YARN整理
YARN整理
1.YARN的介绍
是一个资源管理.任务调度的框架,主要包含三大模块:
ResourceManager(RM):负责所有资源的监控.分配和管理
ApplicationMaster(AM):负责每一个应用程序的调度和协调
NodeManager(NM):负责每一个节点维护
对于所有的applications,RM拥有绝对的控制权和资源的分配权.而每一个AM则会和RM协商资源.同时和NodeManager通信来执行和监控task.
2.YARN三大组件介绍
ResourceManager
ResourceManager 负责整个集群的资源管理和分配,是一个全局的资源管理系统。
NodeManager 以心跳的方式向 ResourceManager 汇报资源使用情况(目前主要是 CPU 和内存的使用情况)。RM 只接受 NM 的资源回报信息,对于具体的资源处理则交给 NM 自己处理
YARN Scheduler(调度器) 根据 application 的请求为其分配资源,不负责 application job 的监控、追踪、运行状态反馈、启动等工作。
NodeManager
NodeManager 是每个节点上的资源和任务管理器,它是管理这台机器的代理,负责该节点程序的运行,以及该节点资源的管理和监控。YARN 集群每个节点都运行一个NodeManager。
NodeManager 定时向 ResourceManager 汇报本节点资源(CPU、内存)的使用情况和Container 的运行状态。当 ResourceManager 宕机时 NodeManager 自动连接 RM 备用节点。
NodeManager 接收并处理来自 ApplicationMaster 的 Container 启动、停止等各种请求.
ApplicationMaster
用 户 提 交 的 每 个 应 用 程 序 均 包 含 一 个 ApplicationMaster , 它 可 以 运 行 在ResourceManager 以外的机器上。
负责与 RM 调度器协商以获取资源(用 Container 表示)。
将得到的任务进一步分配给内部的任务(资源的二次分配)。
与 NM 通信以启动/停止任务。
监控所有任务运行状态,并在任务运行失败时重新为任务申请资源以重启任务。
当前 YARN 自带了两个 ApplicationMaster 实现,一个是用于演示 AM 编写方法的实例程序 DistributedShell,它可以申请一定数目的 Container 以并行运行一个 Shell 命令或者 Shell 脚本;另一个是运行 MapReduce 应用程序的 AM—MRAppMaster。
RM 只负责监控 AM,并在 AM 运行失败时候启动它。RM 不负责 AM 内部任务的容错,任务的容错由 AM 完成。
3.YARN运行流程
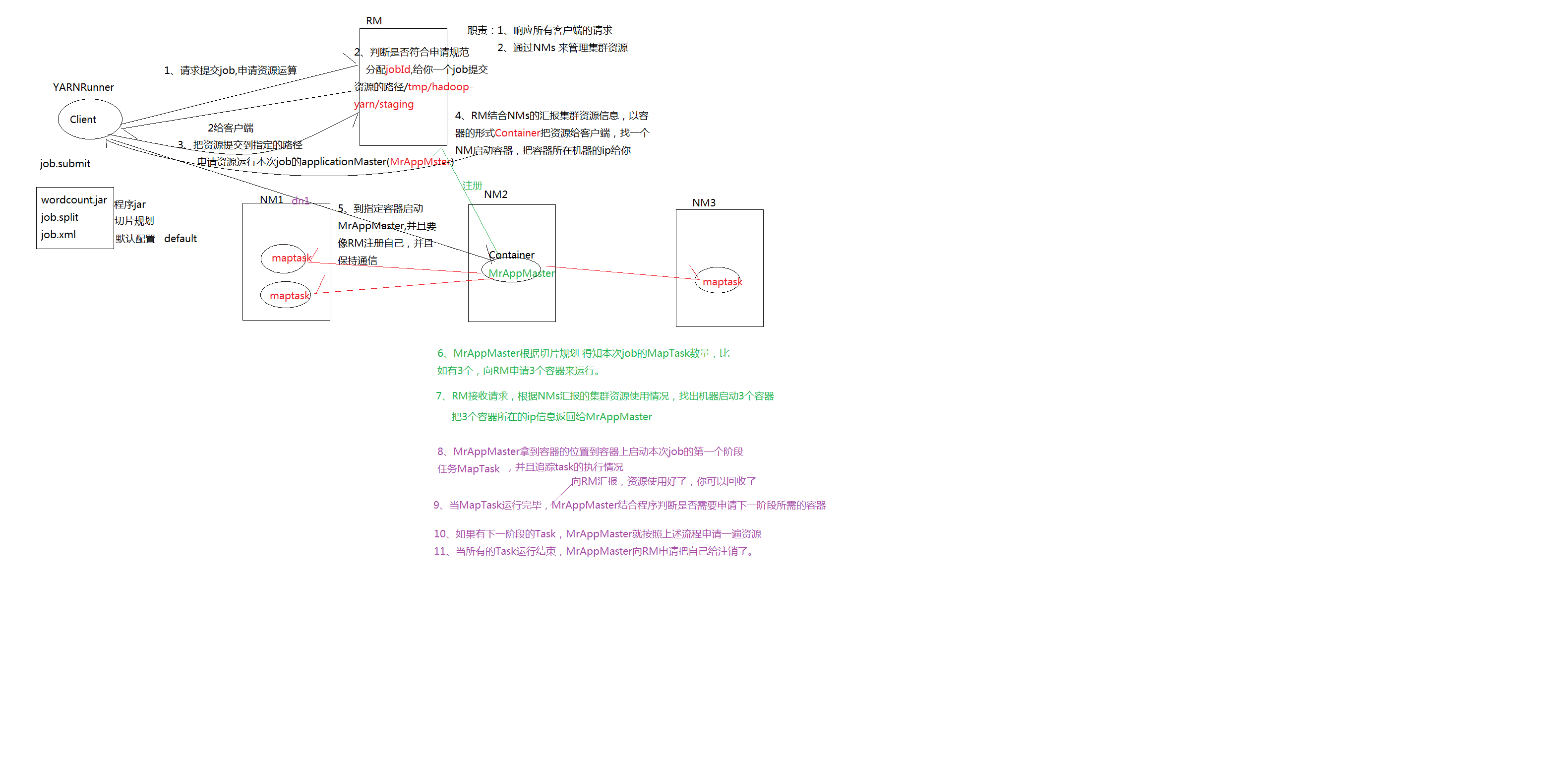

Client其实是一个类YARNRunner请求提交job申请资源运算
RM判断是否符合申请规范,分配jopid,给你一个路径job提交资源的路径mapred-default.xml:yarn.app.mapreduce.am.staging-dir:/tmp/hadoop-yarn/staging返回给客户端
