基于Cloudera Search设计数据灾备方案
当实际项目上线到生产环境中,难以避免一些意外情况,如数据丢失、服务器停机等。对于系统的搜索服务来说,当遇到停机的情况意味着在停机这段时间内,用户都不能通过搜索的相关功能进行访问数据,停机意味着将这一段时间内的数据服务完全停止。如果项目是互联网项目依赖于用户数量,这将严重影响用户访问和用户的产品体验。
针对于这种实际情况,在实际的项目开发维护过程中,如果系统使用的大数据平台是Cloudera公司是CDH,可以考虑使用Cloudera Search来进行数据的增量备份和数据恢复工作。Cloudera Search是Cloudera公司基于Apache的开源项目Solr发布的一个搜索服务,安装非常简单,通过Cloudera Manager的管理页面就可以进行一键式安装,本文将对使用Cloudera Search进行各个应用场景做灾备的方案一一介绍。
1.HDFS - HDFS
一般情况下,一个大数据项目中所有用到的原始数据都会存储HDFS中(Hive和HBase存储也是基于HDFS存储数据)。对HDFS做灾备和数据恢复最直接的方式是在源HDFS集群和备份HDFS集群之间设置数据定期增量更新,例如时间Cloudera BDR工具,基础数据备份之后可以选择使用MapReduce Indexer或者Spark Indexer对备份HDFS集群中的同步过来的原始数据建立索引并追加到和备份HDFS集群同一集群中的正常运行的Solr服务中。这样在原始集群故障后,可以从原始集群的Solr服务切换到备份集群的Solr服务,从而达到不影响用户使用搜索服务的需求。
这种情况存在一个问题就是我的原始集群中数据有新产生的数据,还没来得及同步到备份HDFS集群中,这时发生原始集群发生故障会切换到备用集群会导致数据缺失,导致这种情况有两个方面的原因,一是设置的在两个集群间增量同步数据的传输频率,这也是主要因素。二是使用MapReduce或者Spark建立索引并加到Solr中需要多久的时间。
下图是一个具体的例子,文件A存储在HDFS中,通过Cloudera BDR工具进行数据文件的定期备份,将它备份到数据备份用的HDFS集群中。在两个集群中使用Spark或者MapReduce对新文件建立索引,并将新建立的索引添加到各自集群中的Solr服务里提供搜索功能。
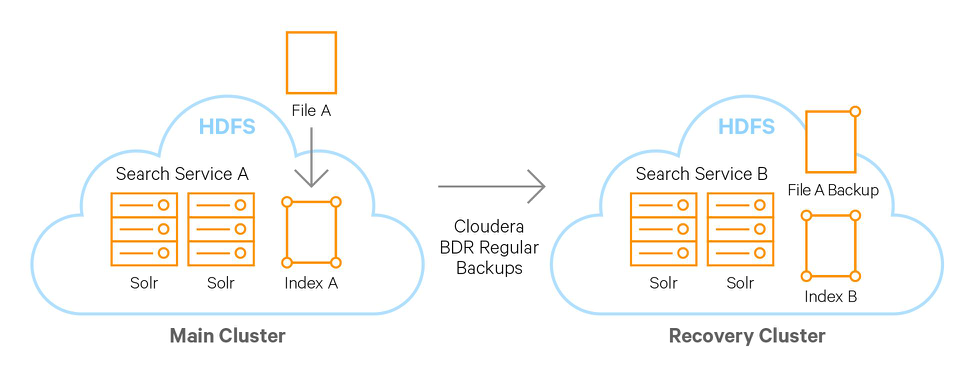
图1
2.HBase - HBase
如果数据存储在HBase表中,并且希望可以对这些数据进行搜索,这种场景使用Solr集成HBase,可以实现大数据量快速检索,替代HBase中的列值过滤器,并且HBase在Rowkey设计中也会更加容易,只需要保证每一行的唯一性就可以。
从灾备的角度来看,HBase本身就具备将数据备份到恢复集群的能力,所以对搜索HBase的搜索服务需要做的就是及时同步数据到恢复集群,并在恢复集群的Solr服务上建立索引。HBase集群间的数据同步取决于两个HBase集群之间的网络。
