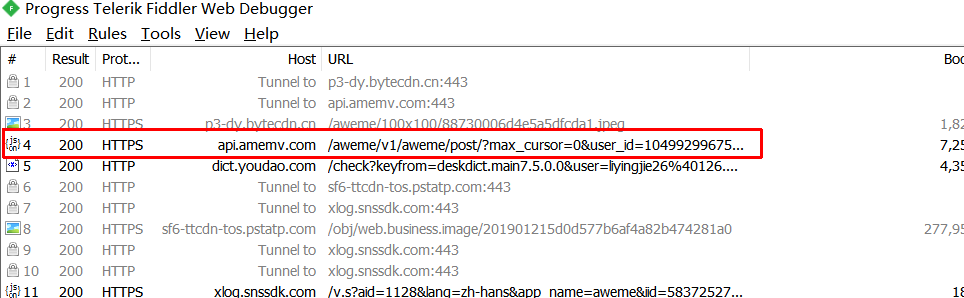
经过观察筛选我们可以看出上图就是我们需要的请求地址,这个地址其实是可以在浏览器上打开的,但是我们需要改一下浏览器的User-Agent,我用的是Firefox的插件,打开后和 Fiddler 右边的信息是一致的。我们看下 Fiddler 右边该请求的响应信息。
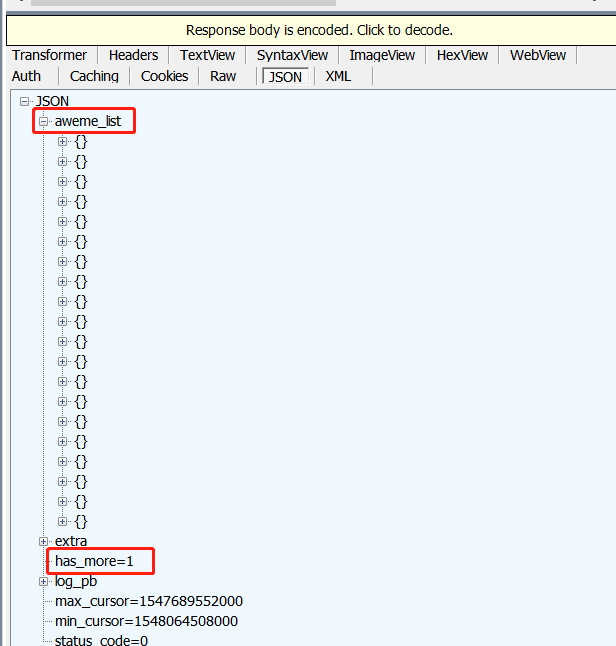
看到返回了一个 JSON 格式的信息,其中aweme_list 就是我们需要的视频地址,has_more=1 表示往上滑动还会加载更多。之后就可以写代码了。
代码
代码很简单,和我们前几篇讲的一样,直接用 requests 请求相应链接即可。
代码仅做为一个简单的例子,仅仅下载当前页面的内容,如果要下载全部的视频,可以根据当次返回 JSON 结果中的 has_more 和 max_cursor 参数构造出新的 URL 地址不断的下载。
URL 中的 user_id 可以根据自己要爬取的用户更改,可以通过把用户分享到微信,然后在浏览器中打开链接,在打开的 URL 中可以看到用户的 user_id。
import requests
import urllib.request
def get_url(url):
headers = {'user-agent': 'mobile'}
req = requests.get(url, headers=headers, verify=False)
data = req.json()
for data in data['aweme_list']:
name = data['desc'] or data['aweme_id']
url = data['video']['play_addr']['url_list'][0]
urllib.request.urlretrieve(url, filename=name + '.mp4')
if __name__ == "__main__":
get_url('https://api.amemv.com/aweme/v1/aweme/post/?max_cursor=0&user_id=98934041906&count=20&retry_type=no_retry&mcc_mnc=46000&iid=58372527161&device_id=56750203474&ac=wifi&channel=huawei&aid=1128&app_name=aweme&version_code=421&version_name=4.2.1&device_platform=android&ssmix=a&device_type=STF-AL10&device_brand=HONOR&language=zh&os_api=26&os_version=8.0.0&uuid=866089034995361&openudid=008c22ca20dd0de5&manifest_version_code=421&resolution=1080*1920&dpi=480&update_version_code=4212&_rticket=1548080824056&ts=1548080822&js_sdk_version=1.6.4&as=a1b51dc4069b2cc6252833&cp=dab7ca5f68594861e1[wIa&mas=014a70c81a9db218501e1433b04c38963ccccc1c4cac4c6cc6c64c')
运行后就可以得到视频列表:

有任何疑问,欢迎加我微信交流。
Python 爬虫——抖音App视频抓包的更多相关文章
- Python爬虫-抖音小视频-mitmproxy与Appium
目的: 爬取抖音小视频 工具: mitmproxy.Appium 思路: 1. 通过 mitmproxy 截取请求, 找出 response 为 video 的请求. 2. 通过 mitmdu ...
