论文笔记(8):BING: Binarized Normed Gradients for Objectness Estimation at 300fps
译文:
《基于二值化赋范梯度特征的一般对象估计》
摘要:
通过训练通用的对象估计方法来产生一组候选对象窗口,能够加速传统的滑动窗口对象检测方法。我们观察到一般对象都会有定义完好的封闭轮廓,而且通过将相关图像窗口重置为固定大小,就可以通过梯度幅值进行区分。基于以上的观察以及复杂度的考虑,为了明确训练方法,我们将窗口固定为8*8的,并将梯度幅值转化为一个简单的64维的特征来描述这个窗口。
我们进一步说明这个二值化赋范特性(BING),它可以很有效的用于一般对象估计。而且只需要一些原子操作(例如加法,按位移动等),我们使用的是PASCAL VOC 2007数据集,这是很有挑战性的,实验证明,我们的方法很高效的产生一系列类别独立,高分辨率的对象窗口,通过使用1000个建议窗口,我们的对象检测准确度达到96.2%。通过增加建议窗口的数量或者考虑颜色空间来计算BING特征,实验结果可以提高到99.5%。
1.引言
作为计算机视觉的一个重要领域,对象检测已经取得了巨大的进步。然而,大部分先进的检测器,需要为每一类设计特定的分类器,并且需要评估许多图像窗口【17,25】。为了减少分类器的检测窗口,训练通用类别的对象检测方法已经变得流行起来【2,3,21,22,48,49,57】。对象状态通常表示一个图像窗口包含任意类别对象的概率值。一个通用类别的检测方法可以很方便的用于改善预处理过程:1)减少了搜索空间;2)通过使用强分类器来提高检测准确度.然而,设计一个好的通用类别的方法是非常困难的,需要:
具备很好的检测率,找到所有前景对象;
提出一些建议,用于减少对象检测的计算时间;
达到很高的计算效率,很容易拓展到其他实时以及大规模的应用程序中;
具备很好的通用性,方便用于各个类别的检测器中,这样可以减少计算量
据我们所知,暂时还没有任何方法可以同时满足以上全部要求。
认知心理学以及神经生物学研究表明,人拥有强大的能力感知对象。通过对认知反应时间和信号在生物途径中的传输速度进行深入的研究和推理,形成了人类注意力理论假定,该假定认为人类视觉系统只详细处理图像的某些局部,而对图像的其余部分几乎视而不见,这也意味着,在识别对象之前,人类视觉系统中会有一些简单的机制来定位可能的对象。
本文中,我们提出了一个非常简单而且鲁棒性强的特征(BING),通过使用对象状态得分来协助检测对象。我们的动机来自于对象普遍是独立的,而且都具有很好定义的封闭轮廓【3,26,32】。我们观察到将图像归一化到一个相同的尺度(例如:8*8)上,一般对象的封闭轮廓和梯度范数之间具有强联系(见图1(C))。为了能够有效量化图像窗口中对象状态,我们将其重置大小为8*8,组合该窗口的像素梯度的幅值作为一个64位的特征,通过级联的支持向量机框架学习一个通用的对象检测方法。我们进一步说明这个二值化赋范特性(BING),它可以很有效的用于一般对象估计。而且只需要一些CPU原子操作(例如加法,按位移动等)。大部分现存的先进方法,一般采用复杂的分类特征,而且需要采用加速方法以至于计算时间是可控的,相对于此,BING特征是简单朴素的。
