Java - 二叉树递归与非递归
二叉树是一种非常重要的数据结构,很多其它数据结构都是基于二叉树的基础演变而来的。对于二叉树,有前序、中序以及后序三种遍历方法。因为树的定义本身就是递归定义,因此采用递归的方法去实现树的三种遍历不仅容易理解而且代码很简洁。而对于树的遍历若采用非递归的方法,就要采用栈去模拟实现。在三种遍历中,前序和中序遍历的非递归算法都很容易实现,非递归后序遍历实现起来相对来说要难一点。
节点分布如下:
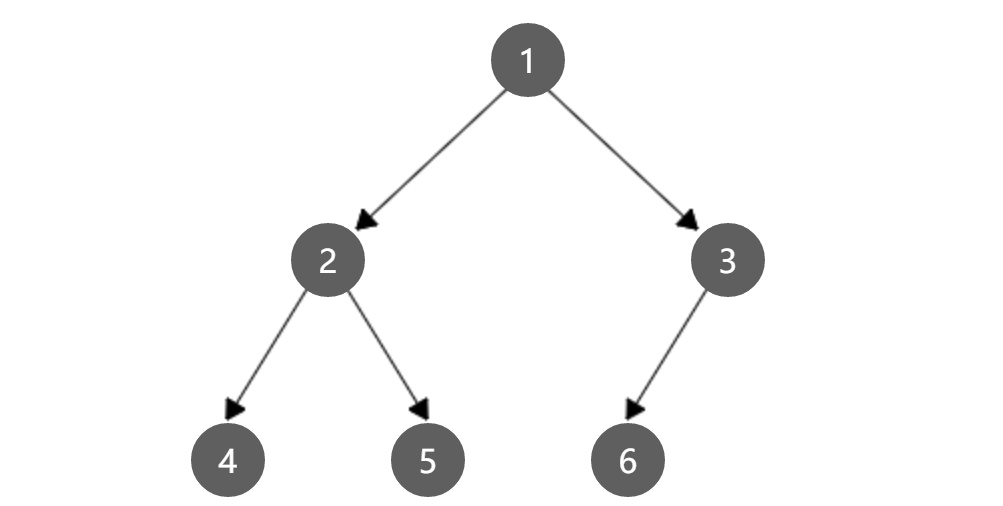
import java.util.LinkedList;
import java.util.Queue;
import java.util.Stack;
/**
* @author 李文浩
* @version 2017/7/30.
*/
public class BinaryTree {
/**
* 节点定义
*/
static class TreeNode {
int val;
TreeNode left;
TreeNode right;
TreeNode(int x) {
val = x;
}
}
/**
* 高度,左右子树中的较大值
*
* @param node
* @return
*/
public static int height(TreeNode node) {
if (node == null) {
return 0;
}
int leftHeight = height(node.left);
int rightHeight = height(node.right);
return leftHeight > rightHeight ? leftHeight + 1 : rightHeight + 1;
}
/**
* 层序遍历一颗二叉树,用广度优先搜索的思想,使用一个队列来按照层的顺序存放节点
* 先将根节点入队列,只要队列不为空,然后出队列,并访问,接着讲访问节点的左右子树依次入队列
*
* @param node
*/
public static void levelTraversal(TreeNode node) {
if (node == null)
return;
Queue<TreeNode> queue = new LinkedList<TreeNode>();
queue.offer(node);
TreeNode treeNode;
while (!queue.isEmpty()) {
treeNode = queue.poll();
System.out.print(treeNode.val + " ");
if (treeNode.left != null) {
queue.offer(treeNode.left);
}
if (treeNode.right != null) {
queue.offer(treeNode.right);
}
}
}
/**
* 先序递归
*
* @param treeNode
*/
public static void preOrder(TreeNode treeNode) {
if (treeNode != null) {
System.out.print(treeNode.val + " ");
preOrder(treeNode.left);
preOrder(treeNode.right);
}
}
/**
* 中序递归
*
* @param treeNode
*/
public static void inOrder(TreeNode treeNode) {
if (treeNode != null) {
inOrder(treeNode.left);
System.out.print(treeNode.val + " ");
inOrder(treeNode.right);
}
}
/**
* 后序递归
*
* @param treeNode
*/
public static void postOrder(TreeNode treeNode) {
if (treeNode != null) {
postOrder(treeNode.left);
postOrder(treeNode.right);
System.out.print(treeNode.val + " ");
}
}
/**
* 先序非递归:
* 这种实现类似于图的深度优先遍历(DFS)。
* 维护一个栈,将根节点入栈,然后只要栈不为空,出栈并访问,
* 接着依次将访问节点的右节点、左节点入栈。
* 这种方式应该是对先序遍历的一种特殊实现(看上去简单明了),
* 但是不具备很好的扩展性,在中序和后序方式中不适用
*
* @param root
*/
public static void preOrderStack(TreeNode root) {
Stack<TreeNode> stack = new Stack<>();
stack.push(root);
while (!stack.isEmpty()) {
TreeNode treeNode = stack.pop();
System.out.print(treeNode.val + " ");
if (treeNode.right != null) {
stack.push(treeNode.right);
}
if (treeNode.left != null) {
stack.push(treeNode.left);
}
}
}
/**
* 先序非递归2:
* 利用栈模拟递归过程实现循环先序遍历二叉树。
* 这种方式具备扩展性,它模拟递归的过程,将左子树点不断的压入栈,直到null,
* 然后处理栈顶节点的右子树。
*
* @param root
*/
public static void preOrderStack2(TreeNode root) {
Stack<TreeNode> stack = new Stack<>();
TreeNode treeNode = root;
while (treeNode != null || !stack.isEmpty()) {
//将左子树点不断的压入栈
while (treeNode != null) {
//先访问再入栈
System.out.print(treeNode.val + " ");
