LSTM实现中文文本情感分析
1. 背景介绍
文本情感分析是在文本分析领域的典型任务,实用价值很高。本模型是第一个上手实现的深度学习模型,目的是对深度学习做一个初步的了解,并入门深度学习在文本分析领域的应用。在进行模型的上手实现之前,已学习了吴恩达的机器学习和深度学习的课程,对理论有了一定的了解,感觉需要来动手实现一下了。github对应网址https://github.com/ble55ing/LSTM-Sentiment_analysis
LSTM(Long Short-Term Memory)是长短期记忆网络,在自然语言处理的领域有着较好的效果。因此本文使用LSTM网络来帮助进行文本情感分析。本文将从分词、向量化和模型训练三个方面对所训练的模型进行讲解,本文所实现的模型达到了在测试集99%的准确率。
2. 中文文本分词
首先需要得到两个文档,即积极情感的文本和消极情感的文本,作为训练用到的数据集,积极和消极的各8000条左右。然后程序在载入了这两个文本的内容后,需要进行一部分的预处理,而预处理部分中最关键的就是分词。
2.1 分词 or 分字
一般在中文文本的分词处理上,最常使用的就是jieba分词,因此在一开始训练模型的时候,也是使用的jieba分词。但后来感觉效果并不太好,最好的时候准确率也就达到92%,而且存在较为严重的过拟合问题(同时测试集准确率达到99%)。因此去和搞过一段时间的自然语言处理的大佬讨论了一下,大佬给出的建议是直接分字,因为所收集的训练集还是相对来说少了一点,分词完会导致训练集缩小,再进行embedding(数据降维)之后词表更小了,就不太方便获取文本间的内在联系。
因而最后分词时比较了直接分字和jieba分词的效果,最终相比之下还是直接分字的效果会更好一些(大佬就是大佬),所以选用了直接分字。直接分字的思路是将中文单字分为一个字,英文单词分为一个字。这里需要考虑到utf-8编码,从而正确的对文本进行分字。
2.2 去停用词
停用词:一些在文本中相对来说对语义的影响不明显的词,在分词的同时可以将这些停用词去掉,使得文本分类的效果更好。但同样的由于采集到的样本比较小的原因,在进行了尝试之后还是没有使用去停用词。因为虽然对语义的影响不大,但还是存在着一些情感在里头,这部分信息也有一定的意义。
2.3 utf-8编码的格式
utf-8的编码格式为:
如果该字符占用一个字节,那么第一个位为0。
如果该字符占用n个字节(4>=n>1),那么第一个字节的前n位为1,第n+1位为0。
也就是不会出现第一个字符的第一个字节为1,第二个字节为0的情况。
2.4 实现
#将中文分成一个一个的字
def onecut(doc):
#print len(doc),ord(doc[0])
#print doc[0]+doc[1]+doc[2]
ret = [];
i=0
while i < len(doc):
c=""
#utf-8的编码格式,小于128的为1个字符,n个字符的化第一个字符的前n+1个字符是1110
#print i,ord(doc[i])
if ord(doc[i])>=128 and ord(doc[i])<192:
print ord(doc[i])
assert 1==0#所以其实这里是不应该到达的
c = doc[i]+doc[i+1];
i=i+2
ret.append(c)
elif ord(doc[i])>=192 and ord(doc[i])<224:
c = doc[i] + doc[i + 1];
i = i + 2
ret.append(c)
elif ord(doc[i])>=224 and ord(doc[i])<240:
c = doc[i] + doc[i + 1] + doc[i + 2];
i = i + 3
ret.append(c)
elif ord(doc[i])>=240 and ord(doc[i])<248:
c = doc[i] + doc[i + 1] + doc[i + 2]+doc[i + 3];
i = i + 4
ret.append(c)
else :
assert ord(doc[i])<128
while ord(doc[i])<128:
c+=doc[i]
i+=1
if (i==len(doc)) :
break
if doc[i] is " ":
break;
elif doc[i] is ".":