客户端把job.submit:.jar程序,切片规划job.split,默认配置job.xml这些资源提交指定的路径,申请资源运行本次job的applicationMaster(MrAppMaster)
RM结合NMs的汇报集群资源信息,以容器的形式Container,把资源给客户端,找一个NM启动容器,把容器所在的ip给客户端
客户端到指定的容启动MrAppMater,并且要像RM注册自己,并且保持通信
MrAppMaster根据切片规则,得知本次job的MapTask数量,比如有三个,x向RM申请三个容器来运行
RM接收请求,根据NMs汇报集群资源使用情况,找出机器启动3个容器,把3个容器所在的ip信息返回给AppMaster
MrAppMaster拿到容器的位置到容器上启动本次job的第一个阶段任务MapTask,并且追踪task的执行情况,向RM汇报,资源使用好了.你可以回收了
当MapTask运行完毕,MrAppMaster结合程序是否需要申请下一阶段所需容器
当所有的task运行结束,MrAppMaster向RM申请把自己注销了.
4.YARN调度器Scheduler
理想的情况下,我们应用Yarn资源的请求应该立刻得到满足,但现实情况资源往往是有限的,特别是在一个很繁忙的集群,一个应用资源的请求经常需要等待一段时间才能得到相应的资源.在Yarn中,负责给应用分配资源的是Scheduler,其实调度本身就是一个难题,很难找到一个完美的策略,为此,Yarn提供了多种调度器和 可配置的策略供我们选择.
在Yarn中有三种调度器可以选择:FIFO Scheduler,Capacity Scheduler(默认调度器),Fair Scheduler.
1.FIFO Scheduler
FIFO Scheduler 把应用按照提交的顺序排成一个队列,这个是先进先出队列,在进行资源分配的时候,先给队列中最头上的应用进行分配资源,待最头上的应用需求满足后再给下一个分配,以此类推
FIFO Scheduler 是最简单也是最容易理解的调度器,也不需要任何配置,但它并不适用于共享集群。大的应用可能会占用所有集群资源,这就导致其它应用被阻塞。在共享集群中,更适合采用 Capacity Scheduler 或 Fair Scheduler,这两个调度器都允许大任务和小任务在提交的同时获得一定的系统资源。
2.Capacity Scheduler(默认调度器)
Capacity 调度器允许多个组织共享整个集群,每个组织可以获得集群的一部分计算能力。通过为每个组织分配专门的队列,然后再为每个队列分配一定的集群资源,这样整个集群就可以通过设置多个队列的方式给多个组织提供服务了。除此之外,队列内部又可以垂直划分,这样一个组织内部的多个成员就可以共享这个队列资源了,在一个队列内部,资源的调度是采用的是先进先出(FIFO)策略。
就是把整个集群资源分为n个队列,比如分为2个队列,一个大的队列和一个小的队列比例是8:2.比较大的应用走大的队列,小的队列走小的队列,但是队列内部还是用的FIFO,其实这样来一个比较大的应用还是阻塞,如果来的全是小应用都走小的队列,大队列就空了.资源就浪费了.