我们已经在PASCAL VOC2007数据集上,广义的评价了我们的方法。实验结果显示,我们的方法很有效(在一个简单的桌面CPU中达到300fps)地产生了一系列数据驱动,类别独立,高分辨的对象窗口,通过使用1000个窗口(约为整个滑动窗口的0.2%),检测率达到96.2%。使用5000个建议窗口以及3个不同的颜色空间,我们的方法可以达到99.5%。借鉴【3,22,48】,我们也核实了方法的通用性。我们训练了6个已知类别,然后在14个未知类别上进行测试,得到了很好的效果(图3)。相对于其他流行的方法,BING特征能够使我们达到更好的检测率,而且速率提高了1000多倍。实现了之前我们提到的关于一个好的检测器的要求。
2.相关工作
能够在识别一个对象之前察觉它,非常接近自底向上的视觉显著性。根据显著性定义,我们广义的将相关领域的研究分为三个类别:局部区域预测、显著性对象检测,对象状态建议。
局部区域检测: 该模型旨在预测人眼移动的显著点【4,37】。启发于神经生物学研究早期的视觉系统,Itti等人【36】提出了第一个用于显著性检测的计算模型,此模型利用了多尺度图像特征的中心-周围的差异。Ma和Zhang【42】 提出了另一种局部对比度分析方法来产生显著性图像,并用模糊增长模型对其进行扩展。Harel等人【29】提出了归一化中心分布特征来突出显著部分。 尽管几句局部区域检测模型以及取得了卓越的发展,但其倾向于在边缘部分产生高显著性值,而不是均匀地突出整个对象,因此,这种方法不适合用于对象检测。
显著性对象检测: 该模型旨在检测当前视野中最引人注意的对象,然后分割提取整个部分【5,40】。Liu等人【41】通过在CRF框架中引入局部,区域的,全局显著性测量。Achanta等人【1】提出了频率调谐方法。Cheng等人【11,14】提出了基于全局对比度分析和迭代图分割的显著性对象检测。更多的最新研究也试着基于过滤框架【46】产生一些高分辨的显著性图,采用一些效果比较好的数据【12】,或者是使用分层结构【55】。这些显著性对象分割在简单的情景图像分析【15,58】、内容感知编辑【13,56,60】中可以达到很好的效果。而且可以作为一个便宜的工具处理大规模的网络图像或者是通过自动筛选结果构建鲁棒性好的应用程序【7,8,16,31,34,35】。然而,这些方法很少能够运用于包含多对象的复杂图像,但现实生活中,这样的图片确实最有意义的。(例如:VOC【23】)
对象状态建议: 该方法并不做决定,而是提供一定数量(例如:1000)包含所有类别对象的窗口【3,22,48】。通过产生粗糙分割集【6,21】,作为对象状态建议已经被证实为一个减少分类器搜索空间的有效方式,而且可以采用强分类器提高准确率。然后,这两种方法计算量大,平均一张图片需要2-7分钟。Alexe等人【3】提出了一个线索综合性的方法来达到更好、更有效的预测效果。Zhang等人【57】采用方向梯度特征提出了一个级联的排序SVM方法。Uijlings等人【48】提出了一个可选择性的搜索方法老获得更好的预测效果。我们提出了一个简单直观的方法,相对于其他方法,达到了更好的检测效果,而且快于其他流行的方法1000多倍。
另外,对于一个有效的滑动窗口对象检测方法,保证计算量可控是非常重要的【43,51】。Lampert等人【39】提出了一个优雅的分支定界方法用于检测。但是,这些方法只能用于加速分类器,而且是用户已经提供了一个好的边框。一些其他有效的分类器【17】和近似核方法【43,51】也已经被提出。这些方法旨在减小估计单个窗口的计算量,自然也能结合对象性建议进而减小损失。
3.方法
启发于能够在识别对象之间感知它【20,38,47,54】的人类视觉系统,我们引入了一个64维的梯度幅值特征,二值化的梯度幅值特征(BING)很有效的获取到图像窗口的对象状态。