stack.push(treeNode);
treeNode = treeNode.left;
}
//出栈并处理右子树
if (!stack.isEmpty()) {
treeNode = stack.pop();
treeNode = treeNode.right;
}
}
}
/**
* 中序非递归:
* 利用栈模拟递归过程实现循环中序遍历二叉树。
* 思想和上面的先序非递归2相同,
* 只是访问的时间是在左子树都处理完直到null的时候出栈并访问。
*
* @param treeNode
*/
public static void inOrderStack(TreeNode treeNode) {
Stack<TreeNode> stack = new Stack<>();
while (treeNode != null || !stack.isEmpty()) {
while (treeNode != null) {
stack.push(treeNode);
treeNode = treeNode.left;
}
//左子树进栈完毕
if (!stack.isEmpty()) {
treeNode = stack.pop();
System.out.print(treeNode.val + " ");
treeNode = treeNode.right;
}
}
}
public static class TagNode {
TreeNode treeNode;
boolean isFirst;
}
/**
* 后序非递归:
* 后序遍历不同于先序和中序,它是要先处理完左右子树,
* 然后再处理根(回溯)。
* <p>
* <p>
* 对于任一结点P,将其入栈,然后沿其左子树一直往下搜索,直到搜索到没有左孩子的结点,
* 此时该结点出现在栈顶,但是此时不能将其出栈并访问,因此其右孩子还为被访问。
* 所以接下来按照相同的规则对其右子树进行相同的处理,当访问完其右孩子时,该结点又出现在栈顶,
* 此时可以将其出栈并访问。这样就保证了正确的访问顺序。
* 可以看出,在这个过程中,每个结点都两次出现在栈顶,只有在第二次出现在栈顶时,才能访问它。
* 因此需要多设置一个变量标识该结点是否是第一次出现在栈顶,这里是在树结构里面加一个标记,然后合成一个新的TagNode。
*
* @param treeNode
*/
public static void postOrderStack(TreeNode treeNode) {
Stack<TagNode> stack = new Stack<>();
TagNode tagNode;
while (treeNode != null || !stack.isEmpty()) {
//沿左子树一直往下搜索,直至出现没有左子树的结点
while (treeNode != null) {
tagNode = new TagNode();
tagNode.treeNode = treeNode;
tagNode.isFirst = true;
stack.push(tagNode);
treeNode = treeNode.left;
}
if (!stack.isEmpty()) {
tagNode = stack.pop();
//表示是第一次出现在栈顶
if (tagNode.isFirst == true) {
tagNode.isFirst = false;
stack.push(tagNode);
treeNode = tagNode.treeNode.right;
} else {
//第二次出现在栈顶
System.out.print(tagNode.treeNode.val + " ");
treeNode = null;
}
}
}
}
/**
* 后序非递归2:
* 要保证根结点在左孩子和右孩子访问之后才能访问,因此对于任一结点P,先将其入栈。如果P不存在左孩子和右孩子,则可以直接访问它;
* 或者P存在左孩子或者右孩子,但是其左孩子和右孩子都已被访问过了,则同样可以直接访问该结点。
* 若非上述两种情况,则将P的右孩子和左孩子依次入栈,这样就保证了每次取栈顶元素的时候,左孩子在右孩子前面被访问,
* 左孩子和右孩子都在根结点前面被访问。
*
* @param treeNode
*/
public static void postOrderStack2(TreeNode treeNode) {
Stack<TreeNode> stack = new Stack<>();
TreeNode currentTreeNode;
TreeNode preTreeNode = null;
stack.push(treeNode);
while (!stack.isEmpty()) {
currentTreeNode = stack.peek();
//如果当前结点没有孩子结点或者孩子节点都已被访问过
if ((currentTreeNode.left == null && currentTreeNode.right == null) ||
(preTreeNode != null && (preTreeNode == currentTreeNode.left || preTreeNode == currentTreeNode.right))) {
System.out.print(currentTreeNode.val + " ");
stack.pop();
preTreeNode = currentTreeNode;
} else {
if (currentTreeNode.right != null) {
stack.push(currentTreeNode.right);
}
if (currentTreeNode.left != null) {
stack.push(currentTreeNode.left);
}
}
}
}
}
参考文档
Java - 二叉树递归与非递归的更多相关文章
- 数据结构二叉树的递归与非递归遍历之java,javascript,php实现可编译(1)java
前一段时间,学习数据结构的各种算法,概念不难理解,只是被C++的指针给弄的犯糊涂,于是用java,web,javascript,分别去实现数据结构的各种算法. 二叉树的遍历,本分享只是以二叉树中的先序 ...
