Python处理Excel生成CSV文档
Python是一种解释型的、动态数据类型的、面向对象的高级程序设计语言。拥有丰富的处理数据和文本类库,并且得益于它是一种解释型的语言,在程序修改和功能扩展上,可以很容易做到大规模的调整。综合考虑Python的动态、轻量化特性,使用Python来处理Excel自动生成CSV文档的操作。 程序的运行需要依赖两个Python的类库,Pandas和Xlrd。Pandas是Python的一个数据分析类库。Xlrd则是帮助开发人员从Microsoft的Excel操作数据的好帮手。
至于为什么要把Excel变成CSV就很简单了。由于CSV基于“,”符号切割字符串表单,因此,在程序上,读写访问非常方便。不需要导入厚重的Excel类库,只需要基于string数据结构就可以实现基本的表单管理。
一.Python和相关依赖库的配置步骤
1. 安装Python
请到Python官网下载并安装Python运行时:https://www.python.org/downloads/
2. 安装成功后,请打开Cmd控制台,输入如下命令安装Pandas
pip install pandas
3. 接着输入如下命令安装Xlrd
pip install xlrd
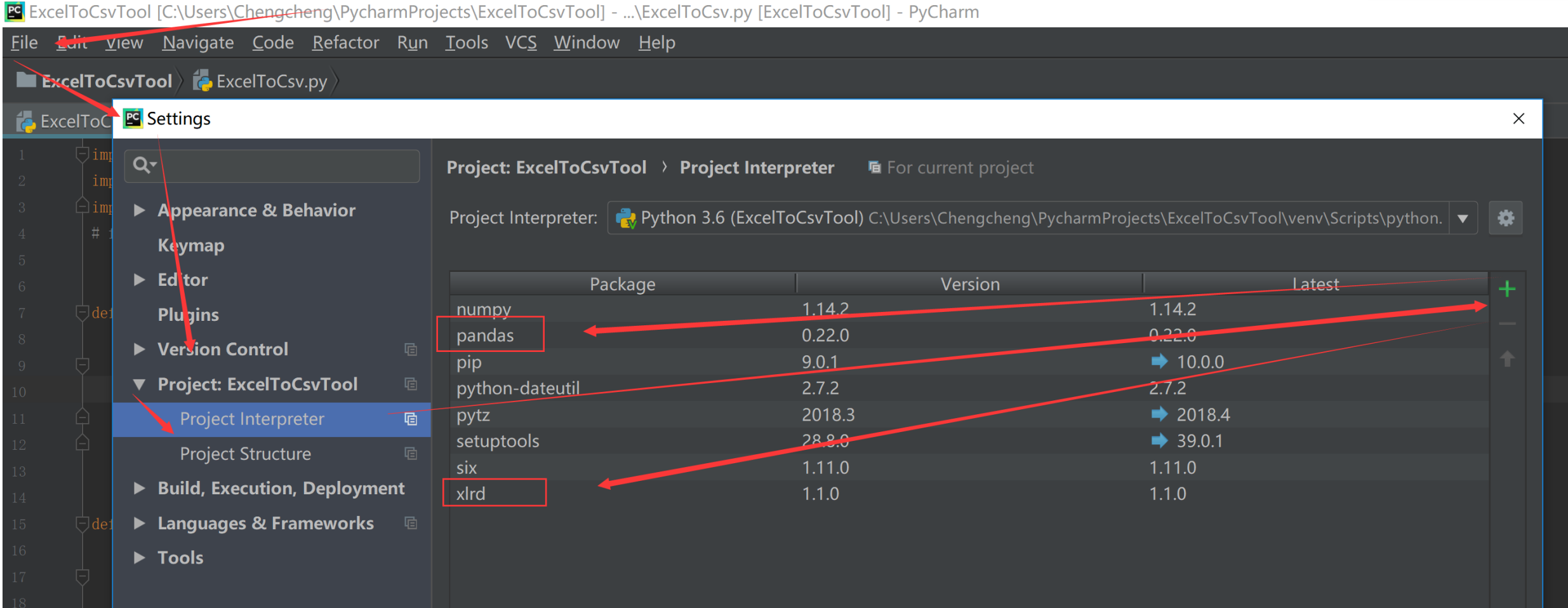
4. 如果你使用PyCharm,那么该工程的引用库安装导入方式如下:
File -> Settings -> Project: [current project name] -> ProjectInterpreter -> +(Add Button) -> 弹出的搜索框里分别依次选中Pandas和Xlrd。
二.转换实现
在开始编码前,我们思考一下转换的流程:
先收集所有的Excel文件 -> 遍历每一个Excel文件 -> Excel文件中还有众多的Sheet组成,也要遍历他们 -> 最终把Sheet为单位生成独立的CSV文件
那么接下来就是要研究那些API可以帮忙我们,如何获取目录文件集,如何打开excel文档,如何遍历sheet,如何保存成csv文档等等。这里就不流水账罗列过程了,直接贴出成品代码,下面的代码是上述思考过程的最终成品。最后,我们启动PyCharm运行脚本,显然当前脚本很好的搜索的指定的目录,并把所有表格的Sheet生成对应的CSV文档。
对了,代码里面我还留一个彩蛋,如何遍历所有的表格单元。这个,可以很好的帮你处理非法的单元格数据,关键的代码就是调用dataframe的applymap方法。代码中示例输入的方法是foreach_cell,该方法的本体是将nan的数据变成0。
另外,你还会发现,我用了xlrd获取sheet列表,但是我又另外使用pandas打开对应sheet。我之所以这样做,只是觉得pandas生成csv方便。所以,绕了点弯路。但是无大碍,一个转换代码而已,起码能利用各个优点(不是借口的借口吧)。Pandas有一个悲剧的地方就是不能获取Excel的Sheet总体情况,不传入指定的Sheet,默认打开的是第一个Sheet。
import os
import math
import xlrd
import pandas as pd def get_all_table_file_name(folder_path):
table_names = []
for file in os.listdir(folder_path):
if os.path.splitext(file)[1] == '.xls' or os.path.splitext(file)[1] == '.xlsx':
table_names.append(file)