为了找到图像中的一般对象,我们扫描一个定义好的量化窗口(依据尺度或者是纵横比)。每一个窗口通过一个线性模型w ∈ R64获得得分
sl =<w,gl> (1)
l=(i,x,y) (2)
sl代表过滤器得分,gl代表NG特征,l表示坐标,i表示尺度,(x,y)表示窗口位置。运用非最大抑制(NMS),我们为每个尺度提供一些建议窗口。相对于其他窗口(例如:100*100),一些尺度(例如:10*500)的窗口包含对象的可能性是很小的。因此我们定义对象状态得分(校准过滤器得分):
ol = vi*sl+ti (3)
其中vi,ti∈ R,针对不同尺度i的窗口,得到不同的独立学习系数。使用校准函数(3)是非常快的,通常只需要在最终的建议窗口重排之后进行。
3.1 梯度幅值(NG)和对象状态
对象一般是具有很好定义封闭轮廓和中心的【3,26,32】。重置窗口的时候,就相当于将现实中的对象缩小到一个固定大小,因为在封闭的轮廓中,图像梯度变化很小,所以它是一个很好的可区分特征,就像是图1中,轮船和人在颜色,形状,纹理,光照等方面都有很大的不同,他们在梯度空间都存在共性。为了有效地利用观察结果,我们首先将输入图像重置为不同尺度的,在不同的尺度下计算梯度。然后再隔点取8*8大小的框,作为一个对应图像的64维的NG特征。
我们采用的NG特征,是一个密集的且紧凑的objectness特性,有以下几点优势:首先,由于归一化了支持域,所以无论对象窗口如何改变位置,尺度以及纵横比,它对应的NG特征基本不会改变。也就是说,NG特征是对于位置,尺度,纵横比是不敏感的,这一点是对于任意类别对象检测是很有用的。

图1 尽管对象(红色)和背景(绿色),在图像空间(a)呈现出了很大的不同,通过一个适当的尺度和纵横比,我们将其分别重置为固定大小(b),他们对应的NG特征(c)表现出很大的共性,基于NG特征,我们学习了一个简单的64D线性模型(d),用来筛选对象窗口。
这种不敏感的特性是一个好的对象检测方法应该具备的。第二,NG特征的紧凑性,使得计算和核实更加有效率,而且能够很好的应用在实时应用程序中。
NG特征的缺点就是识别能力不够。但一般而言,会采用检测器来最终缺点结果的误报率。第4部分,我们将展示实验结果,在很具有挑战的VOC2007数据集上,包含了96.2%的对象窗口。
3.2 objectness度量
为了对图像窗口进行学习,我们采用了两级级联SVM。
1.我们通过式(1)学习一个线性SVM[24]。采用包含前景对象的窗口和随机选择的简单背景窗口作为训练集的正负样本;
2.用上面得到的线性SVM学习vi,ti, 对不同的尺度i的训练图像我们通过式(1)进行估计,然后采用已选的窗口作为训练样例,计算过滤器得分作为一维特征,然后用训练图像注释来核实标记。
讨论:如图1,线性模型w与生物学上的灵长类动物的体系结构【27,38,54】的多尺度中心周围模式设定很类似,模型沿着边框区域具有更大的权重用来区分周围的背景。相对于手动设计中心周围模式【36】,我们的学习模型w能够获取到更加复杂也更加自然的前景。比如,低层面的对象相对于高层面的部分要更加阻塞。也就表示模型w中会给予低层次的对象更低的置信度。

3.3 二值化梯度幅值(BING)
为了能够利用二值化近似模型【28,59】中的优点,我们提出了一个NG特征的加速版,二值化梯度幅值,加速特征提取和测试过程。我们学习的线性模型w∈R64可以近似表示为一系列基向量的组合
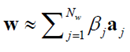