break;
elif doc[i] is ";":
break;
ret.append(c)
return ret
3. 文本向量化
接下来是需要对分完字的文本进行向量化,这里使用到了word2Vec,一款文本向量化的常用工具。主要就是解决将语言文本处理成紧凑的向量。简单的文本转化往往是相当稀疏的矩阵,即One-Hot编码。转换的文本向量就是把文本中所含的词的编号的位置置为1.这样的编码方式显然是不适合进行深度学习模型训练的,因为数据过于离散了。因此,需要将向量维数进行缩减。word2Vec就能够较好的解决这个问题。
3.1 Word2Vec
Word2Vec能够将文本生成相对紧凑的向量,这个过程称为词嵌入(embedding),其本身也是一个神经网络模型。训练完成之后,就能够得到每个词所对应的低维向量了。使用这个低维向量来进行训练,能够达到较好的训练效果。
3.2 实现
def word2vec_train(X_Vec):
model_word = Word2Vec(size=voc_dim,
min_count=min_out,
window=window_size,
workers=cpu_count,
iter=5)
model_word.build_vocab(X_Vec)
model_word.train(X_Vec, total_examples=model_word.corpus_count, epochs=model_word.iter)
model_word.save('../model/Word2vec_model.pkl') input_dim = len(model_word.wv.vocab.keys()) + 1 #下标0空出来给不够10的字
embedding_weights = np.zeros((input_dim, voc_dim))
w2dic={}
for i in range(len(model_word.wv.vocab.keys())):
embedding_weights[i+1, :] = model_word [model_word.wv.vocab.keys()[i]]
w2dic[model_word.wv.vocab.keys()[i]]=i+1
return input_dim,embedding_weights,w2dic
4. 模型训练
4.1 激活函数
LSTM模型的训练,其激活函数选用了Softsign,是一个对于LSTM来说的时候比tanh更加合适的激活函数。
4.2 模型层数
在全连接层数的选取上,本来是使用了一层的全连接层,0.5的dropout,但在一开始的分词方式下,产生了较为严重的过拟合情况,因此就尝试着再添加一层Relu的全连接层,0.5的dropout,效果是确实可以解决过拟合的问题,但并没有提升准确率。因此就还是回到了一层全连接层的状况。相比之下,一层比两层的训练逼近速度快得多。
4.3 损失函数
损失函数的选取:这一部分尝试了三个损失函数,mse,hinge和binary_crossentropy,最终选用了binary_crossentropy。
mse这个损失函数相对普通,hingo和binary_crossentropy是较为专用于二分类问题的,而binary_crossentropy还往往与sigmoid作为激活函数一同使用。也可能是在使用hinge的时候没有用对激活函数吧。
4.4 评估标准
一开始的时候,评估标准定的是只有准确率(acc),然后准确率一直上不去。后来添加了平均绝对误差(mae,mean_absolute_error),准确率一下子就上去了,很有意思。
5. 总结
总的来说,自己搭模型调参的过程还是很必要的一个过程,内心很煎熬,没有自动调参的工具吗。。能够调出一个效果不错的模型还是很开心的。感觉在深度学习这块还是有很多的经验在里面,是需要花些时间的。
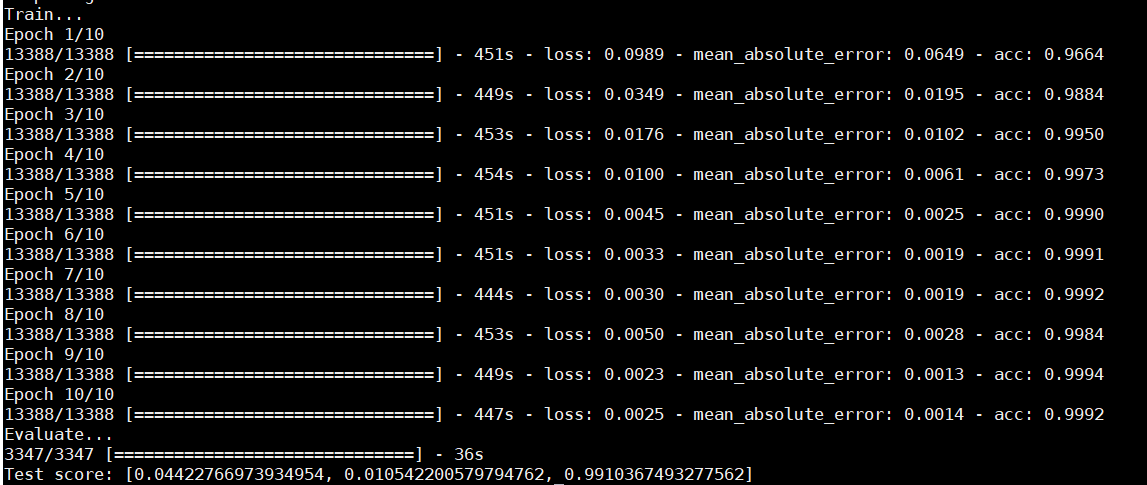
附上结果图一张。
LSTM实现中文文本情感分析的更多相关文章
- NLP入门(十)使用LSTM进行文本情感分析
情感分析简介 文本情感分析(Sentiment Analysis)是自然语言处理(NLP)方法中常见的应用,也是一个有趣的基本任务,尤其是以提炼文本情绪内容为目的的分类.它是对带有情感色彩的主观性 ...