return table_names def foreach_cell(cell):
if type(cell) is float and math.isnan(cell):
cell = 0
return cell def convert_table_to_csv(folder_path, file_name):
file_path = folder_path + '/' + file_name
print('开始转换Excel文档: ' + file_path + ' 成 CSV 文档') tables = xlrd.open_workbook(file_path)
print('..Sheet总数: ' + tables.nsheets.__str__()) for sheet_table in tables.sheets():
csv_file_name = file_name.replace('.xlsx', '')
csv_file_name = csv_file_name.replace('.xls', '')
output_path = 'output/' + csv_file_name + sheet_table.name + ".csv" sheet = pd.read_excel(file_path, sheet_table.name, index_col=None, index=False)
sheet.columns = sheet.columns.str.replace('Unnamed.*', '')
sheet.applymap(foreach_cell)
sheet.to_csv(output_path, encoding='utf-8', index=False)
print('....已经生成 ' + csv_file_name + sheet_table.name + ' CSV文档') def convert_all_tables_to_csv(folder_paths):
for folder_path in folder_paths:
table_files = get_all_table_file_name(folder_path)
for table_file in table_files:
convert_table_to_csv(folder_path, table_file) scan_folders = ['.', 'tables']
convert_all_tables_to_csv(scan_folders)

作者:雨天
地址:http://www.cnblogs.com/HelloGalaxy/p/8863436.html
Python处理Excel生成CSV文档的更多相关文章
- Python 处理EXCEL的CSV文档分列求SUM
相对于导出EXCEL文件,PYTHON计算更为实时. import csv import sys from optparse import OptionParser def calculate_pro ...
- python 3.7 生成数据库文档
开发阶段数据库总是有变动,开发人员需要维护文档给相关人员使用,故编写一个脚本自动生成数据库文档 生成的excel如下 import cx_Oracle import os from openpyxl ...
- Python处理Excel和PDF文档
一.使用Python操作Excel Python来操作Excel文档以及如何利用Python语言的函数和表达式操纵Excel文档中的数据. 虽然微软公司本身提供了一些函数,我们可以使用这些函数操作Ex ...