其中Nw表示基向量的个数,αj∈{-1,1}64表示基向量,βj∈R表示校准系数。αj可以进一步表示为二值向量和它的补:
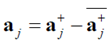 ,
, 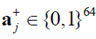
由α二值化之后得到的b可以被直接用于测试,而且只需要按位与和字节统计操作【28】
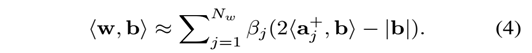
关键过程就是如何二值化以及有效的计算NG特征。我们近似采用梯度幅值(以及转化为01字节)的前Ng位来作二值化。

图2 变量说明:BING特征bx,y,它的最后一行是rx,y,最后一个元素bx,y。注意出现在式(2)和式(5)中的下标i, x, y, l, k,这些是定位整个向量而不是向量元素的索引。我们可以用一个简单的原子变量(INT64和BYTE)表示BING特征和它的最后一行,这样能够更有效的进行特征计算。
因此,64维 NG特征gl值可以通过前Ng位二值化梯度幅值(BING)近似表示
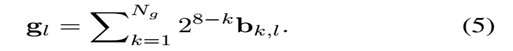
注意:这些BING特征拥有不同的权重,依据它原本不同的字节位。获取8*8的BING特征一般需要遍历64位,依据8*8 BING特征的两个特征,我们提出了一个快速的特征计算方法,能够只使用一些简单的原子操作(按位或和按位移动)避免循环计算。
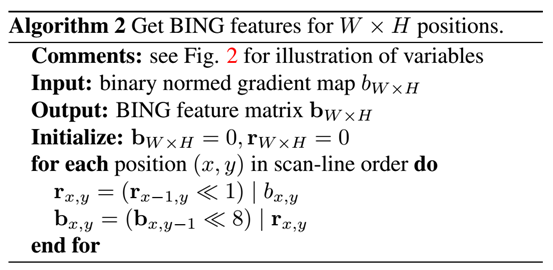
第一,BING特征bx,y以及它的最后一行rx,y可以存储在一个简单的INT64和一个BYTE变量中;第二,相邻的BING特征以及他们的行之间拥有一个简单的累积关系。如图2,将rx-1,y按位移动1位,这1位将自动进位到rx,y ,插入bx,y的过程可以用按位或来实现。同样,将bx-1,y按位移动8位,这8位将自动进位到bx,y ,自动插入rx,y。
我们的BING特征有效的利用了整体图像之间的累积性质【52】。与之前的方法在任意矩形范围内计算一些值不同的是,我们采用一些原子操作在一个固定8*8大小范围内计算一系列二进制模式。
一个图像窗口对应的BING特征bk,l的过滤器得分,见式(1),可以表示为:

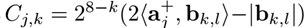
其中,Cj,k可以通过一些快速的按位操作以及SSE指令操作计算得到。
实现细节:我们使用一维的标识[-1,0,1],来定义水平方向和垂直方向上的图像梯度gx和gy,当计算梯度幅值是采用min(|gx|+|gy|,255),然后将其存入一个BYTE中。
4.实验评估
我们在VOC2007数据集上实验评估了我们的方法,使用的是DR和WIN的评估标准,与3个现存最先进的方法建议质量、通用性以及效率上做了对比。正如【3,48】,一系列高检测率的粗糙集对于有效对象检测是足够了的,,而且它允许使用复杂的特征和补充线索来得到比传统方法更好的质量和更高的效率。在对比试验中,我们采用的对应作者公布的实现方式和建议的参数设置。
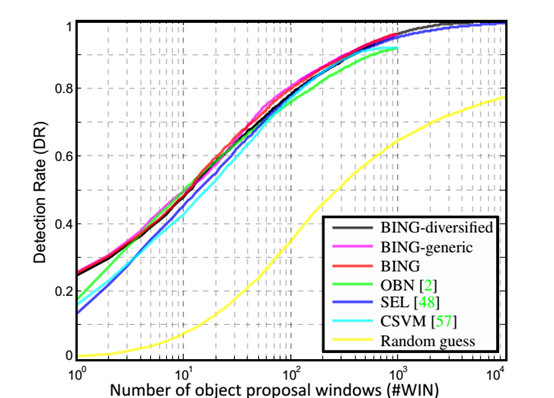
图3 不同方法关于#WIN和DR的权衡曲线。我们的方法使用1000建议窗口,达到了96.2%DR,使用5000个建议窗口可以达到99.5DR.其他三个方法我们采用了相同的评估标准,可以看出来优于一些其他的方法【6,21,25,30,50】,显著性测量【33,36】,特征点检测【44】以及HOG检测【17】.