用户每次写入到HBase的数据同步到HBase恢复集群(可以使用HBase自带的hbase.replication配置项实现),集成使用Cloudera Search和同集群Solr服务实时监听建立索引的机制相同。同理在HBase恢复集群也需要实时监听数据变换,为新数据建立索引,可以采用HBase协处理器或者Cloudera的Key-Value Store Indexer组件实现。
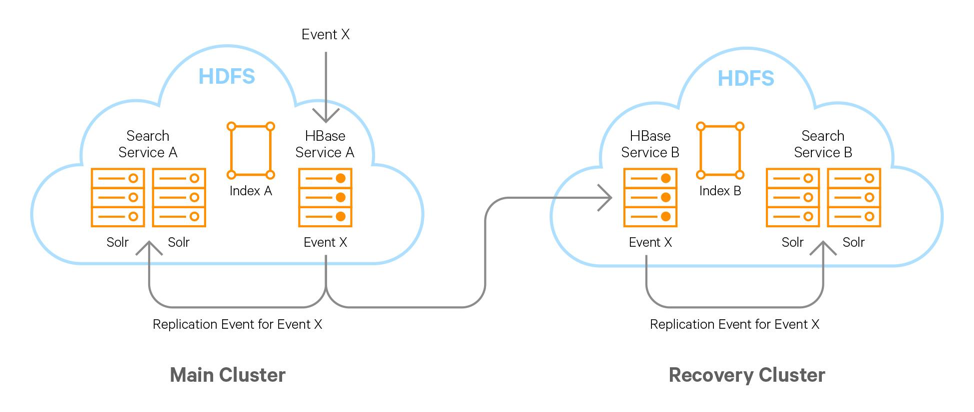
图 2
3.Solr - Solr
搜索服务灾备一方面是对基础数据进行同步和备份,一方面则是对索引进行备份,Cloudera Search 实现了索引备份的方案,使用索引备份工具可以高效的将索引文件复制到其他位置,例如S3或ADLS,但是在做灾备的场景下,你的恢复集群很可能是一个HDFS集群,在需要切换备用集群时,需要将索引加载到备用集群的Cloudera Search 服务中。只要索引文件加载到了Solr中,就可以为用户提供搜索服务。
备份的操作是基于Solr的快照功能,Cloudera Search允许为当前Solr中的所有数据做快照。之后使用hadoop distcp命令将索引和相关的元数据文件复制到别处(其他的HDFS集群)。
由于创建快照是对数据和元数据的保留,可能不是完整的副本,因此在这种情况下两个集群数据同步的延迟取决于备用集群上的可以Solr服务需要多长时间将索引副本加载到集群的Cloudera Search服务中。
总结来说备份Solr数据的步骤如下:
a) 原始集群创建快照
b) 准备要导出的快照
c) 将快照导出到本地集群或者远程集群(hadoop distcp命令)
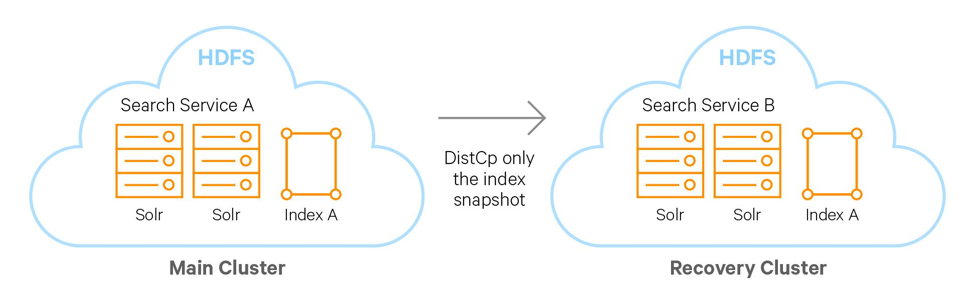
图 3
个人建议:
项目上线后建议定期进行系统的基础数据备份和索引数据备份。原始数据计算使用过后建议全量保留,这是为了避免后续想要更改数据计算方式却没有原始数据的情况。
基于Cloudera Search设计数据灾备方案的更多相关文章
- 理解 OpenStack 高可用(HA)(1):OpenStack 高可用和灾备方案 [OpenStack HA and DR]
本系列会分析OpenStack 的高可用性(HA)概念和解决方案: (1)OpenStack 高可用方案概述 (2)Neutron L3 Agent HA - VRRP (虚拟路由冗余协议) (3)N ...
- 如何守护数据安全? 这里有一份RDS灾备方案为你支招
当今世界是一个充满着数据的互联网世界,生活的方方面面都在不断产生着数据,比如出行记录.消费记录.浏览的网页.发送的消息等等.除了文本类型的数据,图像.音乐.声音都是数据.对于企业而言,数据更是重要的生 ...