- LSTM 文本情感分析/序列分类 Keras
LSTM 文本情感分析/序列分类 Keras 请参考 http://spaces.ac.cn/archives/3414/ neg.xls是这样的 pos.xls是这样的neg=pd.read_e ...
- 基于 Spark 的文本情感分析
转载自:https://www.ibm.com/developerworks/cn/cognitive/library/cc-1606-spark-seniment-analysis/index.ht ...
- TensorFlow实现文本情感分析详解
http://c.biancheng.net/view/1938.html 前面我们介绍了如何将卷积网络应用于图像.本节将把相似的想法应用于文本. 文本和图像有什么共同之处?乍一看很少.但是,如果将句 ...
- TensorFlow文本情感分析实现
TensorFlow文本情感分析实现 前面介绍了如何将卷积网络应用于图像.本文将把相似的想法应用于文本. 文本和图像有什么共同之处?乍一看很少.但是,如果将句子或文档表示为矩阵,则该矩阵与其中每个单元 ...
- 文本情感分析(二):基于word2vec、glove和fasttext词向量的文本表示
上一篇博客用词袋模型,包括词频矩阵.Tf-Idf矩阵.LSA和n-gram构造文本特征,做了Kaggle上的电影评论情感分类题. 这篇博客还是关于文本特征工程的,用词嵌入的方法来构造文本特征,也就是用 ...
- 文本情感分析(一):基于词袋模型(VSM、LSA、n-gram)的文本表示
现在自然语言处理用深度学习做的比较多,我还没试过用传统的监督学习方法做分类器,比如SVM.Xgboost.随机森林,来训练模型.因此,用Kaggle上经典的电影评论情感分析题,来学习如何用传统机器学习 ...
- 用python做文本情感分析
情感分析就是分析一句话说得是很主观还是客观描述,分析这句话表达的是积极的情绪还是消极的情绪.原理比如这么一句话:“这手机的画面极好,操作也比较流畅.不过拍照真的太烂了!系统也不好.” ① 情感词 要分 ...
- 【转】用python实现简单的文本情感分析
import jieba import numpy as np # 打开词典文件,返回列表 def open_dict(Dict='hahah',path = r'/Users/zhangzhengh ...
随机推荐
- FFmpeg and x264 Encoding Guide
https://trac.ffmpeg.org/wiki/Encode/H.264 FFmpeg and H.264 Encoding Guide Contents Constant Rate Fac ...
- Web运营手记
1.图片是给活人用户看的,相对来讲,文字是给搜索引擎看的.精华内容争取要在网站或者频道主页里面让人看到. 2.搜索引擎喜欢看的几种文字:页面标题.关键词元信息(只有Bing管点用).描述(descri ...
- Redis的Java使用入门
因项目需要,最近简单学习了redis的使用 redis在服务器centos环境下安装比较简单. 如果要在windows上安装,可以参考别人的文章 http://blog.csdn.net/renfuf ...
- nginx配置 location及rewrite规则详解
1. location正则写法 语法规则: location [=|~|~*|^~] /uri/ { … } = 开头表示精确匹配 ^~ 开头表示uri以某个常规字符串开头,理解为匹配 url ...
- CSS命名规则常用的css命名规则
CSS命名规则常用的css命名规则 头:header 内容:content/container 尾:footer 导航:nav 侧栏:sidebar 栏目:column 页面外围控制整体布局宽度:wr ...
- 洛谷 P1490 解题报告
P1490 买蛋糕 题目描述 野猫过生日,大家当然会送礼物了(咳咳,没送礼物的同志注意了哈!!),由于不知道送什么好,又考虑到实用性等其他问题,大家决定合伙给野猫买一个生日蛋糕.大家不知道最后要买的蛋 ...
- Python_替换当前目录下文件类型
''' 将当前目录的所有扩展名为html的文件重命名为扩展名为htm的文件 方法一 ''' import os file_list=os.listdir('.') for filename in fi ...
- Vue初学跳坑
1. uncaught TypeError: Cannot read property '0' of undefined <div class="home-module-wrap&qu ...
- mysql在ubuntu中的操作笔记(详)
1.安装mysql客户端流程: - 登录navicat官网下载 - 将压缩包拷贝ubuntu中进行解压,解压命令:tar zxvf navicat.tar.gz - 进入解压目录,运行命令./s ...
- Windows 安装 Vue
引言 在公司 linux 环境下安装不顺利,回家在 windows 下操作感觉到一种幸福 nginx 先安装了 nginx,其实跟 vue 没关系,只是打算用它做 web 服务,此处略过 nginx ...