建议质量对比:参照【3,48,57】,我们在数据集VOC2007上采用DR-WIN评估测试集,该数据集包含4952张20个类别的带有边框注释图像。数量巨大,种类繁多,视角、尺度、位置、阻塞、光照等都有不同,这些特点非常符合我们识别所有对象的要求。图3展示了数据统计对比,对比的方法有:OBN【3】,SEL【48】,以及CSVM【57】。正如【48】,通过收集不同参数设置下的结果,可以增加建议窗口的离散度,也能提高检测率DR,当然也需要提高建议窗口的数量(#WIN)。SEL【48】组合了80个不同参数设置的结果,达到了99.1%的DR和使用了10000多个建议窗口。我们的方法达到99.5%的DR,但只需要5000个建议窗口,而且仅仅收集了3个颜色空间的结果(RGB,HSV,GRAY)。如同DR-#WIN数据分析展示的那样,我们简单的方法在总体上达到了更好的效果,速率上比最流行的的方法【3,22,48】提升了3个数量级(见表格1),我们举例阐述了一些不同复杂度下的结果,如图4.
通用性测试:参照【3】,为了证明我们的方法具有通用性,采用包含未训练类别的对象图像进行测试。我们采用6个类别的对象训练我们的方法,通过剩下的14个类别进行测试。图3中,训练和测试是通过BING和BING-generic表示的。正如我们看到了那样,两个曲线基本一致,证明了我们方法的通用性。
最近的工作【18】能够在20秒内检测100000对象类别,主要采用的是减低传统多类别计算复杂度从O(LC)到O(L),L表示推荐窗口的数量,C表示分类器的数量。我们的方法可以得到任意类别(训练过的以及未训练的)的高质量的推荐窗口,可以通过减小L来显著减少计算复杂度。
计算时间:见表1,我们的方法可以在300fps的视频中,提供高效率的提供高质量的对象窗口,其他的方法对一张图片都需要几秒。这些方法通常是作为现存最先进的算法,而且很难大幅度的提升速度。我们在2501张图片上的训练需要很少的时间(包括加载XML文件,总共20S),而现有的先进的方法【6,21】测试一张图片通常需要多于2分钟.
如表2,通过采用二进制近似的方法学习线性过滤器和BING特征提取,计算每个图像窗口的得分只需要一些原子操作。
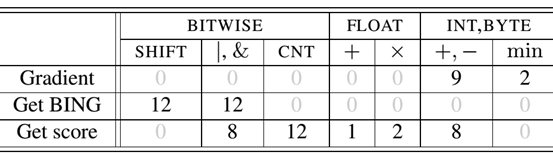
Table 2:在不同阶段,计算objectness所需要进行的原子操作数目:
计算梯度幅值,提取BING特征,获得objectness得分
在每个标准化的尺度和纵横比下,定位的数量相当于O(N),N代表图像中的像素数.因此,在所有尺寸和纵横比的图像中,计算得分的复杂度也是O(N)。在每一个潜在的位置上,提取BING特征和计算得分可以利用它邻近的2个位置(例如:左和上)。这意味着空间复杂度也是O(N)。我们在同一个Intel i7-3940XM CPU上,对比其他基准方法【3,2,,48,57】的运行时间。
如表3,我们可以进一步意识到,不同的近似对结果质量的影响,通过对比我们在其他试验中采用Nw=2,Ng=4.