- 二叉树3种递归和非递归遍历(Java)
import java.util.Stack; //二叉树3种递归和非递归遍历(Java) public class Traverse { /******************一二进制树的定义*** ...
- JAVA递归、非递归遍历二叉树(转)
原文链接: JAVA递归.非递归遍历二叉树 import java.util.Stack; import java.util.HashMap; public class BinTree { priva ...
- C实现二叉树(模块化集成,遍历的递归与非递归实现)
C实现二叉树模块化集成 实验源码介绍(源代码的总体介绍):header.h : 头文件链栈,循环队列,二叉树的结构声明和相关函数的声明.LinkStack.c : 链栈的相关操作函数定义.Queue. ...
- java扫描文件夹下面的所有文件(递归与非递归实现)
java中扫描指定文件夹下面的所有文件扫描一个文件夹下面的所有文件,因为文件夹的层数没有限制可能多达几十层几百层,通常会采用两种方式来遍历指定文件夹下面的所有文件.递归方式非递归方式(采用队列或者栈实 ...
- 【Java】快速排序的非递归实现
快速排序一般采用递归方法(详见快速排序及其优化),但递归方法一般都可以用循环代替.本文实现了java版的非递归快速排序. 更多:数据结构与算法合集 思路分析 采用非递归的方法,首先要想到栈的使用,通过 ...
- 二叉树前中后/层次遍历的递归与非递归形式(c++)
/* 二叉树前中后/层次遍历的递归与非递归形式 */ //*************** void preOrder1(BinaryTreeNode* pRoot) { if(pRoot==NULL) ...
- 二叉树之AVL树的平衡实现(递归与非递归)
这篇文章用来复习AVL的平衡操作,分别会介绍其旋转操作的递归与非递归实现,但是最终带有插入示例的版本会以递归呈现. 下面这张图绘制了需要旋转操作的8种情况.(我要给做这张图的兄弟一个赞)后面会给出这八 ...
- AJPFX:递归与非递归之间的转化
在常规表达式求值中: 输入为四则运算表达式,仅由数字.+.-.*./ .(.) 组成,没有空格,要求求其值. 我们知道有运算等级,从左至右,括号里面的先运算,其次是* ./,再是+.- : 这样我们就 ...
- C语言实现 二分查找数组中的Key值(递归和非递归)
基本问题:使用二分查找的方式,对数组内的值进行匹配,如果成功,返回其下标,否则返回 -1.请使用递归和非递归两种方法说明. 非递归代码如下: #include <stdio.h> int ...
随机推荐
- Effecvtive Java Note
代码应该被重用,而不是被拷贝 同大多数学科一样,学习编程的艺术首先要学会基本的规则,然后才能知道什么时候可以打破这些规则 创建和销毁对象 1.考虑用静态工厂方法代替构造器. 优势:有名称.不必再每 ...
- C陷阱:求数组长度
// 这是一篇导入进来的旧博客,可能有时效性问题. 程序中,当我们建立了一个int型数组:int a[]={1,2,3,4,5,6};随后我们可能需要知道它的长度,此时可以用这种方法:length = ...
- DFS中的奇偶剪枝学习笔记
奇偶剪枝学习笔记 描述 编辑 现假设起点为(sx,sy),终点为(ex,ey),给定t步恰好走到终点, s | | | + — — — e 如图所示(“|”竖走,“—”横走,“+”转弯),易证abs( ...
- HDU 1013 Digital Roots【字符串,水】
Digital Roots Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)Tot ...
- 移动App,AJAX异步请求,实现简单的增、删、改、查
用ajax发异步请求时,要注意url."AppServer"为后台项目名,"LoginServlet.action"为web.xml中的<url-patt ...
- JAVA代码实现嵌套层级列表,POI导出嵌套层级列表
要实现POI导出EXCEL形如 --A1(LV1) ----B1(LV2) ----B2(LV2) ------C1(LV3) ------C2(LV3) ----B3(LV2) --A1(LV1)
- 大白话说Java泛型(二):深入理解通配符
文章首发于[博客园-陈树义],点击跳转到原文<大白话说Java泛型(二):深入理解通配符> 上篇文章<大白话说Java泛型(一):入门.原理.使用>,我们讲了泛型的产生缘由以及 ...
- mui 区域三级联动
<link href="../../css/mui.picker.css" rel="stylesheet" /><link href=&qu ...
- angular-dragon-drop.js 双向数据绑定拖拽的功能
在做公司后台物流的时候,涉及到34个省市分为两个部分,一部分为配送区域,另一部分为非配送区域,想利用拖拽的功能来实现,最好两部分的数组能自动更新. 刚好找到angular-dragon-drop.js ...
- SSM框架原理,作用及使用方法
---恢复内容开始--- 尊重原创:http://m.blog.csdn.net/dennis_wu_/article/details/73437097 作用: SSM框架是spring MVC ,s ...