- openStack灾备方案说明
本系列会分析OpenStack 的高可用性(HA)概念和解决方案: (1) OpenStack 高可用方案概述 (2) Neutron L3 Agent HA - VRRP (虚拟路由冗余协议) (3 ...
- openStack高可用性和灾备方案
1. 基础知识 1.1 高可用 (High Availability,简称 HA) 高可用性是指提供在本地系统单个组件故障情况下,能继续访问应用的能力,无论这个故障是业务流程.物理设施.IT软/硬件的 ...
- DataGuard VS Beedup & GoldenGate灾备方案参数对比
世上本无完美产品,只有合适的才是最好的! 用户重视灾备数据站点的建设,毋庸置疑必备品.如果考虑带宽及事务完整性保证,存储灾备和操作系统级灾备局限性显而易见. 商用价值一般用于解决数据库自带辅助功能的短 ...
- 基于Ceph快照的异地灾备设计
作者:吴香伟 发表于 2017/02/06 版权声明:可以任意转载,转载时务必以超链接形式标明文章原始出处和作者信息以及版权声明 喜欢请点击右边打赏,谢谢支持! 引子 技术改变生活. 越来越方便的手机 ...
- SqlServer灾备方案(本地)
如果你曾经有那么一个不经意的心跳来自于数据库数据损坏:错误的新增.更新.删除 .那么下面的方案一定能抚平你的创伤! 对于一个数据库小白来说,数据库的任何闪失带来的打击可说都是致命的.最初,我们让一个叫 ...
- Oracle Dataguard HA (主备,灾备)方案部署调试
包括: centos6.5 oracle11gR2 DataGuard安装 dataGuard 主备switchover角色切换 数据同步测试 <一,>DG数据库数据同步测试1,正常启动主 ...
- NOS跨分区灾备设计与实现
本文来自网易云社区 作者:王健 摘要 NOS(网易对象存储)在实现多机房(杭州机房,北京机房等)部署后,允许一个用户在建桶时选择桶所属机房.在此基础上,我们实现了跨机房的数据复制,进一步实现了跨机房的 ...
随机推荐
- gitlab6 nginx配置和启动脚本
gitlab6 nginx配置和启动脚本 cheungmine 2013-10 最近把gitlab安装到了ubuntu12.04.3的虚拟机上了.参考: https://github.com/gitl ...
- linux的date的几个例子
shell脚本为test.sh: input=$1 echo "sdfa:${input}" echo ${input} echo "dfadf"${input ...
- Socket编程实践(7) --Socket-Class封装(改进版v2)
本篇博客定义一套用于TCP通信比较实用/好用Socket类库(运用C++封装的思想,将socket API尽量封装的好用与实用), 从开发出Socket库的第一个版本以来, 作者不知道做了多少改进, ...
- 【一天一道LeetCode】#67. Add Binary
一天一道LeetCode 本系列文章已全部上传至我的github,地址:ZeeCoder's Github 欢迎大家关注我的新浪微博,我的新浪微博 欢迎转载,转载请注明出处 (一)题目 Given t ...
- MinerQueue.java 访问队列
MinerQueue.java 访问队列 package com.iteye.injavawetrust.miner; import java.util.HashSet; import java.ut ...
- 【Android 应用开发】GitHub 优秀的 Android 开源项目
原文地址为http://www.trinea.cn/android/android-open-source-projects-view/,作者Trinea 主要介绍那些不错个性化的View,包括Lis ...
- java 多线程和线程池
● 多线程 多线程的概念很好理解就是多条线程同时存在,但要用好多线程确不容易,涉及到多线程间通信,多线程共用一个资源等诸多问题. 使用多线程的优缺点: 优点: 1)适当的提高程序的执行效率(多个线程同 ...
- 【Java编程】Java基本数据类型
在较前面的一篇博文<C/C++基本数据类型>中,我主要介绍了c/c++的基本数据类型.我们知道C语言没有具体规定各类数据类型所占内存的字节数,只要求long型数据长度不小于int型,sho ...
- Android Data Binding语法解析(二)
上篇我们知道了Data Binding的最简单的用法,那么Data Binding其中最为重要也是最复杂的其实就是在xml布局文件中给对应的控件进行数据绑定了,接下来就一一说明Data Binding ...
- Jamon
1.Jamon java 模版引擎 eclipse 插件 http://www.jamon.org/eclipse/updates 2.Jamon 官方网站 http://www.jamon.or ...