Table 3:在不同近似层下的,平均检测结果(DR,使用1000个建议窗口),控制(Nw和Ng),N/A表示没有近似
图4在VOC2007上的真实的测试样例
5.结论以及将来的工作
我们呈现了一个非常简单,快速而且高质量的objectness方法,通过采用BING特征,计算任意尺度和纵横比的图像窗口中,我们仅仅需要一些原子操作(加,按位等)。通过最广泛的基准(VOC2007)和DR-#WIN评估标准进行结果评价,结果表明,与其他现存先进方法【3,22,48】相比,我们的方法不仅表现突出,而且速度上提升了3个数量级。
局限性: 与其他objectness方法【3,57】和滑动窗口【17,25】一样,我们都预测了一系列的对象矩形边框,因此,也有相似的局限性,对于一些类别的对象,一个矩形框并不能很好的集中实体,以便用来进行区域分割【6,21,33,45】,例如蛇。
进一步的工作:由于我们的方法具备高质量以及高效率的特性,所以它很适合实时多类别的对象检测和大规模图像收集应用程序(如:ImageNet【19】)。由于使用的简单的二进制操作,而且空间效率高,使得我们的方法可以在普通的设备上运行【28,59】。
我们的加速策略主要是减少窗口数量,这个可以通过其他的加速技术(通常旨在减少分类时间)来实现。将我们的方法和【18】的方法的进行组合将是很有趣的这样能够在一个机器上实时检测数以千计类别的对象。我们的方法解决了基于对象检测方法【53】的效率屏障,使得能够进行实时的高质量的对象检测。
通过使用简单的BING特征,我们能够使用一小部分(1000)的建议窗口得到涵盖几乎(96.2%)所有的对象区域。引入新的线索进一步降低建议窗口的数量,以便维持高效率的对象检测,以及在更多的应用程序【9】上使用BING特征,将是很值得研究的。
-------------------------------------------------------------------------------------------------------------------------------------------------------------------
该文算法思想:
考虑了我们人类观察事物的习惯:先粗看,再细看。BING就是提供一种”粗略检测“的方法,先将目标大概的位置提取出来,主要目的是为了提速,与edge boxes不同,BING是基于学习的,换句话说,我们如果将检测人体,就可以用大量的人体样本训练BING,使得BING专注于人体的检测,这是BING的一大优势所在!下面我们的描述都是基于人体检测。
BING的算法共分为两个阶段,并且两个阶段都是基于SVM的,第一个阶段,用SVM进行二分类,一类是人体,一类是非人体。第二阶段,由于检测出来的BING框框的大小不一,有的大有的小,比如说高10个像素,宽200个像素,是人体的可能性明显较低,作者采用了对各个框框加权重的方式,对框框内包含人体的可能性进行了排序。两个阶段都基于SVM,干脆直接称呼为cascade SVM。
该文算法流程:
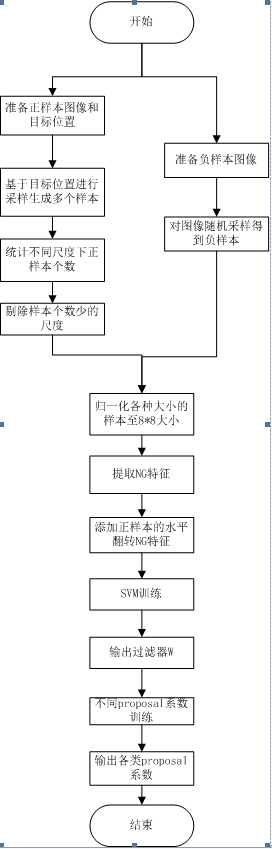

重点说说作者在代码里面的一个大招,在第一阶段,正样本是proposal真值,负样本是随机提取的非目标proposal,根据这两类样本得到的滤波器w,在第二阶段,作者没有沿用第一阶段得到的正负样本,而是又重新基于w过滤了每一幅图像,得到了一堆proposal(经过NMS处理过的),注意这个时候的proposal完全不知道类标哈,那怎么确定类标呢?方法是拿这些新proposal和第一阶段的真值propoals比较(重叠面积),然后将这些新proposal进行分类,以及计算各自对应的尺度和得分s,进一步,每个尺度都计算<v, t>。
该论文贡献了两个观点:
目标有closed boundary,因此将窗口resize到8x8也能进行目标和背景的识别,这实际上降低了窗口的分辨率,resize到8x8目的是加速计算。这就相当于我们看路上走的人一样,在很远的地方即使我们没看清楚脸,只是看到一个轮廓也能识别出是不是我们认识的人,反而,如果脸贴着脸去看一个人可能会认不出来。作者还使用了最简单的梯度特征,运算量非常小。