3.Fair Scheduler
在 Fair 调度器中,我们不需要预先占用一定的系统资源,Fair 调度器会为所有运行的job 动态的调整系统资源。如下图所示,当第一个大 job 提交时,只有这一个 job 在运行,此时它获得了所有集群资源;当第二个小任务提交后,Fair 调度器会分配一半资源给这个小任务,让这两个任务公平的共享集群资源。
需要注意的是,在下图 Fair 调度器中,从第二个任务提交到获得资源会有一定的延迟,因为它需要等待第一个任务释放占用的 Container。小任务执行完成之后也会释放自己占用的资源,大任务又获得了全部的系统资源。最终效果就是 Fair 调度器即得到了高的资源利用率又能保证小任务及时完成。
YARN整理的更多相关文章
- Spark on Yarn年度知识整理
大数据体系结构: Spark简介 Spark是整个BDAS的核心组件,是一个大数据分布式编程框架,不仅实现了MapReduce的算子map 函数和reduce函数及计算模型,还提供更为丰富的算子,如f ...
- Spark on yarn配置项说明与优化整理
配置于spark-default.conf 1. #spark.yarn.applicationMaster.waitTries 5 用于applicationMaster等待Spark maste ...
- Yarn上的几个问题整理
原文链接 http://xiguada.org/yarn_some_question/ 1. NodeManager是如何Kill掉Container的呢? 答,在DefaultConta ...
- 014 再次整理关于hadoop中yarn的原理及运行
一:对yarn的理解 1.关于yarn的组成 大约分成主要的四个. Resourcemanager,Nodemanager,Applicationmaster,container 2.Resource ...
- 大数据相关技术原理资料整理(hdfs, spark, hbase, kafka, zookeeper, redis, hive, flink, k8s, OpenTSDB, InfluxDB, yarn)
hdfs: hdfs官方文档 深入理解HDFS的架构和原理 https://blog.csdn.net/kezhong_wxl/article/details/76573901 HDFS原理解析(总体 ...
- (资源整理)带你入门Spark
一.Spark简介: 以下是百度百科对Spark的介绍: Spark 是一种与 Hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些有用的不同之处使 Spark 在某些工作负载方 ...
- Hadoop2.2.0--Hadoop Federation、Automatic HA、Yarn完全分布式集群结构
Hadoop有很多的上场时间,与系统上线.手头的事情略少.So,抓紧时间去通过一遍Hadoop2在下面Hadoop联盟(Federation).Hadoop2可用性(HA)及Yarn的全然分布式配置. ...
- GitHub上整理
GitHub上整理 技术站点 Hacker News:非常棒的针对编程的链接聚合网站 Programming reddit:同上 MSDN:微软相关的官方技术集中地,主要是文档类 infoq:企业级应 ...
- Hadoop Yarn框架原理解析
在说Hadoop Yarn的原理之前,我们先来看看Yarn是怎样出现的.在古老的Hadoop1.0中,MapReduce的JobTracker负责了太多的工作,包括资源调度,管理众多的TaskTrac ...
随机推荐
- javascript学习(1)用户的Javascript 放在哪里和函数的绑定方式
一.实验 1:js脚本放在那里最合适? 1.代码 1.1.test.html <!DOCTYPE html><html> <head> < ...
- ELK学习总结(1-1)ELK是什么
1.elk 是什么 ? Elastic Stack(旧称ELK Stack),是一种能够从任意数据源抽取数据,并实时对数据进行搜索.分析和可视化展现的数据分析框架.(hadoop同一个开发人员) ja ...
- Spring Security 入门(3-10)Spring Security 的四种使用方式
原文链接: http://www.360doc.com/content/14/0724/17/18637323_396779659.shtml 下面是作者的一个问题处理
- ssh整合之五struts和spring整合
1.首先,我们需要先分析一下,我们的spring容器在web环境中,只需要一份就可以了 另外,就是我们的spring容器,要在我们tomcat启动的时候就创建好了(包括其中的spring的对象),怎么 ...
- SVN (TortioseSVN) 版本控制之忽略路径(如bin、obj、gen)
在SVN版本控制时,新手经常会遇到这样的问题: 1.整个项目一起提交时会把bin . gen . .project 一同提交至服务器 2.避免提交编译.本地配置等文件在项目中单独对src.res进行提 ...
- keepalive配置支持ipv6、ipv4双棧支持
因公司业务需要,keepalived需要同时支持ipv6和ipv4 keepalived版本1.2.23. keepalived 配置: 重点:ipv6的虚IP配置在 virtual_ipaddres ...
- java集合小知识的复习
*Map接口 Map<k,v>接口中接收两个泛型,key和value的两个数据类型 Map中的集合中的元素都是成对存在的每个元素由键与值两部分组成,通过键可以找对所对应的值.值可以重复,键 ...
- AngularJS 全局scope与指令 scope通信
在项目开发时,全局scope 和 directive本地scope使用范围不够清晰,全局scope与directive本地scope通信掌握的不够透彻,这里对全局scope 和 directive本地 ...
- Java基础之关键字,标识符,变量
Java基础 首先,来看一下Java基础知识图解,以下便是在java学习中我们需要学习设计到的一些知识(当然不是很完全). 这些都是接下来在以后的学习中我们会学到的一些知识. 1 关键字 首次先来学习 ...
- jmc远程连接windows环境tomcat
新人报道,先发个小贴赚点人气,本人目前还是小菜鸟,想要飞却怎么也飞不高,哈哈,转到正题,最近发现这个JMC挺好用的,而且也不用像Jprofile需要破解,本地连接挺方便的, 但配置服务器确实挺坑的,按 ...