- 利用sphinx为python项目生成API文档
sphinx可以根据python的注释生成可以查找的api文档,简单记录了下步骤 1:安装 pip install -U Sphinx 2:在需要生成文档的.py文件目录下执行sphinx-apido ...
- python快速生成注释文档的方法
python快速生成注释文档的方法 今天将告诉大家一个简单平时只要注意的小细节,就可以轻松生成注释文档,也可以检查我们写的类方法引用名称是否重复有问题等.一看别人专业的大牛们写的文档多牛多羡慕,不用担 ...
- 使用C#动态生成Word文档/Excel文档的程序测试通过后,部署到IIS服务器上,不能正常使用的问题解决方案
使用C#动态生成Word文档/Excel文档的程序功能调试.测试通过后,部署到服务器上,不能正常使用的问题解决方案: 原因: 可能asp.net程序或iis访问excel组件时权限不够(Ps:Syst ...
- Python sphinx-build在Windows系统中生成Html文档
看到前同事发布的“Markdown/reST 文档发布流水线”基于TFS.Docker.Azure等工具和平台进行文档发布的介绍说明,不得不在心中暗暗竖起大拇指.这套模式,实现了文档编写后版本管理.发 ...
- 使用sphinx快速为你python注释生成API文档
sphinx简介sphinx是一种基于Python的文档工具,它可以令人轻松的撰写出清晰且优美的文档,由Georg Brandl在BSD许可证下开发.新版的Python3文档就是由sphinx生成的, ...
- JSP生成WORD文档,EXCEL文档及PDF文档的方法
转自:https://www.jb51.net/article/73528.htm 本文实例讲述了JSP生成WORD文档,EXCEL文档及PDF文档的方法.分享给大家供大家参考,具体如下: 在web- ...
随机推荐
- Python OJ 从入门到入门基础练习 10 题
1.天天向上的力量: 一年365天,以第1天的能力值为基数,记为1.0.当好好学习时,能力值相比前一天提高N‰:当没有学习时,由于遗忘等原因能力值相比前一天下降N‰.每天努力或放任,一年下来的能力值相 ...
- linux --> Makefile编写
Makefile编写 单目录 测试程序在同一个文件中,共有func.h.func.c.main.c三个文件,Makefile写法如下所示: CC = gcc CFLAGS = -g -Wall mai ...
- 小米官网的css3导航菜单
HTML代码: <div class="nav"> <ul> <li><a href="#">首页</a& ...
- Maven学习笔记一
maven是apache下的一个开源项目,是纯java开发,并且只是用来管理java项目的. Maven好处 1.普通的传统项目,包含jar包,占用空间很大.而Maven项目不包含jar包,所以占用空 ...
- 《团队-手机app便签-开发文档》
项目托管平台地址:https://github.com/Vcandoit/Notepad.git 我主要负责文件存储部分,文字部分使用sqlite保存. 因为我们想实现备忘录记录照片.语音的功能,所以 ...
- Socket程序从windows移植到linux下需要注意的
)头文件 windows下winsock.h或winsock2.h linux下netinet/in.h(大部分都在这儿),unistd.h(close函数在这儿),sys/socket.h(在in. ...
- GNU/Hurd笔记整理
patch 0 关于文件锁支持的解决方案,大部分是由Neal Walfield在2001年完成的.这些补丁由Marcus Brinkmann发表,随后被Michael Banck于2002年修改了部分 ...
- 再议Python协程——从yield到asyncio
协程,英文名Coroutine.前面介绍Python的多线程,以及用多线程实现并发(参见这篇文章[浅析Python多线程]),今天介绍的协程也是常用的并发手段.本篇主要内容包含:协程的基本概念.协程库 ...
- pdf解析与结构化提取
#PDF解析与结构化提取##PDF解析对于PDF文档,我们选择用PDFMiner对其进行解析,得到文本.###PDFMinerPDFMiner使用了一种称作lazy parsing的策略,只在需要的时 ...
- ArrayList源码学习----JDK1.7
什么是ArrayList? ArrayList是存储一组数据的集合,底层也是基于数组的方式实现,实际上也是对数组元素的增删改查:它的主要特点是: 有序:(基于数组实现) 随机访问速度快:(进行随机访问 ...