作者巧妙的将对窗口打分(分数越高,越可能是目标,否则越可能是背景)的计算转化为(或近似)通过位运算来实现,并以此为基础达到单幅图片的计算时间为0.003s。
窗口打分是通过一个线性模型来操作的(其实就是一个滤波器)。
为获得权值w,则必须通过训练数据训练,作者采用了最简单的Linear SVM,大致过程应该是:对训练用数据,目标窗和背景窗分别给定不同的分数(从程序上看,目标窗是1,背景窗是-1),训练数据经过Linear SVM调整w使训练数据的误差最小,得到调整w向量就用于预测中的窗口打分,打分越接进1的窗口为目标窗,否则为背景窗。
使用Linear SVM训练打分窗口的参数倒也没什么,重点在:窗口的预处理中考虑目标一般情况下“不会太小”,选择了一些固定的sliding window,如,10x160,10x320等,并且采取了降低窗口分辨率的方式,将窗口都resize到8x8,之后再进行窗口打分或训练w的操作。我对resize这种操作的理解是:虽然resize会降低前景与背景的差异,可能使前背景难以区分,但这种操作同时也减小了背景和背景之间、前景和前景之间的差异,但只要“背景和背景之间、前景和前景之间的差异”减小得比“前景与背景的差异”更多一些,则还是对区分前景和背景有利的,只不过应该可以找个折中,作者貌似为了计算的效率,直接resize到8x8了。所以(1)中的w和gl都是64维的向量。
既然得到了w,就能直接根据(1)计算窗口的分数,确定预测目标了,但作者没有简单的按(1)式做,而是将(1)的操作转化为位运算,这也是为什么特征称为BING(B就是Binarized),直接采用硬件指令大幅度地提升速度。为使用二进制运算,必须将w和gl都转成二进制的模型。Algorithm1就是将w转成二进制模型的算法,我感觉原理大致就是:将w在投影到不同的正交向量上,如果还不理解Algorithm1,好好看看算法是怎么操作的,那不就是“Gram-Schmidt正交化”吗?只不过只取了包含大部分信息的前Nw个正交向量作为输出,目的也是为了降低计算量。NG特征gl转成二进制模型。。?
大概的意思好像是,比如一个十进制的数121D,转成二进制就是0111 1001B,也可以直接将低位截断(这时Ng=3),用0111 1000近似代替121D。不过这里还是有些不明白,b_kl不是8x8维的特征吗?就不明白这里是什么意思了,矩阵求sum会得到标量的gl?感觉这一段下表用得有些混乱,没解释太清楚。而为了计算64维的BING特征,要扫描64个点,作者用Algorithm2也是通过二进制的移位运算降低计算量,就如作者原文所说的——有些类似于积分图像的计算一样(with the integral image representation)。
最后将算法1和2结合起来对窗口打分的操作由卷积运算变成了大部分是位运算操作,?
上面的计算很容易通过位运算和SSE指令(支持8x8=64bit)来完成快速运算。
论文笔记(8):BING: Binarized Normed Gradients for Objectness Estimation at 300fps的更多相关文章
- 【计算机视觉】BING: Binarized Normed Gradients for Objectness Estimation at 300fps
BING: Binarized Normed Gradients for Objectness Estimation at 300fps Ming-Ming Cheng, Ziming Zhang, ...
- Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现(转)
Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文, ...
- Deep Learning论文笔记之(八)Deep Learning最新综述
Deep Learning论文笔记之(八)Deep Learning最新综述 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文,但老感觉看完 ...