- from appium import webdriver 使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium)
使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium) - 北平吴彦祖 - 博客园 https://www.cnblogs.com/stevenshushu/p ...
- 使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium)
抖音很火,楼主使用python随机爬取抖音视频,并且无水印下载,人家都说天下没有爬不到的数据,so,楼主决定试试水,纯属技术爱好,分享给大家.. 1.楼主首先使用Fiddler4来抓取手机抖音app这 ...
- 教你用python爬取抖音app视频
记录一下如何用python爬取app数据,本文以爬取抖音视频app为例. 编程工具:pycharm app抓包工具:mitmproxy app自动化工具:appium 运行环境:windows10 思 ...
- python爬虫——抖音数据
最近挺火的抖音短视频,不仅带火了一众主播,连不少做电商的也进驻其中,于是今天我来扒一扒这火的不要不要的抖音数据: 一.抓包工具获取用户ID 对于手机app数据,抓包是最直接也是最常见的手段,常用的抓包 ...
- python爬虫抖音 个人资料 仅供学习参考 切勿用于商业
本文仅供学习参考 切勿用于商业 本次爬取使用fiddler+模拟器(下载抖音APP)+pycharm 1. 下载最新版本的fiddler(自行百度下载),以及相关配置 1.1.依次点击,菜单栏-Too ...
- python爬虫用drony转发进行抓包转发
转载至https://www.cnblogs.com/lulianqi/p/11380794.html#l_2 实际操作步骤(Android) 笔者这里直接使用上面提到第3种方法(方法1在对于手机AP ...
- python爬虫01在Chrome浏览器抓包
尽量不要用国产浏览器,很多是有后门的 chrome是首选 百度 按下F12 element标签下对应的HTML代码 点击Network,可以看到很多请求 HTTP请求的方式有好几种,GET,POST, ...
- python爬取抖音APP视频教程
本文讲述爬取抖音APP视频数据(本文未完,后面还有很多地方优化总结) 公众号回复:抖音 即可获取源码 1.APP抓包教程,需要用到fiddler fiddler配置和使用查看>>王者荣耀盒 ...
随机推荐
- Python +selenium自动化环境的搭建
Python +selenium+googledriver 小白的血泪安装使,不停的总结写心得是理解透彻的毕竟之路 一,python的安装: 首先去Python的官网下载安装包:https://www ...
- HTML5 CSS3 精美案例 : 实现VCD包装盒个性幻灯片
转载请标明出处:http://blog.csdn.net/lmj623565791/article/details/31015121 哈,首先感谢下w3cfuns的老师,嗯~ 好了,这次给发夹分享一个 ...
- poj~1236 Network of Schools 强连通入门题
一些学校连接到计算机网络.这些学校之间已经达成了协议: 每所学校都有一份分发软件的学校名单("接收学校"). 请注意,如果B在学校A的分发名单中,则A不一定出现在学校B的名单中您需 ...
- java某些基础知识点整理
1. \n换行 \r回车 \"双引号 \\反斜杠 2.Java语言提供了八种基本类型.六种数字类型(四个整数型,两个浮点型),一种字符类型,还有一种布尔型. byte: byte 数据类型是 ...
- 删除外部dwg中指定的块定义
本例实现删除外部图纸中指定的块定义,在外部图纸当前模型空间中是没有该块定义的块参照存在. 代码如下: void CBlockUtil::DeleteBlockDefFormOtherDwg(const ...
- jsp --- jquery
1 给标签 添加属性 $('#principalMoney').attr("disabled", false); $("#career1").css('dis ...
- 关于EffictiveC++笔记
我根据自己的理解,对原文的精华部分进行了提炼,并在一些难以理解的地方加上了自己的"可能比较准确"的「翻译」.
- 【STM32H7教程】第7章 STM32H7下载和调试方法(IAR8)
完整教程下载地址:http://forum.armfly.com/forum.php?mod=viewthread&tid=86980 第7章 STM32H7下载和调试方法(IAR8) 本 ...
- [Inside HotSpot] C1编译器HIR的构造
1. 简介 这篇文章可以说是Christian Wimmer硕士论文Linear Scan Register Allocation for the Java HotSpot™ Client Compi ...
- java游戏开发杂谈 - 事件处理
大家都知道,游戏需要跟玩家交互,需要接收玩家的鼠标.键盘发出的命令,比如在地图上点击一下,人物就自动寻路走过去:键盘上按下某个键,就弹出一个背包界面. 这些逻辑是怎么处理的呢? 大家先不用深究太详细的 ...