- 论文笔记之:Visual Tracking with Fully Convolutional Networks
论文笔记之:Visual Tracking with Fully Convolutional Networks ICCV 2015 CUHK 本文利用 FCN 来做跟踪问题,但开篇就提到并非将其看做 ...
- Twitter 新一代流处理利器——Heron 论文笔记之Heron架构
Twitter 新一代流处理利器--Heron 论文笔记之Heron架构 标签(空格分隔): Streaming-process realtime-process Heron Architecture ...
- Deep Learning论文笔记之(六)Multi-Stage多级架构分析
Deep Learning论文笔记之(六)Multi-Stage多级架构分析 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些 ...
- Multimodal —— 看图说话(Image Caption)任务的论文笔记(一)评价指标和NIC模型
看图说话(Image Caption)任务是结合CV和NLP两个领域的一种比较综合的任务,Image Caption模型的输入是一幅图像,输出是对该幅图像进行描述的一段文字.这项任务要求模型可以识别图 ...
- 论文笔记(1):Deep Learning.
论文笔记1:Deep Learning 2015年,深度学习三位大牛(Yann LeCun,Yoshua Bengio & Geoffrey Hinton),合作在Nature ...
- 论文笔记(2):A fast learning algorithm for deep belief nets.
论文笔记(2):A fast learning algorithm for deep belief nets. 这几天继续学习一篇论文,Hinton的A Fast Learning Algorithm ...
随机推荐
- mysql 在一个实例运行情况下再搭建一个实例
配置mysql服务 详细步骤,请参考(http://study.lishiming.net/chapter17.html#mysql), 阿铭只把简单步骤写一下. 根据阿铭提供的地址,假如你已经搭建好 ...
- Java面试题库及答案解析
1.面向对象编程(OOP)有哪些优点? 代码开发模块化,更易维护和修改. 代码复用. 增强代码的可靠性和灵活性. 增加代码的可理解性. 2.面向对象编程有哪些特性? 封装.继承.多态.抽象 封装 封装 ...
- 微信开发系列——微信订阅号前端开发利器:WeUI
前言:年前的两个星期,学习了下微信公众号的开发.后端基本能够基于盛派的第三方sdk能搞定大部分事宜.剩下的就是前端了,关于手机端的浏览器的兼容性,一直是博主的一块心病,因为博主一直专注于bootstr ...
- Ehcache入门基础
1.ehcache的简介 EhCache 是一个纯Java的进程内缓存框架,具有快速.精干等特点,是Hibernate中默认的CacheProvider. 2.ehcache入门实例 1.首先先导入 ...
- sqlsever 科学计数法 转标准值
一.解决方案 2e-005 转成 0.00002 update 表名 set 列名=cast(列名 as float) as decimal(19,5)) where 列名 like '%e%' 如 ...
- SpringMvc自动装配@Controller无效
1.问题原因:SpringMvc驱动器没有扫描该Controller层 虽然配置了 <!-- 启用spring mvc 注解 --> <context:annotation-conf ...
- Luogu P1092 虫食算
题目描述 所谓虫食算,就是原先的算式中有一部分被虫子啃掉了,需要我们根据剩下的数字来判定被啃掉的字母.来看一个简单的例子: 43#9865#045 +8468#6633 44445509678 其中# ...
- HighCharts之气泡图
HighCharts之气泡图 1.HighCharts之气泡图源码 bubble.html: <!DOCTYPE html> <html> <head> <m ...
- Flex读取txt文件中的内容(一)
Flex读取txt文件中的内容 phone.txt: 13000003847 13000003848 13000003849 13000003850 13000003851 13000003852 1 ...
- (三十一)java多线程二
因为线程在执行的过程中具有一定的不确定性,在并发的时候就会出现安全问题,因此一般需要采取一定的措施来保证线程的安全,同步代码块就是其中一种方式. 以下是模拟银行取钱的多线程小例子,两个都能确保安全,但 ...